Finding Significant Differences in Flyway SQL Migration Code
This article demonstrates using PowerShell-based tokenization to compare two SQL migration files. It ignores non-functional changes like comments or formatting and pinpoints the first meaningful change in SQL logic, providing detailed feedback on its location and nature.
What caused the Flyway validation error?
A Flyway migration will fail with a validation error if one of the files has been altered since it was applied to the database. Flyway issues these ‘warnings’ because retrospective file changes can be problematic for several reasons. They can cause version inconsistency, where two copies of the same database, with the same Flyway schema version, are functionally different. Even minor changes intended to improve performance rather than functionally alter the code can have unintended consequences. They can cause errors in subsequent unaltered migration scripts that ran successfully, and they can cause difficulties when database branches are merged.
There are, on the other hand, some good and harmless changes you can make to a migration that has been successfully applied that will also cause Flyway validation errors. The formatting of the SQL may need to be changed to conform to team standards and to promote readability. The migration code is also the only sensible place to put the block comments and the end-of-line comments that explain the code. These ‘comments’ can always be improved, because one often needs to wade through migration code to determine what the developer intended to do.
When we’re responding to a validation error, scanning through code to work out what changed, we need an easy way to identify functional changes amidst formatting and documentation improvements. My previous article, Defusing Flyway Validation Errors using Smarter Checksum Comparisons used PowerShell-based tokenization to calculate a checksum of “just the code”, after excluding tokens for whitespace, formatting and comments. If a Flyway validation error was caused by retrospective cosmetic changes, developers could simply run Flyway Repair and move on, with minimal disruption to development and testing.
However, if the changes are not just cosmetic but rather edits to the SQL logic, then we can’t just “run repair and move on“. We need to investigate exactly what changed and why, so we can decide how best to handle it. This article builds on the concepts from my previous article. We use the same tokenization method but instead of just calculating a checksum, we compare the stream of code-only tokens (such as ‘select‘,’*‘, ‘from‘, ‘MySchema‘, ‘.‘, ‘MyTable‘), one by one, to identify exactly where in a script the first of the functional changes were made.
How does Flyway do the validation check?
When Flyway does a migration or executes the Validate command, it will access the database to read the Flyway Schema History table in the database you’ve specified (see The Flyway Migrate Command Explained Simply). It ascertains from it the current schema version of this database. It then it reads and sorts the migration files and validates any that were already applied. To do this, it uses the checksums of these files. The table stored the checksums that were calculated when the file was successfully applied, and so it then accesses each file, recalculating these checksums and compares the new checksum with the original to make sure no aspect of the previously applied migration sequence has been subsequently changed: no files have been subsequently altered, no new files injected into the previous sequence (see Flyway’s Validate Command Explained Simply).
When a Flyway raises a ‘checksum mismatch’ validation error, you can just smile indulgently and run my Get-SQLCodeHash function to see if the changes are purely decorative. It calculates a “metadata only” checksum for the ‘before’ and ‘after’ code. If they match, the changes are most likely a kind-hearted and conscientious reformatting or commenting of the file, and you can go ahead with a flyway repair. This allows Flyway to recalculate the stored checksum in the database’s flyway schema history table so that normal migrations can proceed.
If, however, the tokenized checksums still don’t match, then there is a change in the SQL, and you need to investigate. This is where this article comes in.
Why not just use source control and a differencing tool?
You can do very little beyond shrugging or looking bewildered when faced with a Flyway validation failure if you don’t have a copy of the version of the file that was used for the successful migration. We will assume that you do have, in your source control system, a copy of the previous version of the migration file, so why not use its built-in file comparison tool, or a specialist tool like Beyond Compare, to see what changed?
The problem is that this sort of comparison is purely text-based rather than semantic, so you are back to a process that can produce plenty of false positives, especially with reformatting and changed documentation. A file that has been commented, formatted and documented will be wildly different textually, yet contain the same SQL. See that sea of red? It is distracted by cosmetic changes. The SQL hasn’t changed, but it’ll take a while to detect that.
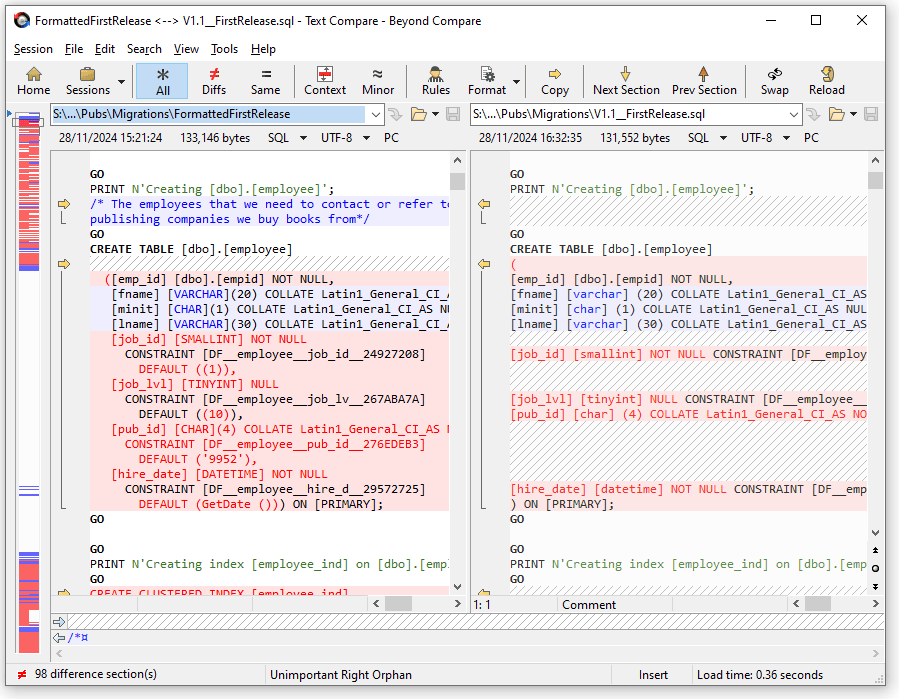
The script I’ll provide in this article, by contrast, does SQL-specific analysis. It does a token-by-token comparison highlighting differences in keywords, operators, or structure, while ignoring any changes due to comments or whitespace. It alerts you to the first semantic difference.
C’mon: show us the code!
OK! All the scripts are on GitHub in my Flyway Teamwork repository, which I know you all read. The Compare-SQLTokens cmdlet processes the original (source) and changed (target) code using a regex ($parserRegex) to extract the text of all the SQL tokens by category, such as BlockComment, EndOfLineComment, String, Identifier, Operator, and so on. Cosmetic categories of tokens such as comments are then filtered out leaving just the text of the meaningful tokens.
It uses the same tokenizer as used by the Get-SQLCodeHash cmdlet from the previous article. However, where that function just calculated and compared checksums for the ‘metadata only’ code, Compare-SQLTokens extracts the tokens from the source and target SQL files by comparing each token in sequence. The first time the token in the source doesn’t match the corresponding token in the target, the function calculates the exact line number and column where the difference occurs. It also retrieves nearby tokens for context.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 |
<# .SYNOPSIS Find out if the SQL Tokens in two different blocks of SQL Code match .DESCRIPTION Take two blocks of SQL Code- which can be formatted differently and have all sort of comments or case differences, and see if the actual SQL is the same or not. A warning if a difference .PARAMETER SourceString The source version of the SQL Code. .PARAMETER TargetString The target version of the SQL Code that you want to compare the source with. .EXAMPLE Compare-SQLTokens @' /* Complex update with case and subquery */ UPDATE Inventory SET StockLevel = CASE WHEN StockLevel < 10 THEN StockLevel + 5 ELSE (SELECT AVG(StockLevel) FROM Inventory WHERE CategoryID = Inventory.CategoryID) END WHERE ProductID = 101; '@ @' UPDATE Inventory SET Stocklevel = CASE --Alter Stocklevel Of Low Items WHEN Stocklevel < 10 THEN Stocklevel + 5 ELSE (SELECT Avg (Stocklevel) FROM Inventory WHERE Categoryid = Inventory.Categoryid) END WHERE Productid = 101; '@ #> function Compare-SQLTokens { [CmdletBinding()] param ( [Parameter(Mandatory = $true)] [string]$SourceString, [Parameter(Mandatory = $true)] [string]$TargetString ) #The regex string will check for the major SQL Components $parserRegex = [regex]@' (?i)(?s)(?<BlockComment>/\*.*?\*/)|(?# )(?<EndOfLineComment>--[^\n\r]*)|(?# )(?<String>N?'.*?')|(?# )(?<number>[+\-]?\d+\.?\d{0,100}[+\-0-9E]{0,6})|(?# )(?<SquareBracketed>\[.{1,255}?\])|(?# )(?<Quoted>".{1,255}?")|(?# )(?<Identifier>[@]?[\p{N}\p{L}_][\p{L}\p{N}@$#_]{0,127})|(?# )(?<Operator><>|<=>|>=|<=|==|=|!=|!|<<|>>|<|>|\|\||\||&&|&|-|\+|\*(?!/)|/(?!\*)|\%|~|\^|\?)|(?# )(?<Punctuation>[^\w\s\r\n]) '@ $LineRegex = [regex]'(\r\n|\r|\n)'; $exceptions = @(0, 'BlockComment', 'EndOfLineComment') #things we want to ignore $Source = $parserRegex.Matches($SourceString) | Foreach { $index = $_.index; $_.Groups } | foreach { if ($_.success -eq $true -and $_.name -ne 0 -and $_.name -notIn $exceptions) { @{ 'Index' = $index; 'token' = "$($_.Value.ToLower())" }; } } $Target = $parserRegex.Matches($TargetString) | Foreach { $index = $_.index; $_.Groups } | foreach { if ($_.success -eq $true -and $_.name -ne 0 -and $_.name -notIn $exceptions) { @{ 'Index' = $index; 'token' = "$($_.Value.ToLower())" }; } } 0..([math]::Max($Source.Count, $Target.count) - 1) | foreach -begin { $context = @('', '') } { if ($Source[$_].token -ne $Target[$_].token) { #we have detected an anomaly #we need to get the line and column number as well as the index $Lines = $Lineregex.Matches($TargetString); #get the offset where lines start $Theline = 1; $TheIndex = $Target[$_].Index; While ($lines.count -ge $TheLine -and #do we bump the line number $lines[$TheLine - 1].Index -lt $TheIndex) { $Theline++ } $TheStart = switch ($Theline) { ({ $PSItem -le 2 }) { 0 } Default { $lines[$TheLine - 2].Index } } $TheColumn = $TheIndex - $TheStart; #retrieve the context - the three tokens before the difference if possible $Context = ([math]::max(0, ($_ - 3)))..$_ | foreach { "$($Target[$_].token)" } $CodeSectionStart=[math]::max(0,($TheIndex-20)) $Codelength=[math]::min(30,$TargetString.length-$CodeSectionStart) $section = $TargetString.Substring($CodeSectionStart,$Codelength) Write-warning "At line $TheLine, column $($TheColumn): $( )'$context' - '$($Target[$_].token)' is different to $( )'$($source[$_].token)' in the code `"'...$section...`".No further search attempted.." continue; } } } |
Trying it out: detecting where a SQL change occurred
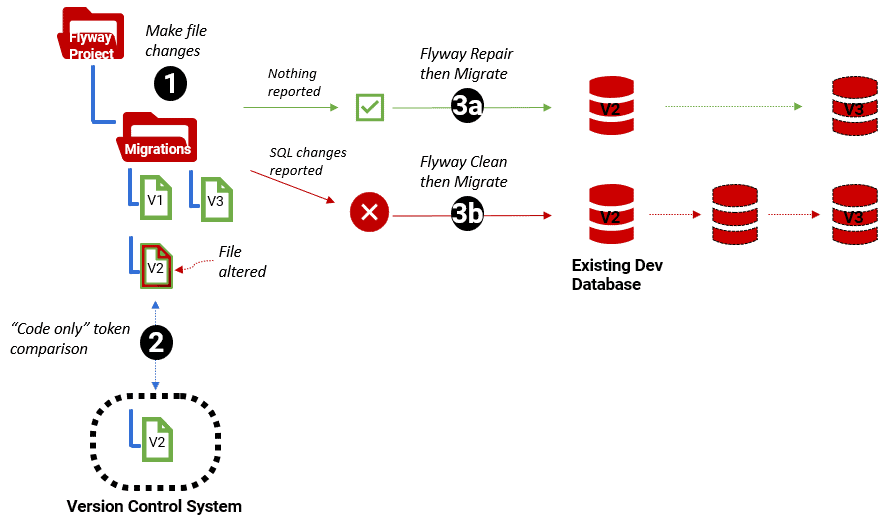
It is sometimes very useful to detect a SQL change in a file, using a script like this, before applying a migration, especially when working within a development team. Based on the result, you can go straight to the workflow that can approve the change via Flyway repair, or redo all migrations via Flyway clean, or condemn the change entirely without attempting a migration.
Together with Get-SQLCodeHash, the intent is to make it easier for developers to manage justifiable changes in Flyway migration scripts, by giving them notifications instead of nasty surprises within team-based development.
Comparing SQL Expressions
First, we’ll use Compare-SQLTokens to compare two SQL Expressions that, apart from formatting differences, contain just one small change to the Stocklevel logic.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
Compare-SQLTokens @' /* Complex update with case and subquery */ UPDATE Inventory SET StockLevel = CASE WHEN StockLevel < 10 THEN StockLevel + 5 ELSE (SELECT AVG(StockLevel) FROM Inventory WHERE CategoryID = Inventory.CategoryID) END WHERE ProductID = 101; '@ @' UPDATE Inventory SET Stocklevel = CASE --Alter Stocklevel Of Low Items WHEN Stocklevel < 10 THEN Stocklevel + 4 ELSE (SELECT Avg (Stocklevel) FROM Inventory WHERE Categoryid = Inventory.Categoryid) END WHERE Productid = 101; '@ |
It picks out the change immediately with a warning:
WARNING: At line 4, column 49: 'then stocklevel + 4' - '4' is different to '5' in the code "'...0 THEN Stocklevel + 4
...".No further search attempted..
Comparing Flyway migration files
Now let’s try it out on ‘before’ and ‘after’ versions of the same Flyway migration file:
|
1 2 3 4 |
Compare-SQLTokens ` (Type "$env:FlywayWorkPath\Pubs\Migrations\FormattedFirstRelease" -Raw) ` (Type "$env:FlywayWorkPath\Pubs\Migrations\V1.1__FirstRelease.sql" -Raw) #Nothing returned. All OK. |
Nothing returned means that there are only cosmetic differences, which are whitespace changes in this case. So, let’s sneakily make a single, subtle change. Nothing drastic or easily detectable:
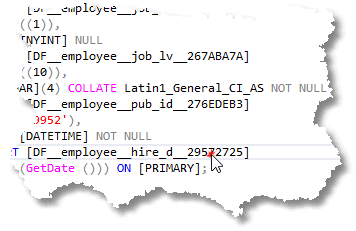
We’ll change that 7 to a 6 (heh heh). That is a change that could be embarrassing if not spotted. Now we rerun the comparison.
|
1 2 3 |
PS C:\Users\Phil> Compare-SQLTokens ` (Type "$env:FlywayWorkPath\Pubs\Migrations\FormattedFirstReleaseWithChange" -Raw) ` (Type "$env:FlywayWorkPath\Pubs\Migrations\V1.1__FirstRelease.sql" -Raw) |
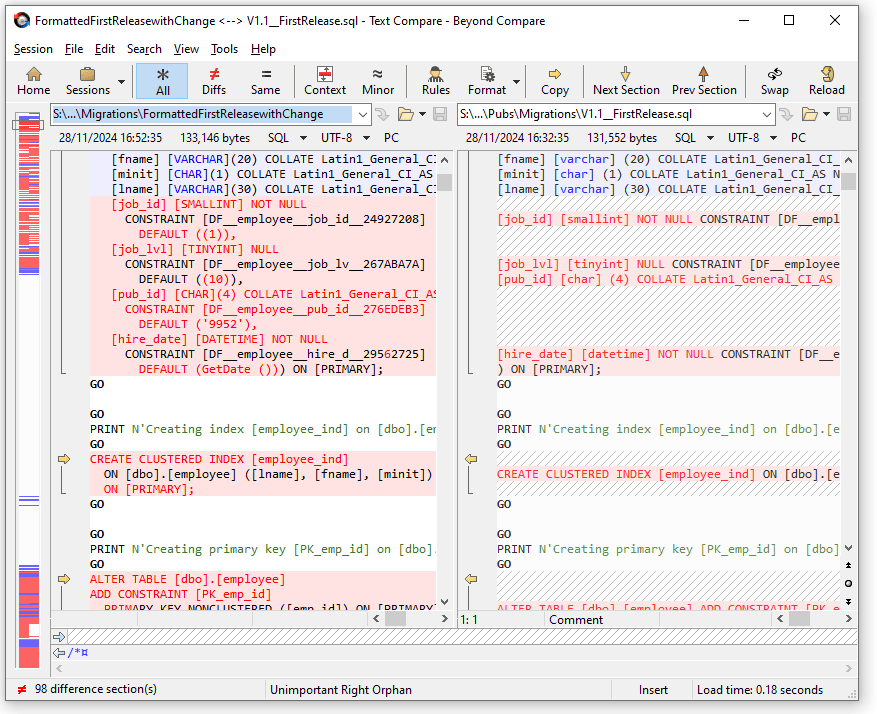
Yes, it picks it up and gives us a warning:
WARNING: At line 40, column 45: 'not null constraint [df__employee__hire_d__29572725]' - '[df__employee__hire_d__29572725]' is diff erent to '[df__employee__hire_d__29562725]' in the code "'...NOT NULL CONSTRAINT [DF__emplo...".No further search attempted..
Just make that into a ‘write-error’ and it can be made to stop a process dead. By comparison, an excellent differencing utility like Beyond Compare detects it too, but it’s much harder to spot amongst the sea of red caused by formatting changes. Can you run this check as part of a scripted process?
Conclusions
It’s nice to find plenty of uses for a script. As well as helping to find differences in SQL in Flyway migration files, this code is more generally good at ensuring that, when annotating and formatting someone else’s code, one doesn’t accidentally change the actual code. This can be particularly embarrassing when it causes the code to generate an error, but the subtle changes can cause a lot of head-scratching otherwise.
Obviously, this code can be improved and made more generic, but that will take more resources than I have. One could improve it to the point where it would find more than the first difference (a task that can become all-consuming) but that misses the point that a single accidental difference is enough to make a big problem for database development.
Tools in this post
You may also like
-

Article
Defining and Using Multiple Flyway Environments in TOML
This article shows how to define environments in your TOML files, use resolvers to provide secure connection details, and configure per-environment overrides and placeholders. It explains how this approach simplifies automation, makes CI/CD pipelines easier to manage, and helps teams work consistently and securely across multiple databases.
-
Article
Why Would You Pay for Flyway?
Flyway is an open-source database deployment tool that also includes a paid tier called Teams. Since it’s open-source, you can just download Flyway and run it for free. You’ll get a robust DevOps tool to assist you in deploying your databases just like you deploy your code. It just works. So, why would you even
-

Webinar
Level Up with Flyway: Exploring Advanced Flyway Capabilities - Module 3
These webinars will give you an in-depth introduction to Flyway and how it can be used to solve problems relating to DevOps, plus accelerate your progress by adopting best practices. Module 3: Exploring Advanced Flyway Capabilities You’ll cover: Leveraging Flyway Autopilot: Discovering the Amazing Benefits of this Plug-and-Play Flyway Environment Effective Test Data Management: Strategies
-

Article
How Redgate’s Foundry is Shaping the Future of Database Innovation with AI
Learn how Redgate’s Foundry drives AI innovation in database management - from intelligent monitoring and ML-based automation, to smarter SQL optimization.
-

Article
Managing Static Data in Flyway Database Development
If your database application requires 'static data' to function, then the best way to manage that data is using a view based on a derived table. This article demonstrates ways to create these views, depending on your RDBMS's capabilities, and how to build and manage them in development work, using Flyway and PowerShell.
-

Article
Discovering What's Changed by Flyway Migrations
A set of PowerShell cmdlets that will 'diff' two versions of a database and provide a high-level overview of the major database changes made by successive Flyway migrations. You can 'diff' a SQL Server database to the same one on PostgreSQL and find out which objects are the same and which are different.