Reducing Database Complexity and Size using Subsetting
Getting realistic test data from large production databases can be a challenge, especially when you're trying to keep dev environments lightweight and secure. Redgate Test Data Manager includes a subsetting CLI that simplifies this by letting you generate smaller, fully representative subsets automatically. This article will walk you through getting started: from setup and configuration to running and refining simple subset operations.
Redgate Test Data Manager aims to support a test data management strategy that gives developers flexible ways to provision the test data they need – whether that’s seed data, generated test datasets, or masked production subsets – without unnecessary overhead. By reducing database size while preserving referential integrity, subsetting helps teams simplify provisioning and improve test efficiency.
What is Subsetting?
Subsetting is a technique used to reduce a large database to a smaller, more manageable size while maintaining data relationships and integrity. This process is valuable when working with large production databases that cannot be easily handled in a non-production environment.
By extracting only the necessary data, developers can work with a dataset that contains the relevant data while reducing the complexity and overhead in managing large databases for development and testing. By excluding columns or rows that carry personal sensitive information, subsetting also becomes a data‑protection strategy: the best way to safeguard sensitive data is simply not to copy it in the first place.
The challenge is to subset in a way that retains referential and logical integrity, so that applications and reporting queries still behave as expected. Phil Factor’s Database Subsetting and Data Extraction article provides a good overview of the technical hurdles involved, dealing with cascading foreign keys, identity columns, orphaned rows, and more.
Redgate’s Subsetter tool is designed to help overcome these challenges and automate the process of test data provisioning for large databases. This is the only way to make subsetting repeatable, reliable, and efficient at scale, especially when working with large, complex databases. Let’s see how it works!
Setting up the Subsetter CLI
To get started with the Redgate Test Data Manager Subsetter CLI (rgsubset), you must ensure that all the requirements are met and you download the right version for your system. If you’re already using Subsetter v1, check the documentation for guidance on the upgrade path, because v2 contains breaking changes.
Before running Subsetter, authenticate your Redgate license using the auth command:
|
1 |
rgsubset auth login --i-agree-to-the-eula |
If you are testing the functionality without a license, add the --start-trial flag to the end of the above command. There is no formal confirmation that this works, but I verified the activation of my trial on the Redgate Licensing Portal. I then needed to rerun the auth command as follows (this extra step is only necessary for trial licenses):
|
1 |
rgsubset auth login --accept-license |
Preparing for subsetting
After installation, you can begin configuring the CLI to run subsetting operations, either through command-line parameters or by using a JSON/YAML configuration file.
Redgate Subsetter takes a source database and applies filtering rules to extract only the required data, while automatically preserving the relationships between tables. It then bulk inserts this subset into an empty target database with the same schema, so that your test environments mirror your production environment, but at a much more manageable scale.
The following diagram illustrates this process:
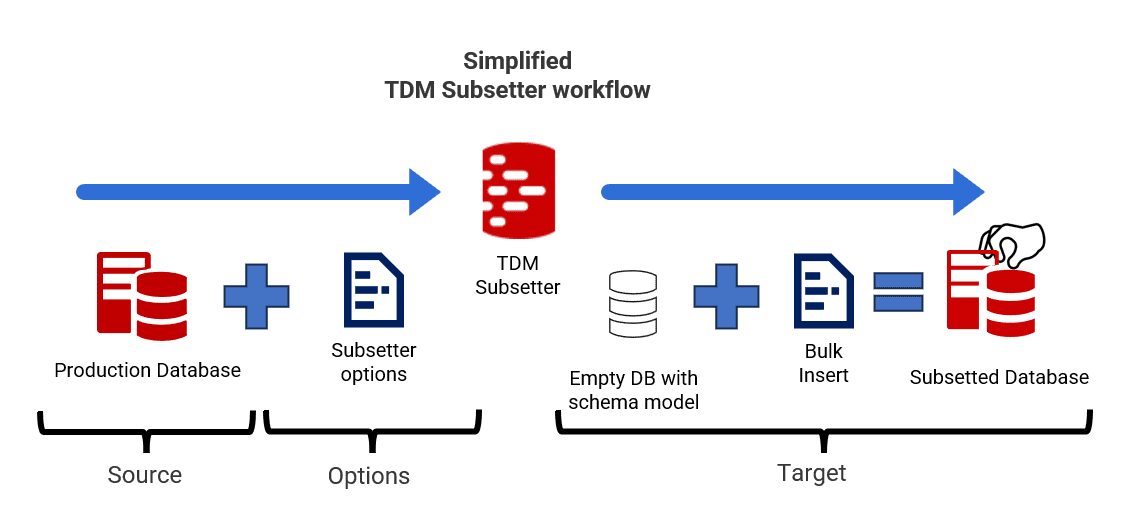
As you can see, to prepare for subsetting, we need a source database containing the full set of data, we need a target database with the same schema but completely empty, and we need a Subsetter options file that instructs the Subsetter how to perform its task.
Creating an empty target database with the same schema
Our first task is to prepare an empty target database, meaning no data but with a full schema model of the source database. The documentation suggests you use either a Flyway baseline migration or a native tool (like SSMS for SQL Server) to script out the database schema with no data. Either way, you must start with an empty target database (no user objects).
My main use for subsetting is to prepare a dev or test database for Flyway, so this would be my preferred way to create the target database. Using a baseline migration script is fine if you’re testing this out on an existing Flyway repository and the script you need already exists. However, I’d tread carefully with regenerating a baseline migration purely to test subsetting, because you wouldn’t want this script committed to source control (without a valid use case). The alternative is simply to run the sequence of migration files on an empty database, to recreate the version you need.
In either case, you’ll have a non-empty flyway_schema_history table in the target database, which will cause a validation error when you attempt to run the rgsubset command. You’ll need to drop this table before running subsetting or instruct the subsetter to delete any existing data in the target (see “Troubleshooting common issues” later in the article).
I think a simpler and cleaner approach is to create the target database using the Flyway prepare and deploy commands. The prepare command will create a script of the source database:
|
1 |
flyway -environment=prod prepare -source=prod -target=build -scriptFilename="D__MyDB.sql" |
…and deploy will run it against your target empty database. See the documentation for more details.
Prepare a basic subsetting options file
Subsetter can automatically create a subset either by targeting a “desired size”, or by following the relationships from a starting table and filter clause that you define. These config options are specified in an Options file, which can be written in YAML or JSON, so you define the rules once and then reuse them.
The desired size mode is most useful and accurate when dealing with a large source database. The entry in the options file might look like this:
|
1 2 3 |
{ "desiredSize": "300MB" } |
Alternatively, if we provide a starting table in the subsetter options file, the subsetter will use that as the root table, and then it automatically “follows the referential tree from this table and collects all the data necessary from the related tables” to build a coherent and referentially intact subset. We can also provide a filter clause to control the specific rows from the starting table that ought to be included in the subset.
You cannot use the two modes in conjunction, but you can run each mode successively. For example, the first subsetting run might use a starting table and filter to specify what data is needed, and then a second run can use the desiredSize to reduce the footprint.
What Happens If You Don’t Provide Options?
If you don’t provide any options, Subsetter will choose a starting table and attempt to build a subset automatically. While this can work for simple databases, the results may be unpredictable in complex schemas. For more consistent results, it’s best to define your own starting table.
The following is a bare-bones JSON options file that specifies an Orders table as the starting table and that it will only include rows with an OrderID of less than 10260. We’ll discuss how to refine this with other options shortly.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{ "jsonSchemaVersion": 1, "startingTables": [ { "table": { "schema": "dbo", "name": "Orders" }, "filterClause": "OrderId < 10260" } ] } |
Save the file as rgsubset-options-MyDB.json (or similar) in the root of your project directory, where you’ll be running the Subsetter commands.
Running the subsetting process
Once your configuration file is ready, you can run the subsetting operation using the CLI. The rgsubset run command is the core of the subsetting process. It extracts a subset of data from a source database and transfers it to a target database while preserving referential integrity, as described above.
The following command runs a subset operation on the source SQL Server database (MyDB) according to the criteria set out in the options file. It loads the subsetted data into the target database (MySubsetDB), which has the same schema but no data. The connection strings for the source and target databases must be in .NET format. Reference connectionstrings.com for examples. For illustration, I’ve used SQL Server credentials for the source and Windows credentials for the target.
rgsubset run --database-engine SqlServer --source-connection-string "Server=mySourceServer;Database=MyDB;User Id=myUser;Password=myPassword;" --target-connection-string "Server=myTargetServer;Database=MySubsetDB;Integrated Security=true;TrustServerCertificate=true;" --options-file rgsubset-options-MyDB.json
The result should be that MySubsetDB contains a smaller, yet structurally complete, subset of the MyDB database. The following example shows the results for a simple database like Northwind for SQL Server (you can find some sample scripts here).
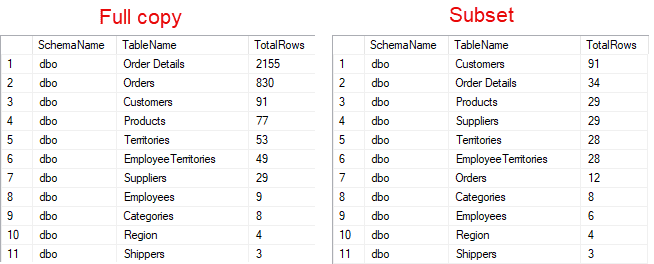
Refining the subsetting options
You can refine your subsetting configuration to gain more control over the size and scope of the subset. By defining starting points, exclusions, and reference tables, you can adjust your subset to match real usage patterns, without resorting to manual scripting or one-off exports.
As well as specifying starting tables or a desired size, we can use filtering rules, exclusions, and static data tables to refine the dataset. Here’s a refined JSON options file that I used to subset my TasteWhisky database:
<
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
{ "jsonSchemaVersion": 1, "startingTables": [ { "table": { "schema": "dbo", "name": "Customers" }, "filterClause": "Id = 1" } ], "staticDataTables": [ { "schema": "dbo", "name": "Distilleries" } ], "excludedTables": [ { "schema": "dbo", "name": "Tastings" } ], "useTemporaryTables": true } |
startingTables– specifies that subsetting starts from theCustomerstable but only includes rows where Id = 1.staticDataTables– ensures theDistilleriestable is fully copied as static data. This is useful for reference data or lookup tables that are needed for consistency in the target database.excludedTables– theTastingstable is excluded from the subset, which can help reduce database size by excluding logs, audit trails, or other non-essential data.useTemporaryTables– set to true so that Subsetter will create temporary tables intempdbinstead of using standard tables in the source database, during processing. This is particularly useful in environments where direct write access to the source database is restricted, as it avoids making changes to the source schema while still enabling efficient data processing.
Troubleshooting Common Issues
Subsetting can sometimes present challenges, especially in complex databases or due to configuration mistakes. I’ve covered some of the minor issues I encountered. For a more detailed list, refer to the official documentation.
Overwrite your subsetted database
By default, Subsetter prevents overwriting an existing target database, so you’ll see a validation failure if attempting to write to a target database with, for example, pre-seeded data or a populated flyway schema history table. To avoid this, you can use the --target-database-write-mode parameter with the overwrite option:
|
1 |
rgsubset run --target-database-write-mode overwrite |
This ensures that Subsetter will delete all rows from tables in the target database before writing out the new subset.
Case-sensitive options
Subsetter’s configuration files are case-sensitive, meaning table names and options must match the exact casing used in the database schema. A minor difference in capitalization can cause tables to be ignored or lead to unexpected errors.
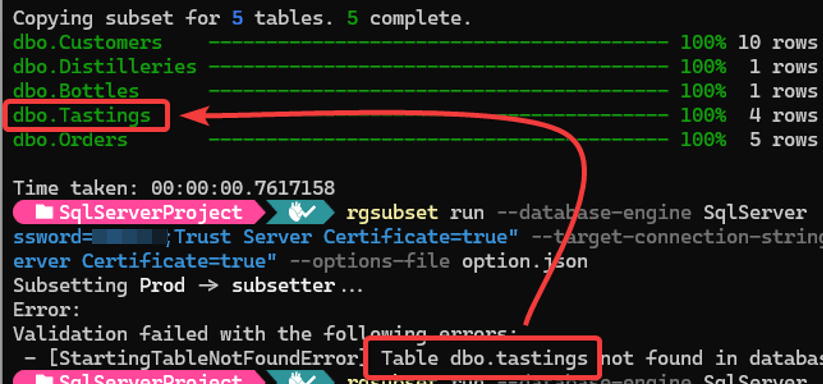
Double-check that table names in your configuration file match the exact case as defined in the database schema.
Connection string issues
Incorrectly formatted connection strings can lead to connection failures. The Subsetter CLI is sensitive to specific keywords and formats, which may differ from other database tools.
- Ensure that your connection string follows the correct format for your database engine. Refer to connectionstrings.com for examples.
- Use .NET connection strings, not JDBC, which is used in Flyway. If transitioning from Flyway, be aware of these differences.
- Some power users attempt to convert between formats—see this Redgate article for more details.
Conclusion
Redgate’s Subsetter CLI simplifies how you manage test data by reducing database size while preserving the structure and integrity of the data your applications rely on. It helps developers and testers work faster, with less overhead, but with environments that still accurately reflect the real data, both in terms of its characteristics and its distribution.
This article introduced the basics of subsetting: installing the CLI, configuring your source and target, defining what data to include or exclude, and avoiding common pitfalls. The next articles will look at more advanced use cases, from optimizing for fixed subset sizes to implementing complex filtering logic to fully automating subsetting in a CI/CD pipeline.
Tools in this post
You may also like
-

Article
Redgate Test Data Manager Updates - March 2026
Redgate Test Data Manager's latest release adds Entra ID authentication, multi-target anonymization, and direct treatment code editing with workflow improvements to make pipeline management faster and more flexible.
-

Article
Where’s the money? The ROI of test data management
You may have heard of test data management (TDM). It’s part of the software delivery process – some would say a crucial part, involving the creation, management, and maintenance of environments for software development and testing. By provisioning fresh, production-like data, it allows developers to test their proposed changes early, thoroughly, and repeatedly with the
-

Virtual Redgate Update
Q1 2024: Virtual Redgate Update
Virtual Redgate Updates are exclusive events for Redgate Partners, Ambassadors and Friends. These one hour Zoom calls will provide a look behind the curtain and an exclusive opportunity to hear directly from and ask questions to our product teams on the latest developments at Redgate. What better way to start than with our brand-new solution,
-

Article
Test Data Management and DORA Compliance in Financial Organizations
DORA requires financial institutions to run tests that prove their systems can withstand operational disruption, without exposing sensitive data. This article explains how Test Data Management (TDM) provides the realistic but safe data needed for resilience testing and the governance controls required under DORA’s ICT risk management rules.
-
Article
Redgate Test Data Manager Product Updates - August 2025
Redgate Test Data Manager’s latest release brings significant performance improvements and new masking capabilities. These updates reduce friction in your workflows, whilst maintaining security and data quality standards. Job execution within the UI – making your work easier Execute subset and anonymization jobs directly from the Redgate Test Data Manager UI. Configure workflows once and
-
Article
Your Test Data Environment: Build vs Buy - a conversation we need to have
After three decades of working with databases, one thing I’ve seen over and over is this: we don’t treat our development and test environments with the same respect we do our production systems. Not because people don’t care. Far from it. It’s usually because teams are under pressure, everyone’s juggling multiple priorities, and the