Running Database Tasks and Tests on Clones in Redgate Test Data Manager
This article demonstrates how to adapt your current database development and testing regimes to use clones (data containers) in Redgate Test Data Manager. It demonstrates how to handle dynamic connection details and how to get from the containers the connection and database information that your development tasks and tests need to function correctly.
Topics covered in this series
What are Clones? – Get Started with Clones – ▶ Development and Testing with Clones
In Redgate Test Data Manager, a ‘clone’ is a database instance running in a container. Each database within is an exact copy of the source databases contained in a ‘virtualized’ data image. An obvious bonus to working with data containers, or clones, is the amount of time and effort saved in database setup and teardown for test-driven development. However, they also provide an easy way to set up servers and databases for development work.
I’ve described previously the basics of defining, creating and removing data images and containers, using the database provisioning, or cloning, CLI (rgclone) in Redgate Test Data Manager. I’ve also shown how to automate these processes when provisioning clones for Flyway migration projects.
This article delvers deeper into the fundamentals of connecting to and working with data containers. I’ll describe how to avoid a few ‘gotchas’, such as around the need to handle short-lived and dynamic connection details, that might otherwise trip you up when connecting your various database CLI tools to containers. I’ll then demonstrate how to adapt existing development tasks (such running tests, generating a build script etc.), to get the required database information from a container, rather than conventional server.
For the demonstration, I provide a PowerShell routine that connects to various data containers, each hosting a different RDBMS (SQL Server, PostgreSQL, Oracle and MySQL) and then, on each one, runs a few standard development tasks and reports the results.
Incorporating data containers into database development and testing
It requires a certain fearlessness to propose the introduction of clones into an established development or testing regime, especially since I don’t know how yours works. As an exercise, I adapted my own test regimes to accommodate data containers (clones). Although the process is reasonably straightforward, there are a few interactions with the server which might prove awkward, especially if you need to adapt tasks that, for example, use the server’s file system to load or dump data, or that rely on credentials having a long lifetime. One other issue that cost me time, when shifting databases previously hosted on Windows over to Linux-hosted data containers, was the discovery that the default way of comparing strings in MySQL and Oracle is different for Linux and Windows hosts!
Having overcome these obstacles, I was relieved to find that, aside from an irritating habit of my rgclone CLI to make random demands for re-authentication, the system worked fine, and the rewards were worth the effort.
Database tests check the performance, security, quality and integrity of a database need to be fast, rigorous and repeatable. Although these tests are best done as part of development, they have separate requirements that aren’t always compatible with the work of designing and creating a database. For a start, it requires the database to start from a set state, hopefully designated by a version number. As well as that, it must be possible to tear down each test easily. I’d add the requirement that it should be as well-automated as possible so that the developer can slip outside for a cup of coffee, blinking in the unfamiliar sunlight. All these requirements become much more easily achievable, once you’ve switched to using data containers.
Connecting database tools to a data container
Most database test systems were written for ‘past times’ when databases were served by static servers to which we could connect using stored and ‘long life’ credentials.
When incorporating clones, we must rewire these test systems to handle dynamic credentials where the locations, port addresses, port, userid or password will change frequently. In these circumstances, it’s important to reference databases (data containers) by a unique and meaningful name
For example, if you use a four-part name for containers containing the project, database, branch and version (e.g., Widget-WidgetDB-dev-V3.2.1.0) then these details, along with the connection details and credentials extracted from the data container object using…
|
1 |
rgclone get data-container Widget-WidgetDB-dev-V3.2.1.0 |
…become a reliable ‘source of truth’, providing all the information required to ensure everyone in the team is certain which version of which database, in which branch of which project needs to be tested, and how to access it.
Getting clear about port addresses
As we’ve seen, we can use the CLI commands, rgclone get data-container, to get the connection details for all our data containers. This will generally provide all we need to reconfigure our test processes to handle containers. The most obvious difference that might catch you out is that the containerized databases use non-standard ports. In fact, a connection to a data container always requires the specification of a non-standard port. However, different RDBMSs often have their own standard ways of specifying the server’s port address if it is not the default port.
The most obvious problem is with SQL Server. Conventional SQL Servers are on port 1433. Containers aren’t, so to carry on as normal, add the port to the server parameter, and make sure that you include the port in JDBC and ODBC connection strings. JDBC uses server:port and ODBC generally, but not always, uses a separate assignment of a value for the server and port.
Also, the various command-line utilities provided with each RDBMS use different conventions for their command line connection parameters. For example:
sqlcmd -S servername,portnumber -U username -P passwordmysql -h hostname -P port_number -u username -p passwordpsql -h hostname -p port_number -U username -d mydatabasesqlplus username/password@hostname:port_number/service_name
Some tools, notably psql, require their passwords to be passed in either session-based environment variables or files (the pgpass file). Oracle tools often require use of Oracle wallet (rgclone doesn’t use this method of authentication.)
Third-party database tools follow all sorts of different conventions. Redgate tools generally follow the SQL Server conventions. To connect SQL Compare to a data container, for example, the command might look like this:
|
1 |
SQLCompare '/server1:clone-external.red-gate.com,23456' '/database1:MyDatabase' '/empty2' '/force' '/options:NoTransactions,NoErrorHandling' '/LogLevel:Warning' 'PathToWriteItTol' '/username1:MyUser' '/Password1:Unguessable1' |
Connecting scripts and applications via connection strings
When you are connecting your database utilities and tools to databases via JDBC or ODBC, the change to accessing data containers will be easy, because rgclone get data-container will provide values for the parameters that are required. However, sometimes you need to connect a utility that doesn’t take a connection string but instead requires all the connection information via parameters. Sometimes you can still gather all the information you need from rgclone, but not always. Fortunately, this information can often be parsed and extracted instead from the information that is provided by rgclone in either the JDBC or ODBC connection string, and then used to make the connection. As an example of this, I had previously connected to Oracle Cloud via a wallet, so providing access to an Oracle data container required adjustment. I had a bit of a struggle with Oracle tools until I realized that the string used to connect to the Oracle data container rather than the Cloud service was just a subset of the JDBC string provided by rgclone.
Server versions
Another potential source of errors comes from the version of the database server used in the container. If the tools you use, installed locally on the machine that is running the scripts, are of a version that is incompatible with the database server version, you’ll start getting errors. You can specify the version of the server used to create the data images. That is a good idea. It is quite a good strategy to keep everything up-to-date but ideally you should move the server version and utility version in unison, because you can get errors from a too-ancient version of the database server or, more rarely, a too recent version.
Server host and collation
The final ‘gotcha’ of using containers, at least for anyone mainly using Windows, is that some RDBMSs adopt Linux’s default of case sensitivity for both identifiers and string literals. When creating databases, it is worth specifying your collation to get around this problem. Each RDBMS has its own approach. The SQL Standard specifies that identifiers (the names of all the database objects) should be case-insensitive whereas string literals can be case-sensitive. By specifying a sensible collation then everything can work smoothly, but most of the problems I’ve hit in moving to Linux hosts for relational databases come from confusion in doing comparisons of string identifiers and literals.
A demonstration
When I started preparing this demonstration, I laboriously tried to show how to adapt all the common database CLI tools to work with data containers, such as: sqlcmd, codeguard, sqlcompare, sqldatacompare, pgdump, psql, sqlite, oraclecmd, mysqldump, mysql, and sqlpackage.
However, I soon realized that I’d already done all the hard work in my Flyway Teamwork framework, to which I’ve added a range of supporting utilities to run routine database development and testing tasks. It includes PowerShell script block tasks to execute scripts with timings, execute scripts from a file one expression at a time, test the results, do a backup, generate build scripts and manifests, produce a report, and so on.
When adding these tasks to a Flyway development, you do this through a callback that retrieves the Flyway version of the database and then runs the required tasks. This allows you to create a script that accesses the database easily, and at the right point in the process, to test, record or report a version of the database. Your run of tests can be done on the version of the database that Flyway just created, or at whatever point in the process you choose.
However, you probably want to be able to run your existing database tasks and tests directly on your data containers, without requiring use of Flyway. That means adapting those tasks so that they can assemble the connection and other project and database details they need, such as the database version) directly from rgclone, and the data containers (as well as through Flyway).
The main difference is that you’ll be directly accessing the database and running the tasks (obviously we can’t use Flyway callbacks) and you’ll need to expend effort explicitly maintaining the current version of the database so that reports and database models can be saved in an appropriately-named file.
Below is the routine to help you tackle all this. It is designed to run a list of tasks that you specify on one or more of your data containers. You can set up your own data container, but this example assumes you use a similar naming convention to that described in Provisioning Clones for Flyway Projects, with the project and branch specified as the second and fourth part of the name of the data container. It also assumes that you’ve set up the rgclone CLI, provided the API endpoint for your Clone server, and authenticated to the server.
The tasks you want to run might include database tests, executing other SQL scripts, producing a report, or creating a build script. I’ve included a few random tasks from the Framework, just for the purposes of this demo. You will probably want to run tasks related to testing such as timing scripts or checking results. The links I provide at the end of the article provide a lot more information about how to run different types of tests using the framework.
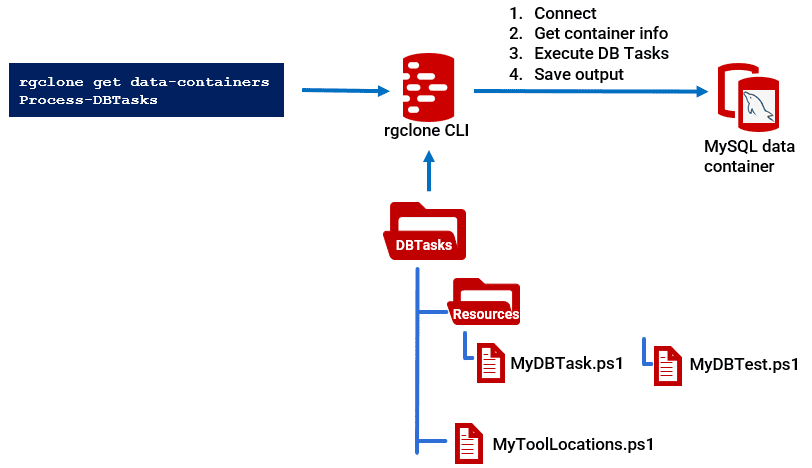
A few notes on running the code (see also the comments in the code):
- It uses the
$WhatIsWantedfilter to run the tasks on all data containers, or just the ones you want (in this example onlymyqlcontainers) - It extracts the necessary details (host, port, user, password, etc.) from each data container and saves them in a hashtable,
$DBDetails - It creates the directories for the output of running each task, named “Project-Database-Branch” with subfolders per database version.
- When we run each of
Process-FlywayTasks, each task uses the information in$DBDetailsto connect to each data container and perform the required operations.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 |
<# To make this work, you will need to specify the project and branch in the second and fourth part of the name of the clone. The rest of the information can be extracted from RG Clone. You will need to install Teamwork utilities into a directory that has a resources directory with all the Cmdlets and scriptblocks from here. https://github.com/Phil-Factor/FlywayTeamwork-Pubs/tree/main/Resources You will also need a file called in the root directory called MyToolLocations.ps1 there is a sample here: https://github.com/Phil-Factor/FlywayTeamwork-Pubs/blob/main/MyToolLocations.ps1 This lists all the tools used by the framework, but you will only need to list the install paths to the tools you'll use You need to set the location of the directory #> $Dir='S:\work\Github\FlywayTeamwork' $VerbosePreference = "Continue" # or 'SilentlyContinue' # rgclone auth only if necessary # You'll need to load the Teamwork cmdlets if they aren't in your powershell profile $Dir='S:\work\Github\FlywayTeamwork' dir "$Dir\resources\*.ps1" | foreach{ . "$($_.FullName)" } # Firstly, we specify what container(s) we need. # We create scriptblock that must return true to include # particular containers to process # $WhatIsWanted = { $_.name -like '*northwind-oracle*' } $WhatIsWanted = { $_ -like '*mysql*' } # $WhatIsWanted = { $True } #Lets do them all # In MySQL, we have to specify each schema as a database $whatToBackup = '' # Where we want to put the various scripts, reports and lists $OutputDirectory = "$env:TEMP\DB" # a list of the schemas to process $TheSchemas = $null; #if you don't know, or if there are several databases, put null $Version = '1.1' #if you are processing a flyway database it will overwrite with the version $flywayTable = "dbo.flyway_schema_history" # only used to exclude it from build scripts etc $ContainerInfo = @() #make sure we start with a clean array. # now we find out the connection details of all the clones that we want to run the tests on #To do this, we create an array of hashtables $ContainerInfo = rgclone get data-containers --output json | Convertfrom-json # now we iterate through our data containers, just pulling out the ones specified in # the $WhatIsWanted filter $ContainerInfo | where $WhatIsWanted | foreach { $Info = $_.name.split('-') # I store extra information e.g project, database and branch $Project = $info[0] $Database = [System.Globalization.CultureInfo]::CurrentCulture.TextInfo.ToTitleCase($Info[1]) # I usually define database with an initial capital. Some RDBMSs get confused. $Branch = $Info[2] $Schemas = $Version = '1.1'; #With a Flyway database, you can overwrite this with the correct version #by inserting the $GetCurrentVersion scriptblock into the list of tasks. #Now we create the hashtable that is then used for every process (array of scriptblocks) $DBDetails = @{ 'service' = $_.jdbcConnectionString -replace 'jdbc:oracle:thin:', '' 'server' = $_.host; #The name of the database server/Host 'port' = $_.port; #the port address 'database' = $Database; #The name of the database 'pwd' = $_.password; #The password 'uid' = $_.user; #The UserID 'version' = $Version; #The version directory that is to be ascribed to the file 'project' = $Project; #The name of the whole project for the output filenames 'RDBMS' = switch ($_.engine) { 'MSSQL' { 'sqlserver' } default { $PSItem } }; #the rdbms being used, e.g. sqlserver, mysql, mariadb, postgresql, sqlite 'schemas' = $TheSchemas #the schemas to be used to create the model 'flywayTable' = $flywayTable; #the name and schema of the flyway table 'ReportLocation' = "$OutputDirectory\$Project-$Database-$Branch"; #Where you wish to write the output 'DirectoryStucture' = 'custom'; 'feedback' = @{ }; # Just leave this be. Filled in for your information 'warnings' = @{ }; # Just leave this be. Filled in for your information 'problems' = @{ }; # Just leave this be. Filled in for your information 'writeLocations' = @{ }; # Just leave this be. Filled in for your information #SQL Server version uses SQL Compare }; # make sure the report directory exists If (-Not (Test-path $DBDetails.ReportLocation -Pathtype Container)) { $null = New-Item -ItemType Directory -Force -Path $DBDetails.ReportLocation } write-verbose "running all processes with $($DBDetails.RDBMS)" $PostMigrationTasks = @( $GetAllDatabaseSchemas, #this tells successive scriptblocks what schemas to process $CreateBuildScriptIfNecessary, #writes out a build script if there isn't one for #this version. The SQL Server version uses SQL Compare $CreateScriptFoldersIfNecessary, #writes out a source folder with an object level # script if absent. this uses SQL Compare $SaveDatabaseModelIfNecessary #This writes a JSON model of the database to a file # that can be used subsequently to check for database version-drift or to # create a narrative of changes for the project between versions. ) Process-FlywayTasks $DBDetails $PostMigrationTasks write-verbose "-----finished running processes with $($DBDetails.RDBMS)" } |
For more details of testing using the Flyway Teamwork framework, See:
- Testing Databases: What’s Required?
- Planning a Database Testing Strategy for Flyway
- Test-Driven Development for Flyway Using Transactions
- Basic Functional Testing for Databases using Flyway
- Running Unit and Integration Tests during Flyway Migrations
- Performance Testing Databases with Flyway and PowerShell
- Running Structured Database Tests in Flyway
- Running Database Assertion Tests with Flyway
Conclusions
Most of the corporate databases I’ve developed were done at a time when the cost and distraction of even the essential test databases was an important factor on deciding a test strategy. Then, the idea of branching and merging, using copies of the development databases, was science fiction. Now, by contrast, I can easily provide myself with a large bank of database servers on cheap hardware and automate away the pain of provisioning and maintenance.
Redgate Test Data Manager’s cloning CLI provides a novel way of taming containerization technology to make it quicker and easier to provision and test databases, to ensure that testing will be done throughout the development cycle. It’s novel, but not disruptive, because it is likely to fit in well with your existing system of automating database chores.
Tools in this post
You may also like
-

Article
Redgate Test Data Manager Product Updates - November 2025
Redgate Test Data Manager’s November’s release brings advanced table configuration for large databases and the ability to save connection strings. Two features that make setting up subsets and managing database connections smoother, easier, and faster. Advanced Table Configuration – simplifying subsetting for large databases Configure subsets on databases with thousands of tables using faceted search,
-
Article
Reducing Database Complexity and Size using Subsetting
Getting realistic test data from large production databases can be a challenge, especially when you're trying to keep dev environments lightweight and secure. Redgate Test Data Manager includes a subsetting CLI that simplifies this by letting you generate smaller, fully representative subsets automatically. This article will walk you through getting started: from setup and configuration to running and refining simple subset operations.
-
Article
Introducing AI-Enhanced Data Generation to Redgate Test Data Manager
We’re excited to reveal our latest effort towards simplifying and accelerating the test data management process: AI Synthetic Data Generation, part of Redgate Test Data Manager. Officially introduced in a session at the recent PASS Data Community Summit, the capability uses machine learning to rapidly generate realistic yet entirely synthetic data – all while maintaining data
-
Article
Redgate Test Data Manager: A Guide for the DevOps Manager
Redgate Test Data Manager will prepare, manage and deliver the test data required to support the full range of development and test activities for any database project. It allows for extensive and automated testing that leads to reliable, online deployment of database changes.
-
Article
Simpler Enterprise Test Data Management using Database Instance Provisioning
Business applications are rarely self-contained, often depending on multiple interconnected databases, each playing a vital role in the functioning of the system. How can we create, refresh, and maintain test data for these complex database systems, and still support dedicated databases and test-driven development processes? This article explains how database instance provisioning helps meet this challenge.
-

Webinar
Harnessing the Power of Test Data Management: Strategies for Success
Join our panelists, Hamish Watson (DevOps Consultant, Morph iT Limited), Daniel Watkins (Director/Principal Consultant, Intesphere) and Redgate’s Steve Jones as they delve into the critical importance of having a robust test data management strategy, exploring how it serves as a key enabler for high-quality software releases and for improving the developer experience.