

This is part of a series of posts from Aisha Bukar comparing MySQL and PostgreSQL. You can see the entire series here.
When working with strings in a database system, you need to ensure that the data is stored, sorted, and compared accurately. That’s where character sets and collations come in. Character sets determine how text is saved while collations define how the database sorts and compares text.
For example, if you’re storing text in different languages (like English, Chinese, or Arabic), choosing the right character set ensures the text is saved properly. Picking the right collation ensures sorting is correct—like ordering names alphabetically while ignoring case differences or accents.
Usually, the default that is chosen at installation is all that is worried about, setting the values to whatever the data for a given region where you are storing data. However, it is important to understand what your initial choices mean, and how to handle any special cases. If you don’t set your values correctly, your database might store or sort text incorrectly, leading to errors, weird behavior, or frustrated users.

What are Character Sets and Collations?
Character Sets: A character set or CHARSET defines how a string is stored in a database. These characters can be symbols, letters, or numbers.
Imagine you have a database for storing users’ names from different countries, and you want to ensure that names in any language (English, Chinese, Russian, etc.) can be saved correctly. This can be done using a character set to display these characters correctly.
MySQL and PostgreSQL both support multiple character sets but there are of course some key differences to explore in both databases, so stick around!
Collations: A collation is a set of rules for comparing and sorting text in a specific character set. Collations help ensure your database sorts text correctly based on your needs.
For example: Does “Apple” come before “Banana”? Or is “é” treated the same as “e”? In some collations, “é” and “e” might be considered equal, even though they look different. Some collations can also be case insensitive where “Apple” = “apple” as well as “Apple” = “aPPlé”.
Every character set has at least one collation, and some have multiple options depending on the use case. Both MySQL and PostgreSQL support various collations, but they handle them in slightly different ways. Let’s dive into how this works!
Character Sets
In this section I will compare how character sets are implemented in PostgreSQL and MySQL.
Character Sets in MySQL
Character sets (or CHARSET) define how sets of characters can be stored in a database.
MySQL uses a default character set for storing and handling text. Right now, that default is utf8mb4, which is great because it supports all kinds of characters, including emojis and symbols from many languages. Think of utf8mb4 as the “universal” option for storing text.
If you want to check the available character sets in your MySQL schema, you can do this by running the following command:
|
1 |
SHOW CHARACTER SET; |
This returns all the available character set in your MySQL schema
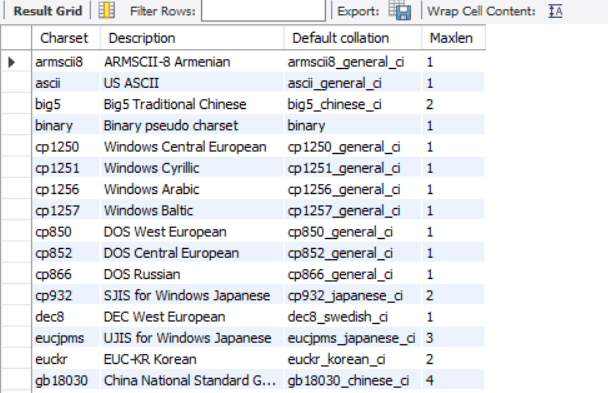
Here is an example of a character set being used in MySQL:
|
1 2 3 4 |
CREATE TABLE users ( id INT PRIMARY KEY, name VARCHAR(255) CHARACTER SET utf8mb4 ); |
The name column can store text in any language using the utf8mb4 character set to support all Unicode characters, including emojis.
Now, let’s insert a statement into the users table using characters from English, French, Arabic, and Chinese language.
|
1 2 3 4 5 |
INSERT INTO users (id, name) VALUES (1, 'My name is Aisha'), (2, 'اسمي عائشة'), (3, 'Je m\'appelle Aisha'), (4, '我的名字是艾莎'); |
Let’s take a look at the data we just inserted:
|
1 |
SELECT * FROM users; |
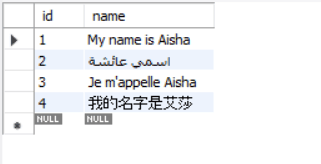

The above image is the output of the query we just ran. You might be wondering how the utf8mb4 character set can store so many different characters. It works by using something called the Basic Multilingual Plane (BMP). The Basic Multilingual Plane (BMP) is the main group of Unicode characters, including letters, symbols, and punctuation used in most modern languages. It covers the basic characters you see in everyday text.
With utf8mb4, these BMP characters usually take 1-3 bytes to store. However, utf8mb4 can also handle characters outside this group, like emojis and rare symbols, by using up to 4 bytes. This makes it capable of storing all Unicode characters including various emojis.
Roadmap to Unicode BMP multilingual by Drmccreedy, used under CC BY-SA 4.0 License /cropped from original. Available at: https://en.wikipedia.org/wiki/Plane_(Unicode)#/media/File:Roadmap_to_Unicode_BMP_multilingual.svg
Character Set repertoire?
A character set repertoire in MySQL simply refers to the set of characters that a particular character set can store and handle. Think of it as the “alphabet” for a given character set. Each character set has a specific range of letters, symbols, and other characters it supports. Here are some common MySQL character sets and their repertoires:
- ASCII: Includes basic English letters (A-Z, a-z), numbers (0-9), and a few symbols like @, #, and %.
- latin1: Adds support for Western European characters, like é, ç, and ü.
- utf8: Supports many languages, including most European and Asian scripts, but does not cover all Unicode characters (e.g., some emojis).
- utf8mb4: Fully supports all Unicode characters, including emojis, special symbols, and scripts from around the world.
The repertoire of a character set determines what text you can store. If you choose ASCII, you can’t store characters like ñ or ü. If you choose utf8, you can store many international characters but might run into trouble with some emoji symbols, utf8mb4 is the safest choice if you need to handle a wide variety of text, including emojis.
The character set you choose significantly affects your database in two ways. First, it impacts data compatibility. For example, a limited character set like ASCII only supports basic English characters. If you try to store characters outside this range, such as accents or emojis, you may encounter errors. For instance, storing the word “café” in ASCII might fail because the “é” character isn’t supported.
Second, it influences storage space. Character sets with larger repertoires, such as utf8mb4, can store all Unicode characters, including emojis, but they use more storage. For example, utf8mb4 can use up to 4 bytes per character, while latin1 uses just 1 byte per character for Western European languages. Choosing the right character set means balancing your storage requirements with the range of characters your application needs to handle.
MySQL supports several character sets, each with its own use. Here’s a breakdown of some of the character sets available in MySQL:
|
Charset |
Description |
Default collation |
Max. length (bytes) |
Use-case |
|
armscii8 |
ARMSCII-8 Armenian |
armscii8_general_ci |
1 |
For Armenian text |
|
ascii |
US ASCII |
ascii_general_ci |
1 |
For basic English characters (A-Z, 0-9, and symbols). |
|
big5 |
Big5 Traditional Chinese |
big5_chinese_ci |
2 |
For traditional Chinese characters (used in Taiwan and Hong Kong). |
|
binary |
Binary pseudo charset |
binary |
1 |
For raw binary data, not text. Useful for storing non-text data (e.g., images, encrypted data). |
|
cp1250 |
Windows Central European |
cp1250_general_ci |
1 |
For Central European languages like Polish, Czech, and Hungarian. |
|
cp1251 |
Windows Cyrillic |
cp1251_general_ci |
1 |
For Cyrillic-based languages like Russian and Bulgarian. |
|
cp1256 |
Windows Arabic |
cp1256_general_ci |
1 |
For Arabic text (primarily used in the Middle East). |
|
cp932 |
SJIS for Windows Japanese |
cp932_japanese_ci |
2 |
For Japanese text using Shift-JIS encoding, often in Windows. |
|
dec8 |
DEC West European |
dec8_swedish_ci |
1 |
For Western European languages used in DEC systems. |
|
greek |
ISO 8859-7 Greek |
greek_general_ci |
1 |
For Greek text |
|
hebrew |
ISO 8859-8 Hebrew |
hebrew_general_ci |
1 |
For Hebrew text |
|
latin1 |
cp1252 West European |
latin1_swedish_ci |
1 |
For Western European languages like Spanish, French, and English. |
|
latin5 |
ISO 8859-9 Turkish |
latin5_turkish_ci |
1 |
For Turkish texts. |
|
latin7 |
ISO 8859-13 Baltic |
latin7_general_ci |
1 |
For Baltic languages like Lithuanian and Latvian. |
|
utf16 |
UTF-16 Unicode |
utf16_general_ci |
4 |
For all Unicode characters (supports all languages). |
|
utf32 |
UTF-32 Unicode |
utf32_general_ci |
4 |
For all Unicode characters, with a 32-bit encoding. |
|
utf8mb3 |
UTF- 8 Unicode |
utf8mb3_general_ |
3 |
For most languages, but limited to 3 bytes per character (older version of UTF-8). |
|
utf8mb4 |
UTF- 8 Unicode |
utf8mb4_0900_ai_ci |
4 |
Full Unicode support, including emojis and all scripts. |
For a full list on all the available character sets available in MySQL, kindly visit the official Documentation.
Character Sets in PostgreSQL
PostgreSQL manages text encoding and storage using character sets to ensure proper handling of multilingual text. Much like MySQL, it uses UTF-8 as its default character set. UTF-8 is a universal encoding standard that can represent almost all characters from every language. This ensures maximum compatibility with modern applications and systems that rely on Unicode.
PostgreSQL also allows you set the character set from the server, however, it does not support a few conversion of some character set within the server, such as, big5, gbk, sjis, and a few others that were mentioned in the documentation. It is also worthy to note that postgresql does not support multiple character set within a single database.
Here is a breakdown of some of the supported character set that are available on PostgreSQL:
|
Character Set |
Description |
Bytes |
Use-case |
|
UTF-8 |
Unicode, variable-width encoding. |
1-4 |
Ideal for modern applications needing support for multiple languages. |
|
SQL_ASCII |
Raw byte encoding with no checks. |
1 |
Suitable for legacy systems without Unicode requirements. Avoid for new apps. |
|
LATIN1 |
ISO 8859-1 (Western European languages) |
1 |
Use in applications limited to Western European text. |
|
LATIN2 |
ISO 8859-2 (Central and Eastern European) |
1 |
Best for Central and Eastern European languages like Czech, Polish, etc. |
|
LATIN5 |
ISO 8859-9 (Turkish) |
1 |
Optimized for Turkish language applications. |
|
LATIN7 |
ISO 8859-13 (Baltic languages) |
1 |
Use for Baltic region languages like Latvian and Lithuanian. |
|
WIN1250 |
Windows Central European (CP1250). |
1 |
Use for Windows-based systems handling Central European languages. |
|
WIN1251 |
Windows Cyrillic (CP1251) |
1 |
Ideal for Windows applications supporting Cyrillic scripts. |
UTF8 is the most versatile and modern character set for global applications. The other character sets (e.g., LATINx and WIN125x) are primarily for compatibility with specific languages or legacy systems. SQL_ASCII should be avoided for new applications due to lack of encoding validation.
For a full list of all the available character sets available in PostgreSQL, please visit the official documentation.
Collations
In this section I will compare how collations are implemented in PostgreSQL and MySQL.
Collations in MySQL
In MySQL, collations determine how string comparisons and sorting are performed. When you create a database, table, or column, you can set a specific collation to decide how text is compared.
Every character set (like utf8mb4) has a set of collations and usually a default collation. Utf8mb4 has a default collation of utf8mb4_0900_ai_ci . Every collation has a set of attributes that describe how it is used when doing comparisons. The following list will help you understand what these parts are, from the name:
- utf8mb4 is the character set that supports the full range of Unicode characters.
- 0900: This indicates that the collation is based on the Unicode Collation Algorithm (UCA) version 9.0. The UCA is a set of rules that defines how Unicode text should be sorted and compared.
- ai: This stands for Accent Insensitive. It means that during comparisons, accents (diacritics) are ignored. For example, “é” and “e” would be treated as equivalent.
- ci: This stands for Case Insensitive. It means that uppercase and lowercase letters are considered equal in comparisons. For example, “A” and “a” would be treated as the same letter.
So, if you compare the strings “café” and “CAFE” in MySQL with this collation, they will be considered equal because accents (the acute accent on “é”) are ignored and case differences (uppercase “C” vs lowercase “c”) are also ignored.
Here are ways you can configure your collations in MySQL:
Server level
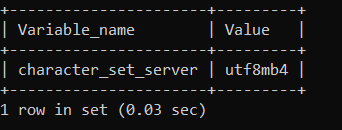
You can specify the character set and collation at server startup using the –character-set-server and –collation-server options directly in the command line when starting the MySQL server using the following command:
|
1 |
mysqld --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci |
You can also choose to modify the configuration file (my.cnf or my.ini) by adding the above command under the [mysqld] section. After starting the server with these options, log in to MySQL and check the values to ensure they are applied.
|
1 2 |
SHOW VARIABLES LIKE 'character_set_server'; SHOW VARIABLES LIKE 'collation_server'; |
This will return something like the following, based on your server’s collation and character set.
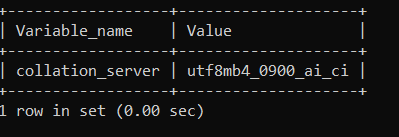
Database level
You can specify a collation when creating a database by running the following command:
|
1 |
CREATE DATABASE mydb CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; |
To be sure the collation has been set successfully, you can check this by running the following command:
|
1 2 |
USE mydb; SELECT @@character_set_database, @@collation_database; |
You should get an output similar to the image below
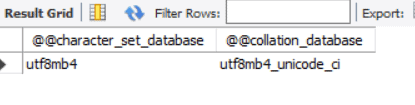
Table or column level
You can specify the collation for a particular table or even column. Here’s how you can do this using the following command:
|
1 2 |
CREATE TABLE mytable ( name VARCHAR(100) COLLATE utf8mb4_unicode_ci ); |
If you want to create a new database with a specific character set and collation, you can run the following command:
|
1 2 3 |
CREATE DATABASE mynew_db CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; |
Then, you can check the output with the following command:
|
1 2 |
USE mynew_db; SELECT @@character_set_database, @@collation_database; |
You should get an output similar to the image below
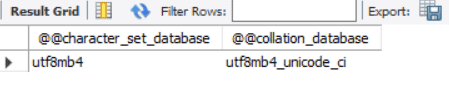
You can also set both the character set and collation in your table by running the following command:
|
1 2 3 4 |
CREATE TABLE your_table_name ( id INT PRIMARY KEY, text_column VARCHAR(255) ) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; |
Then, verify the character set and collation by running the SELECT statement above.
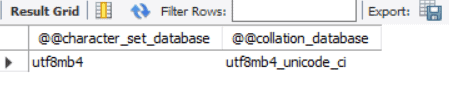
The choice of character set in MySQL directly affects both storage and speed, such as storage and speed impact.
Different character sets require varying amounts of storage per character. For example, latin1 uses 1 byte per character and is suitable for basic Western European languages while utf8mb4 can use up to 4 bytes per character to support all Unicode characters, including emojis and complex scripts like Chinese. This means databases using utf8mb4 may require more disk space than those using latin1.
For speed impact, larger character sets can increase read/write times because they consume more space, which may slow down operations involving large datasets.
Collations tied to character sets, such as utf8mb4_unicode_ci, can be more computationally intensive because they follow complex Unicode rules for comparisons and sorting. Simpler collations like utf8mb4_general_ci are faster but less accurate for multilingual text.
For more details on character sets and collations in MySQL, please refer to the official documentation.
Collation in PostgreSQL
PostgreSQL handles collations similarly but with a bit more flexibility in terms of locale and internationalisation support. Collation in PostgreSQL defines how text is sorted and compared according to locale-specific rules. You can specify a collation at the database, table, or column level, just like in MySQL.
Collations in PostgreSQL are heavily tied to the system’s locale settings. PostgreSQL uses locales, which are sets of rules defining language, region-specific sorting, and text behaviour. You must have the relevant locale installed on your system to use its collation.
When you create a database or a column, you can set the locale to ensure that text is sorted correctly for a specific language or region. For example:
|
1 |
SELECT * FROM users ORDER BY name COLLATE "en_US"; |
This query sorts the rows in the users table by the name column using the “en_US” collation. It orders the names according to the rules of the English (United States) locale. Collation defines how text is compared and sorted, so using “en_US” ensures that the sorting respects U.S. English alphabetical conventions, such as handling uppercase and lowercase letters, accents, and special characters in a specific way.
In addition to system locales, PostgreSQL also supports ICU collations, which provide more robust internationalisation support. ICU collations offer consistent behaviour across platforms. For more information on collation in PostgreSQL, please visit the docs.
When you create a database, you can specify the character set to use with the encoding parameter. By default, PostgreSQL uses UTF8, which supports most languages and characters globally.
Here’s an example of how to create a database with a specified character set, using LATIN1 in this case:
|
1 2 3 4 5 |
CREATE DATABASE my_db WITH ENCODING 'WIN1252' LC_COLLATE 'en_US' LC_CTYPE 'en_US' TEMPLATE template0; |
The template0 ensures that the new database uses a clean slate without inheriting the default UTF-8 encoding.
To verify the character set of the database, run the following command:
|
1 2 3 4 |
SELECT pg_encoding_to_char(encoding) AS encoding_name, datname, datcollate, datctype FROM pg_database WHERE datname = 'my_db'; |

You must also ensure the locale you specify (e.g., LC_COLLATE and LC_CTYPE) must support the encoding. For example, LATIN1 typical locales include: en_US (US English), de_DE (German), and fr_FR (French). If there is an incompatibility, PostgreSQL will raise an error during database creation. Let’s try this out using an incompatible locale:
|
1 2 3 4 |
CREATE DATABASE invalid_db WITH ENCODING 'LATIN1' LC_COLLATE 'zh_CN' LC_CTYPE 'zh_CN'; |
Would return this error:

This is why it’s important to know the right locale for each character set.
Comparison table: MySQL vs. PostgreSQL
MySQL and PostgreSQL support different character sets to store and manage text in various languages. Picking the right character set is important for compatibility, efficient storage, and correct text handling. Here’s a simple comparison of the character sets they support, along with their differences and use cases.
|
MySQL Use Case |
PostgreSQL Use Case |
Key Difference | |
|
utf8mb4 |
Recommended for full Unicode support, including emojis (up to 4 bytes per char). |
Supports full Unicode, including emojis (up to 4 bytes per char). |
No significant difference |
|
latin1 |
Suitable for Western European languages like English, French, and German. |
Also used for Western European languages, limited to ISO-8859-1. |
No significant difference. Both lack Unicode support. |
|
ascii |
Good for simple English text or codes without special characters. |
Similar use case for plain ASCII text, lacks Unicode or multilingual support. |
MySQL offers better error detection for invalid ASCII input compared to PostgreSQL’s SQL_ASCII |
|
latin2 |
Supports Central European languages like Polish, Czech, Slovak, and Hungarian. |
Same use case for Central European languages with accented characters. |
Functionally similar for regional language needs. |
|
latin3 |
N/A |
Used for South European languages like Maltese and Esperanto. |
PostgreSQL provides latin3 for specific niche use cases not addressed by MySQL. |
|
latin4 |
N/A |
Designed for Northern European languages like Estonian and Latvian. |
PostgreSQL’s latin4 fills a gap for some Northern European languages. |
|
latin5 |
Designed for Turkish, replacing some latin1 characters with Turkish-specific ones. |
Same use case for Turkish and other Western European languages. |
Both implementations are functionally similar. |
|
latin6 |
N/A |
Used for Nordic languages such as Sami. |
Exclusive to PostgreSQL for linguistic needs in Nordic regions. |
|
latin7 |
Used for Baltic languages like Lithuanian, Latvian, and Estonian. |
Same use case for Baltic and Scandinavian languages. |
Similar, with no major differences. |
|
latin8 |
N/A |
Provides support for Celtic languages like Gaelic and Welsh. |
PostgreSQL supports languages like Gaelic, which MySQL does not address with a specific encoding. |
|
latin9 |
N/A |
An updated version of latin1 with the Euro (€) symbol and accents. |
PostgreSQL includes latin9 for modern applications requiring the Euro currency symbol and accents. |
|
gbk |
Used for storing Simplified Chinese characters. |
Also used for storing Simplified Chinese characters. |
Both MySQL and PostgreSQL provide GBK |
|
greek |
Supports greek language texts. |
Used for Greek language texts (ISO 8859-7). |
Similar, with no major differences. |
|
hebrew |
Supports hebrew characters |
Used for Hebrew language texts (ISO 8859-8). |
Both databases support Hebrew texts with minimal differences. |
|
cp1251 |
Supports Cyrillic-based languages like Russian. |
Equivalent is ISO 8859-5, used for Cyrillic texts. |
Functionally similar; PostgreSQL uses a standard naming convention (ISO prefix). |
|
cp1256 |
Used for Arabic text storage. |
Equivalent is ISO 8859-6, supporting Arabic. |
Both support Arabic, but PostgreSQL uses ISO standard naming. |
|
SJIS |
Supports Japanese characters (Shift-JIS). Also has support for windows Japanese with cp932 |
Used for Japanese texts. |
Both databases support Japanese texts, however, MySQL offers better support. |
The Latin 1, 2, 5 and 7 is a progression based on the limitations of the earlier sets. Each new Latin character set was developed to address the needs of languages or regions not covered by the previous ones. PostgreSQL supports a wider range of specialized character sets like latin3, latin4, and latin9, catering to niche language requirements.
However, Unicode eventually replaced these character sets because it supports all languages in a single encoding, eliminating the need for multiple Latin variants.
Also, characters not supported by the chosen character set might get corrupted or not saved at all. This is why it is important to know the list of character sets supported by both MySQL and PostgreSQL.
Conclusion
Character sets and collations are critical for ensuring proper storage, retrieval, and comparison of text data in any database. MySQL offers a wider variety of character sets, making it highly customizable for diverse applications, but PostgreSQL simplifies things with a strong emphasis on Unicode and robust support for locales.
When choosing (of moving back and forth) between MySQL and PostgreSQL, consider the languages, regions, and storage requirements of your application. Both databases provide powerful tools to handle multilingual and complex text data. Understanding how they implement character sets and collations will help you design a database that is efficient, compatible, and easy to maintain.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





#/media/File:Roadmap_to_Unicode_BMP_multilingual.svg){kind=link}
Load comments