
I have a great interest in hierarchy solutions, as I plan to write a book on implementing hierarchies in SQL Server in the next year or so (after I see what happens in SQL Server vNext after 2017). Something I didn’t include in my design testing when I built my presentation on hierarchies (available from a link here) a few years back was the cost to remove nodes from a tree. I learned a big lesson today about the cost of deleting from a hierarchy (the hard way). It is definitely something I will be digging deeper into at some point in a lab environment, comparing multiple methods of deleting from a hierarchy, but I wanted to write down the issue with self-referencing table for future use (and hopefully for your use too.)
We have a table with 100s of millions of rows, and deletes from this table were taking forever. There were 17 foreign key constraints to this table, but each of the references were only showing as 1% of the plan. The physical DELETE from the clustered index operator was ~80%, but in the query, there showed up an operator that looked ominous. Here is a small version of the table:
|
1 2 3 4 5 6 7 8 9 10 |
USE tempdb GO CREATE SCHEMA Demo; GO CREATE TABLE Demo.SelfReference ( SelfReferenceId int NOT NULL CONSTRAINT PKSelfReference PRIMARY KEY, Name nvarchar(30) NOT NULL, ParentSelfReferenceId int NOT NULL CONSTRAINT FKSelfReference$Ref$SelfReference REFERENCES Demo.SelfReference (SelfReferenceId) ); |
Even without inserting any data, you can see a hint in the plan what the problem will be:
|
1 2 |
DELETE FROM Demo.SelfReference WHERE SelfReferenceId = 1; |
The estimated plan looks like this:
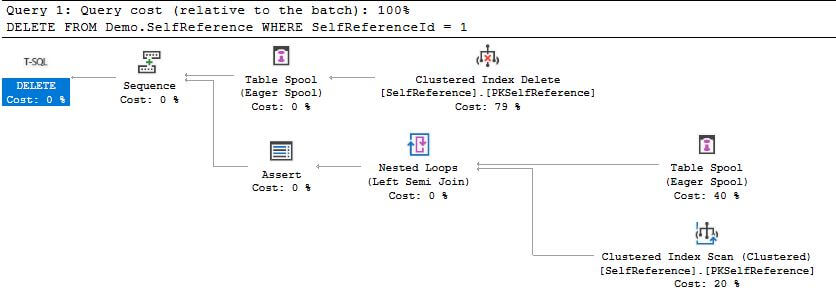
(and no, the problem isn’t related to stats, or that the little percentages don’t add up to 100%.)
The problem is that Table Spool (Eager Spool) operator is needed to avoid what is known as the Halloween Problem (more details from Paul White, who goes deeper into the overall issue than I will get here: https://sqlperformance.com/2013/02/t-sql-queries/halloween-problem-part-2). In order to test the constraint after the operation has completed, the process needs a stable copy of data because no matter how much we SQL Server nerds preach to do things in a set-wise manner, the engine can actually only operate one row at a time. Consider if you have the following set of data in the table we created:
SelfReferenceId ParentSelfReferenceId
--------------- ---------------------
1 NULL
2 1
3 2
Consider you are deleting multiple rows from the table, say SelfReferenceId rows 2 and 3. If you try to remove row 2 first, the operation would fail because it still has a reference, even though the row that references it will also be deleted later in the process. So you need the copy of the table’s data (referenced twice in the query, but it is the same set of data, hence the reduced cost for the second one.) The Table Spool makes a copy of the data it needs to be able to ensure that the answer is correct, no matter the number of rows that are modified, and in what order. And if you are thinking you could do this in order, you could do this case, but not if the data had a cycle, such as:
SelfReferenceId ParentSelfReferenceId
--------------- ---------------------
1 NULL
2 3
3 2
In most situations, this is not a big deal, and unless you are nerding out on query plans, you may never even notice. Even deleting one or a few rows from this table at just under a second per row would not typically been noticed. However, as we were archiving data, and using the object layer to do it, it was extremely noticable. The deletes were occuring row by row (as any good ORM will do for you, make a temp table of rows to delete, then do them one at a time), and each row was taking ~700 ms each. We needed to delete hundreds of thousands of rows, so this was not going to hack it. *
In the two self referencing FOREIGN KEY constraints, there was only 1 row out of these many million rows that had any data. So we just disabled the constraints and it took ~10 ms per row (which got things done ~70X faster!). Naturally this is not the best solution for most servers, and we replaced the constraints so future processes will pay these prices later.
* To be honest, I am rarely for deleting a lot of data. But I am not the CIO, so I don’t always win such arguments (The system the data was in was a 3rd party system too, not designed up to most people’s database design standards as it was built to be morphed to business needs by the end user.)





Load comments