
In Windows XP and above, the OS loader knows natively what to do with .NET executable assemblies, and fires up an instance of the CLR. However, .NET also runs on Windows 98, ME, NT 4.0, and 2000. When you run a .NET assembly on the older operating systems, the CLR has to be loaded somehow. This is the job of the CLR loader stub; a section of native code within a .NET assembly.
Executing a PE file
Unlike the DOS stub I discussed in my previous post, PE executables don’t have full access to the entire physical memory. Instead, they are loaded into virtual memory, split into pages, that the OS maps onto physical memory as required. In the header of each PE file is information telling the loader how to map each section of a PE file into a page, and what access permissions to apply to each page.
Within a normal PE file the executable code can execute jumps and calls to functions in other dlls, such as the Windows API. These dlls are loaded (imported) into the process’ virtual memory address space as required by the OS loader. However, this loading into virtual memory causes several problems.
Firstly, you need some way of storing function calls to imported functions in a PE file that isn’t a direct jmp <memory address>, as the memory address of the function is not known until the dll is loaded into memory.
Secondly, the memory address that the PE file itself is loaded is not known until load time. This means that internal function calls can’t use a direct call either!
Within a PE file, there are two structures that solve these problems; the import table, and relocations.
Import Table
Each entry in the import table specifies the information for a single imported dll. Along with the ASCII name of the dll, the entry contains the RVA of two identical structures, the Import Address Table (IAT) and Import Lookup Table (ILT). The IAT and ILT each contain an entry for every function imported from the dll, in the form of a two-byte hint and an ASCII function name. The import table and IAT are referenced from the 2nd and 13th data directory entries respectively, at the top of the file.
This is the import table in my TinyAssembly example:
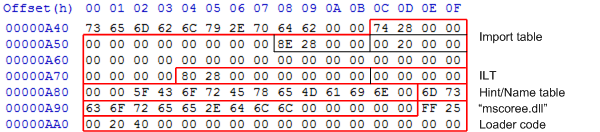
The single entry in the import table has the following highlighted bytes:
- RVA of the ILT (0x2874, file offset 0xa74)
- RVA of the dll name to import, as ASCII (0x288e, file offset 0xa8e)
- RVA of the IAT (0x2000, file offset 0x200). You can see the IAT located before the CLI header.
{kind=link}
The ILT and IAT stores their information in the form of an RVA to an entry in the Hint/Name table (0x2880, file offset 0xa80), which contains the name of the function to call; in this case, “_CorExeMain”.
Calls to imported methods within the assembly are compiled as indirect jumps to IAT table entries. When a PE file is loaded, the loader looks through the import table and replaces all the IAT entries with executable code to jump to the specified function in memory (but leaves the ILT alone). Then, when a jmp <IAT entry> instruction is executed, the code in the IAT entry put there by the loader then jumps to the actual location of the imported function in memory.
After the mscoree.dll string comes the loader stub itself. This is referenced from the AddressOfEntryPoint field in the PE header, and so is the first instruction executed when the assembly is loaded on a DOS-based Windows OS:
|
1 2 |
FF 25 00 20 40 00 jmp 0x402000 |
This references the first entry in the IAT, at RVA 0x2000 (file offset 0x200). This transfers execution to the code inside that IAT entry put there by the loader, and that in turn transfers execution to the _CorExeMain function in mscoree.dll.
Relocations
That’s solved the problem for imported function calls, but what about internal jumps? These include jumps to IAT table entries, as well as direct jumps. Using a structure similar to the IAT would be quite inefficient, as that would introduce an extra level of indirection to every single jump performed in the executable.
Instead, the PE header at the top of the file contains an ImageBase field that gives a preferred memory location that the file would like to be loaded at (in this file, 0x400000). All the internal and IAT jumps are compiled to use that preferred image base.
If, when the file is loaded, it can be loaded at that virtual memory address, everything works as expected. However, if it can’t (say, another dll has been loaded there instead), then all the jump addresses in the assembly need to be modified to take account of the new image base. This is done using the relocations table.
The relocations table is stored in the .reloc section of the file, and contains an entry for every address that needs to be modified. In a .NET assembly, the only address that needs to be modified is the argument to the jmp instruction in the loader stub. In this assembly, the .reloc section starts at file offset 0x1200 and consists of the following bytes:
|
1 |
00 20 00 00 0c 00 00 00 a0 38 00 00 |
Now, in standard PE files, there are expected to be quite a lot of relocations; so they are grouped into blocks. The first 8 bytes of each group specifies the base RVA of the block and the size of the group for that block (including the header itself), the following bytes specify offsets within that block at which relocations have to be applied. At each specified offset, the loader modifies the address there to take account of the new ImageBase at which the file has been loaded.
So, to interpret the relocation entry above:
0x2000
The base RVA of the block0xc
The size of this relocation group0x38a0
The offset within the block to apply the relocation. The high 4 bits specifies the type of relocation (for .NET assemblies, this is always 0x3), so the offset is 0x8a0.
This entry specifies that the address at RVA 0x28a0 (file offset 0xaa0) needs to be modified if the ImageBase changes. And, as you can see, this corresponds to the argument to the jmp instruction of the CLR loader stub.
Putting it all together
We’ve now got enough information to work out what happens when a .NET assembly is executed on a platform that doesn’t natively understand .NET:
- The file is loaded into memory, preferrably at virtual memory offset 0x400000.
- If the file couldn’t be loaded at its preferred
ImageBase, the addresses at the RVAs specified in the.relocsection are modified to take account of the newImageBase. - The entries in the IAT table are replaced with
jmpinstructions to the actual location of the specified functions in memory. - The code at the
AddressOfEntryPointRVA is executed. In .NET assemblies, this is a jump to the first IAT entry. - The IAT entry then performs a jump to the
_CorExeMainfunction inmscoree.dll, which then loads the CLR, reads all the CLR information in the assembly, and starts executing the method specified by the entrypoint token in the CLI header.
Of course, in Windows XP and up, the loader natively knows that any PE file with a non-zero 15th data directory entry needs to be passed to the CLR. This code still needs to exist just in case the assembly is executed on a pre-XP OS.
Or does it…?
What if the assembly is compiled as x64-only? The first OS to run as 64-bit was Windows XP, so an x64 assembly cannot run on any previous OS. In that case, the CLR loader stub is not added to the output assembly (at least for the C# compiler); the assembly has a zero PE entrypoint, no .reloc section, and no import table, IAT or ILT. It still has the DOS stub though.
Well, that’s the CLR loader stub covered! I’ll probably look at signature encodings next, but if anyone has any preferences please do comment below or email me.
Load comments