
Loading On-Premises and external data is a fundamental need for a Data Platform such as Microsoft Fabric. However, during this preview stage, Microsoft Fabric brings many surprises (and, should I say, deceptions?) in this area.
This blog may explain a lot, but I’m not bringing conclusions, but lot of questions. It will be a pleasure to hear your ideas in the comments, let’s talk about it.
How Azure Data Factory Works
In order to understand how everything got mixed, it’s important to understand how Data Factory works in relation to external data.
Data factory has dataflows and pipelines. The pipelines are the ones which go to external resources to retrieve the data. The dataflows, on the other hand, have limited data sources available. The idea is exactly to work over the data after it’s brought to an “internal” environment.
The images below compare the broad range of data sources available for a pipeline with the limited sources available for a dataflow:
|
Pipeline |
Dataflows |
|
|
|
|
All the sources are available for pipelines |
Many sources appear disabled for dataflows |


If the data is located on-premises or in a network we don’t have direct access to, we can use what’s called a self-hosted integration runtime. The self-hosted integration runtime is a software we install in the source network environment, and we use to extract data from the source to the data platform.
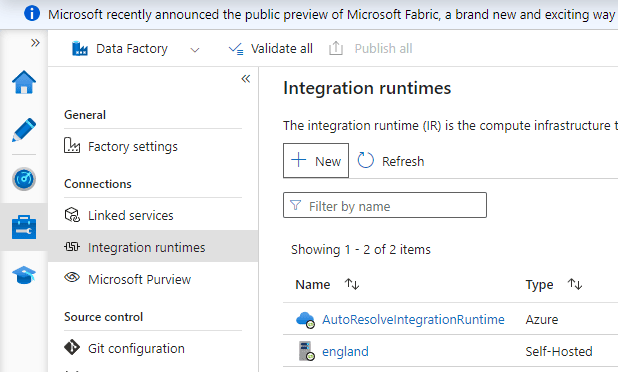

“The source”, in this case, can be an on-premises environment or a private network in a different cloud.
If this reminds you of the on-premises data gateway used by Power BI, it’s because they are mostly the same, with small differences related to the use on Power BI or Data Factory.
Data Gateway and Self-Hosted: How they work
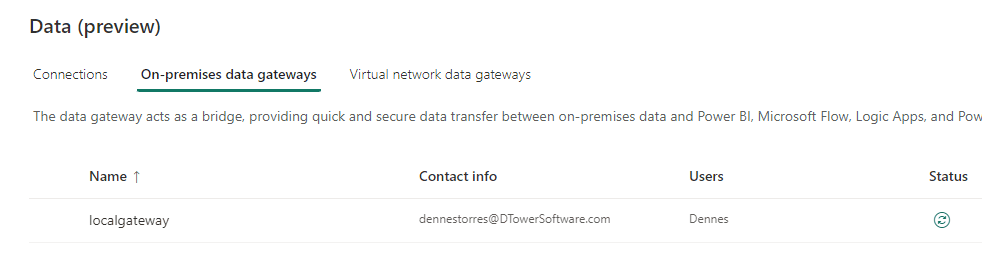
Either the on-premises data gateway or the self-hosted integration runtime, they are installed in the source network. They are intended to work as a bridge to load data from the source networks.
The of these tools’ security feature is to never allow a direct connection from the cloud to the private network. The connection is always reversed: The private network opens a connection to the cloud and keeps this connection open. Using the already opened connection, specific cloud services can request data from the private network.
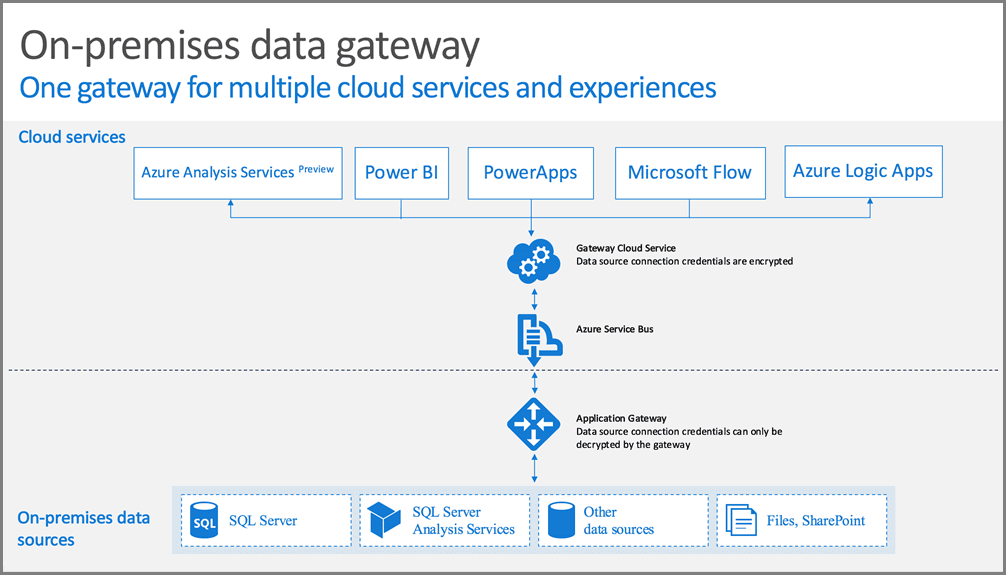
The service responsible for this architecture is called Azure Relay. In a distant past Azure Relay was born as part of Service Bus technologies, that’s why some images illustrating this article still mentions Service Bus. Nowadays, Azure Relay is an independent service and it’s automatically used behind the scenes of these software, either the data gateway or the self-hosted runtime.
Landing Zone: How does it work
In a medallion architecture, Bronze, Silver and Gold are the more well-known zones. However, we also need a landing zone. The landing zone is an area where we drop the source files in the exact format, we are receiving them, before any transformation is made to integrate them into the data lake format. This article (https://piethein.medium.com/medallion-architecture-best-practices-for-managing-bronze-silver-and-gold-486de7c90055 ) and some more on the web have some explanations about the landing zone.
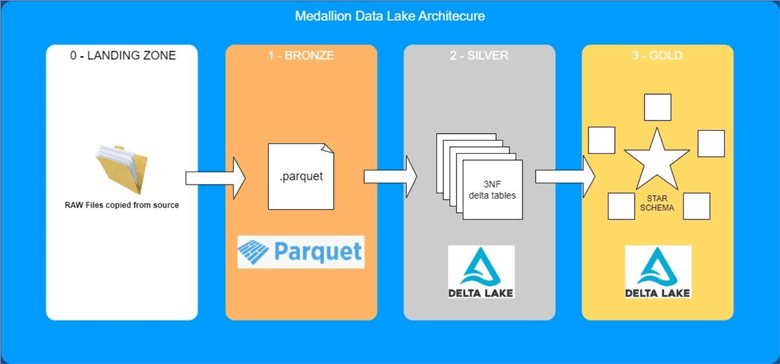
In this way, we drop the files in the landing zone, and start the transformations from the landing zone to the Bronze layer and onwards.
The landing zone has an additional benefit: Usually we keep the ingestion in the landing zone in blocks. For example, let’s say you are ingesting data daily. You create a folder for each daily ingestion. In this way, you can track the lineage of the data, identifying exactly when one specific record or value was ingested.
In my opinion, the lack of a landing zone is dangerous, exactly for making for difficult to keep track of the lineage. Even if you think your initial project is simple and doesn’t need it, the landing zone is still important because it would be way more difficult to implement when the project increases.
Microsoft Fabric Pipelines
There are no integration runtimes in Microsoft Fabric. The execution of the pipelines is managed internally. On the other hand, Microsoft Fabric works inside Power BI environment. As a result, it’s integrated with Power BI Gateways, either on-premises data gateways or VNET Data Gateways.
However, at the moment I’m writing this blog, Microsoft Fabric pipelines don’t support the use of gateways. They can only import data from directly accessible sources. In this way, the pipelines in Fabric can retrieve external data, but not on-premises data.
The image below illustrates how the connection configuration in pipelines lacks a data gateway configuration. The connections need to be directly to the resource. Any existing connection in Power BI environment using a data gateway is not available for use in a pipeline.
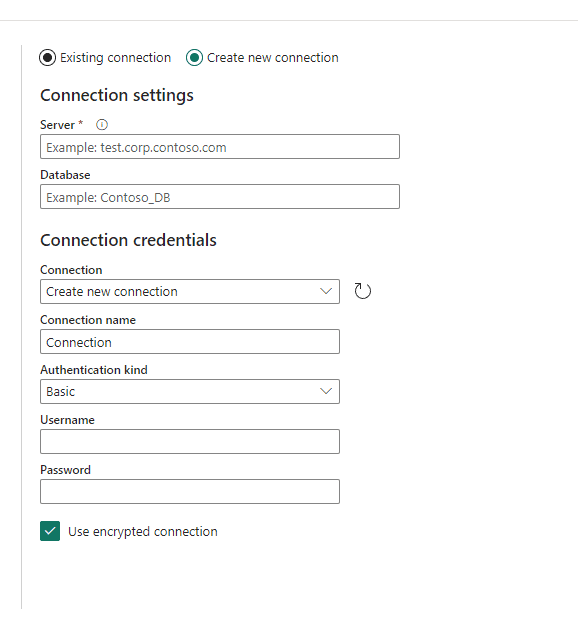
There are two other limitations to consider:
The pipelines in Fabric are new: They are data factory pipelines transposed to Power BI environment. They still lack many types of connectors to different sources. For example: There is no mySQL connector.
Lakehouses and Data Warehouses connectivity is limited: The connectivity to or from data warehouses and lakehouses is limited by the workspace level in Power BI. A MS Fabric pipeline can’t connect to a lakehouse or data warehouse in a different workspace.
The image below illustrates how activities configuration are limited to choose lakehouses or data warehouses located in the same workspace:
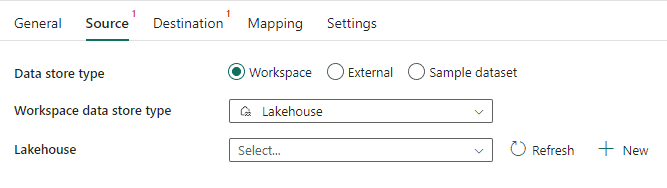
This creates an annoying problem: pipelines need to be created in the same workspace as the data repository (either a lakehouse or data warehouse). In my personal opinion, this is a limitation to the organization. We could have a workspace only for the pipelines, but this technical limitation prevents this.
Microsoft Fabric Dataflows Gen 2
The Dataflows Gen 2 has all the connectors which are already available to Power BI, so it’s capable of accessing a broad range of sources. It also supports gateways, so it can bring data from on-premises environments and private networks to the data lake being created.
The image below shows the gateway support when configuring a connection:
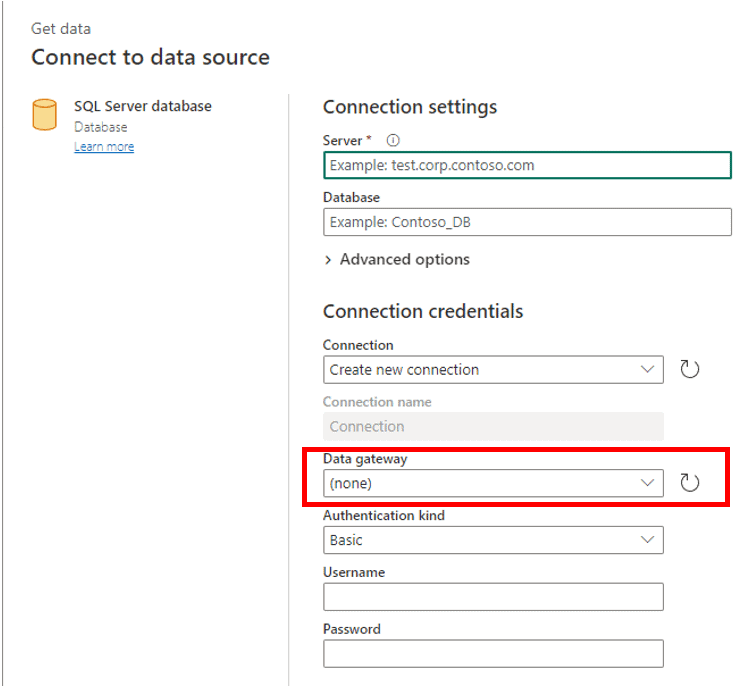
Initially this may seem like an inversion: In Fabric, it’s the dataflow which goes outside to retrieve data, while the pipeline features to do the same are limited.
However, Dataflows Gen 2 can’t drop files into the “Files” area of a lakehouse. They can only drop content into the “Tables” area of a lakehouse. This makes it more difficult to establish a landing zone.
The image below illustrates how Dataflows Gen 2 can drop data in any workspace, but only on the Tables area of a lakehouse or data warehouse, never on the files area.
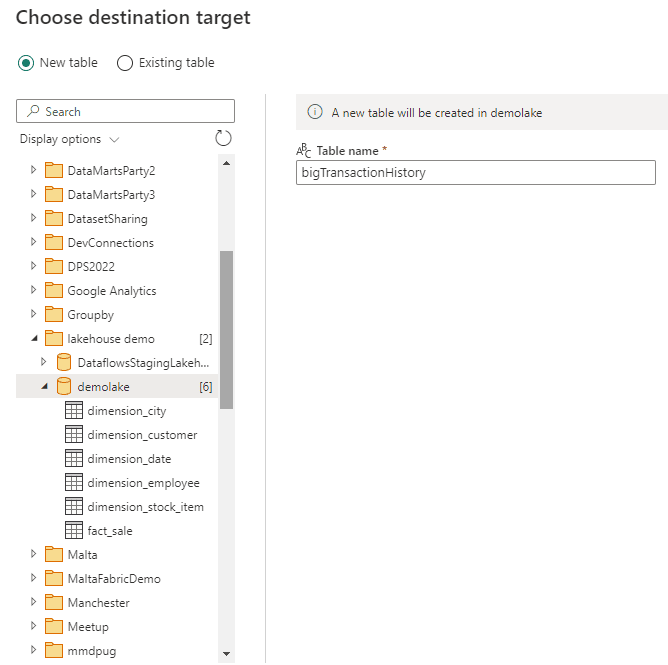
It’s interesting to notice how the Dataflows Gen 2 can read from the “Files” area, but can’t use the “Files” area as destination. This allow them to be used to convert content from the Files area to the Tables area of a lakehouse, but not to import data from external sources to the “Files” area.
Gateway Version
Old versions of the gateway don’t support correctly the dataflow gen 2 and the destinations for lakehouse or data warehouse. The resulting error messages are not easy to understand.
Once you are using the gateway, you need to ensure you are using the most recent version of the gateway. This is not only about the software installed on the on-premises environment, but also the gateway registration in Power BI portal.

This can be annoying: You will need to drop the gateway in the portal and create again. If you have many connections already linked to the gateway. You will lose them. In this scenario you may need to keep the old gateway and create a new one.
The Fabric Landing Zone dilemma
We can use pipelines to create landing zones, but they have limited connectors and can’t use the gateways to read from private networks.
We can use dataflows gen 2 to connect to a broader range of sources and use the gateways, but we can’t drop the content in the “Files” area to create a landing zone.
Our options become the following:
- We could give up having a landing zone and use dataflows gen 2 to drop data directly to Bronze layer, but this can bring limitations to our data solution.
- We could use a data object (SQL Database, lakehouse or data warehouse) as a landing zone. However, the relational format doesn’t make them a good landing zone to keep together the blocks of data ingested. There is plenty of room to be creative at this point.
- We could use a data object (SQL Database, lakehouse or data warehouse) as a pre-landing zone. A dataflow Gen 2 would load the data from external sources to this pre-landing zone. A pipeline would move the data from the pre-landing zone to the “Files” area of a lakehouse, making the landing zone in the lakehouse “Files” area. It’s closer to the landing zone architecture. We keep the blocks of loaded data, but we lose the original format of the data loaded.
Pipelines and Dataflows Gen 2: Summarizing the differences.
|
Pipelines |
Dataflows Gen 2 |
|
|
Connectors |
Fewer connectors available |
Broad range of connectors |
|
Gateway |
Can’t use a gateway, the source needs to be accessible |
It supports the on-premises data gateway |
|
Target |
For lakehouses or data warehouses, it can only target objects in the same workspace |
It can target objects in different workspaces |
|
Drop Location |
It can drop the result in both, Tables area and Files area of a lakehouse |
It can only drop the result in the Tables area of a lakehouse, creating a limitation in relation to a landing zone creation |
Work Around: Uploading files
We can build solutions uploading files to a lakehouse Files area manually or using the OneLake File Explorer.
The OneLake file explorer has many similarities with OneDrive. However, the data is stored in the Files area of a lakehouse. In this way, remote solutions can send files directly to inside a landing area in the lakehouse.
These solutions, however, depend on a lot of other technical solutions or manual work.
Conclusion
Microsoft Fabric is still in an early preview stage. I expect this blog to be outdated soon, improving our architectural options to build the enterprise Data Platform using Fabric.





Load comments