

SQL is easy to start writing. The basic syntax to start returning data is very simple. This low threshold for starting SQL hides some of the nuances that divide efficient queries from inefficient queries. As your SQL gets more complicated and you need to join multiple tables and perform intricate operations on the data, it is important to understand the basics of how queries are processed and how your query decisions impact performance.
The ability to write an efficient query starts with a well-designed database. If the database you are working with is poorly designed, your choices are limited. Even in those scenarios, you can still enhance your query design and follow best practices.
The goal of this post is to provide simple guidelines for writing efficient queries. These guidelines aren’t advanced SQL techniques. These are just the basics that anyone can use to write fast, efficient queries. There are many functions and keywords available in TSQL, so many scenarios aren’t covered by these guidelines. But – they are a good place to start for any query.
Goals of a Query: Producing a fast, efficient query
The concept of an efficient query is simple. You want to create a query that meets the business requirements while having the smallest possible impact on the server. What does it mean to have the smallest possible impact?
- Minimize network traffic
- Minimize physical I/O
- Minimize logical I/O
- Minimize CPU usage – lower priority
- Use set based operations
- Follow coding standards for readable code
Writing an efficient query
To meet the goals listed above, there are some general guidelines you can use. There are always exceptions to those rules, but start here and deviate only if you have a specific, tested justification.
Specify columns – never use SELECT *
It’s common when prototyping a query to use the wildcard character, *, instead of specifying the columns needed. That’s fine during initial development, but as soon as the logic is determined for the query, you should be specifying the exact columns needed, even if it is all of the columns available.
This has two major performance advantages. The first relates directly to the first query goal listed above, minimizing network traffic. If you don’t specify a column, it isn’t sent over the wire back to the client. Over time, this savings can be significant.
The second performance advantage is with the query plan. The query engine might be able to shortcut a table, find a covering index, or perform fewer lookups if you only specify the columns that you need. Even if your query only has a single table in the select statement it can simplify the query plan. It can also reduce future compatibility / metadata issues with external tools and APIs. Some tools don’t gracefully manage new columns added to a query. Specifying each column reduces these issues.
Minimum tables
Use the minimum number of tables required for the query while still meeting business requirements. This one is obvious, but you will sometimes see opportunities to eliminate tables when you refactor code or get new requirements. The query engine will eliminate tables when they aren’t referenced in any way, but sometimes you can change the columns used in your select and remove redundant tables.
Add a WHERE clause
You should always have a where clause in your query when possible. This reduces the number of rows returned and increases the chances of an index getting used. This isn’t always possible, but add one when you can. You rarely need to return an entire table. Even in ETL scenarios, you should have some pattern for deltas / incremental loads.
Use “SET NOCOUNT ON” for all stored procedures
SQL Server SET statements can be used to change certain behaviors and options in queries. It is a standard recommendation to set nocount on in your stored procedures. This prevents messages about the number of rows impacted by statements from getting returned to the client. This is minimal information, but when a procedure is executed thousands, or millions of times, it adds up. When you compound that by all of your stored procedures, it can make a difference.
Create queries capable of using indexes – sargable queries
A primary goal with an efficient query is writing a query capable of using indexes. You will see this referred to as a sargable query. There are some rules you can follow that will help you create a sargable query. These rules are listed below, but it helps to think about how you would use an index, or sorted list, to manually find specific values in that list. The rules you use are very similar for the query engine.
As a simple example, consider the following values taken from the WideWorldImporters sample database, Application.StateProvinces table. The values are sorted and would be representative of an index on the column StateProvinceName. If you are asked to manually find values equal to (=) ‘Iowa’, you can go directly to that value. You can also see how it would be easy to find any other values using the sargable arguments listed below, even the wildcard value. The wildcard rules can be confusing, but you can see how to find all values that start with an I, represented by ‘I%’. However, if you are asked to find all values ending with IA, ‘%IA’, you will need to scan all the entire list to be sure. You may have pre-existing knowledge about state names, but the query engine doesn’t have that advantage. It has to look at every value to be sure it doesn’t end with IA.
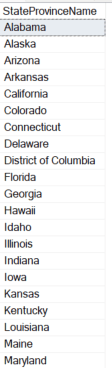
Sargable arguments
- =
- >
- <
- <=
- >=
- BETWEEN
- IN
- LIKE ‘Text%’
Non-sargable arguments
- <>
- NOT IN
- NOT LIKE
- LIKE ‘%text’
- LIKE ‘%text%’
- OR
- Non-deterministic functions in WHERE clause or JOINs
Consider this list when you write your queries. Good design practices make it easier to use sargable arguments. A domain table or a flag with business logic can be used instead of using NOT IN. It can be much better to perform a union between two datasets instead of using OR in a join or where clause. Consider these options, especially for expensive queries. It’s very common to need to try a few different options to find one that works best for your business requirements.
Join types
You normally don’t have a choice between choosing an INNER JOIN versus an OUTER, but there is a performance difference. If you are able to choose an INNER, the query engine is able to filter rows more easily and you will see better performance. Understanding this difference may help with design decisions as you model your database.
When rows are joined together without a join clause or with incorrect JOIN predicates (ON clause), you have seen a Cartesian join. This results in duplicates or repeated rows from one or more tables. When this is done accidentally, I see this this referred to as a Cartesian join. If you want to perform this action by design, I recommend using the syntax CROSS JOIN. This lets future developers, and anyone reviewing the code, know that it was done intentionally. As discussed in my blog on choosing data types, clear intention of purpose is always better.
Set based operations
You should always strive to use set based operations when using a database engine. A set simply means you are retrieving all of the data as a group of rows. A set could be one row or it could be millions of rows. This set of data is what you should be operating on in your queries. Groups of data. There are very few exceptions to this rule. The SQL Server query engine is optimized to operate on sets of data, not single rows.
No cursors / loops
This is the other side of the previous rule, but it bears repeating. Don’t use cursors or other single-row based solutions. Looping over rows may not require a cursor to be defined, but it has the same functional effect. Avoid these design patterns.
There are exceptions to this, and I have used them myself, but they are exceptions. You may need to loop for some admin scripts and you may need loops for large delete statements, but I won’t recommend cursors beyond that. If you find yourself considering a cursor type design pattern, take another look at the problem. There is almost always a different method to approach the problem. If you haven’t looked at using a number table, they can be a good method for some of these queries. I’ve placed a reference to using number tables at the end of this blog. It takes a shift in how you think about some design patterns, but they are very efficient when they fit.
Query hints / index hints / join hints
Query hints, index hints, and join hints are used to override the default behavior of the query engine. They can specify the index to be used, how many processors to use, and many other granular decisions that normally would be determined by the query engine. Only use hints when you are certain you need to change the query engine behavior for that query. I only add them after extensive testing and trying other methods to fix performance issues with a query.
Following the other guidelines presented here should happen before adding query hints. Consider adding indexes, rebuilding indexes as needed, rebuilding statistics, and checking the other basics listed in this blog. If the table is updated frequently, I really recommend looking at the statistics on the table. Statistics are used by the query engine to determine which indexes to use and the strategy for joins. They can have a huge index on performance. Eliminate these items before adding hints.
Adding hints to your queries can cause bigger performance issues than they fix. As the query engine is updated, data is added, statistics are updated, or the database is migrated to new hardware (or the cloud), the hints may no longer help. You can see this in action if you test hints on your queries. It is easy to turn a query that performs poorly into a query that performs very poorly by applying the wrong hint. Forcing a loop join where a hash join would have been the default in the engine might help – or it can cause the query to timeout. Forcing an index might help now, but the right answer might be to update statistics or adding a different index. Let the query engine do what it does best. Only add hints as a last resort.
Consistent data types – implicit conversions
Data types for specific columns need to be consistent between tables. If types differ, an implicit conversion may need to happen in the query plan. This can significantly slow down queries and prevent indexes from being used as effectively.
If you aren’t responsible for the data model, you may need to work around these issues, but finding this issue will help explain why a query isn’t working as expected. The real solution to inconsistent data types is to fix the issue. I consider mismatched datatypes in a system to be a bug and worth the effort to fix.
You can see what an implicit conversion looks like in a query plan below. It doesn’t always appreciably impact performance, but it should be avoided and can often be simple to fix.
[Expr1009] = Scalar Operator(CONVERT_IMPLICIT(nvarchar(20),[WWISideChannel].[Purchasing].[Suppliers].[SupplierReference] as [C].[SupplierReference],0))

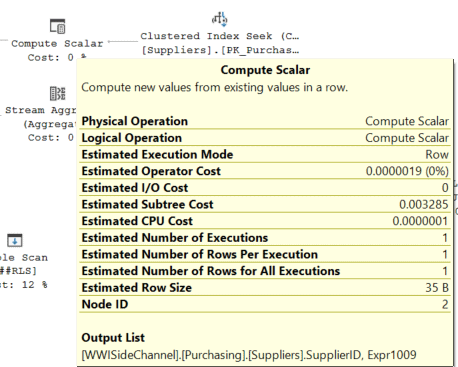
Functions in WHERE and computed columns
Avoid scalar functions in your where clause. Depending on the specific implementation (non-deterministic functions) and the specific function, it can cause the query to process each row individually, which is referred to as RBAR (row-by-agonizing row). In this case, it is much more efficient to pre-process the data in a temp table or CTE and join to that rather than put the function directly in the WHERE clause. Since the output value of the function is unknown to the query engine until the function is executed, it has to execute the function on all rows. It is a performance killer.
If you are using a built-in function, such as LEFT or ROUND, there likely won’t be a performance gain by pre-processing the data in a separate query. Pre-processing just makes a more complicated query that needs to be maintained. An alternative to this is making a computed column that is persisted in the base table. The function won’t need to be run for each query and can greatly increase efficiency of all queries needing this data.
I’ve also seen the same RBAR issue with functions in computed columns. Non-deterministic functions (functions that the query engine must run each time to know the value) can’t be persisted. Functions in computed columns isn’t something you can control in your queries, but if you see them causing problems, you’ll want to address the issue. It is a table design issue that might justify refactoring. I’ve seen non-persisted computed columns, based on functions, that were executed billions of times per week and were the highest user of the CPU on the entire system. Carefully consider your use case when using this pattern.
Index Candidates
Most queries should use indexes. When you look at the query plan for each query, you will want to see index seeks. If you see table scans, it is generally an indication of poor performance. The same can be true of index scans, but they are much better than table scans. You can use the index DMVs, query plan recommendations, the database engine tuning advisor, and Azure index recommendations in addition to the list of potential index candidates below to determine if you need to add indexes. The following isn’t a comprehensive list, but a good starting point for adding indexes. Index creation and maintenance is a complex process, so start with the obvious choices and add as necessary. Remember that each index also needs to be maintained during INSERT, UPDATE, and DELETE statements. This means that the SELECT performance gained has an associated cost and is the reason for careful selection.
- Primary key (possible cluster candidate)
- Unique constraints / business rules / natural keys
- JOIN criteria / foreign key columns
- WHERE criteria
- Covering indexes
- Filtered indexes for specific scenarios
- Query plan / DMV recommendations
Avoid triggers
This is an item that may be contentious, but avoid triggers when you can. It isn’t always obvious when they are used and triggers can cause performance issues if not programmed correctly. When that happens, it’s like an easter egg in your database. A really bad easter egg that no one wants.
In previous versions of SQL Server, triggers were frequently used for history tables. If that’s your use case, consider System-Versioned Temporal Tables or Change Data Capture instead. They are a standard format, thoroughly tested by Microsoft, and the intent for their implementation is clear. The administrative burden is also lower for these options.
Triggers can be used to implement additional business logic and this is the use case that may justify adding them. There is often a better alternative. Carefully consider other options before using triggers. They don’t necessarily hurt performance, but it depends on their complexity and specific implementation. If data is controlled through an API layer, this is usually a better fit than triggers. Follow your enterprise standards and patterns and follow the regular query rules if you do use triggers.
Use consistent formatting, create guidelines
This isn’t directly related to query performance, but use consistent formatting. I have a preferred style I like to use, but consistency is the most important thing. If I am adding or modifying code in a database that uses different standards, I use the existing standards. A consistent format makes it easier to find queries that don’t follow your performance guidelines. If developers are following your formatting guidelines, it is much more likely that they are also following your performance guidelines. It is a quick heuristic check for new and modified code.
Always analyze your query plan
Even if you do everything correctly, the query engine doesn’t always produce an efficient plan. It may not use the indexes you expect or it may use a join type that is inefficient. You won’t know exactly what is happening unless you look at the query plan. It also shows you problem areas in your database that can be addressed.
SQL Server creates a query plan / execution plan for every query that is run. Creating a query plan is a relatively expensive operation, so the query engine stores them in memory and re-uses query plans while they are available. They are an excellent tool for improving the performance of queries.
The goal of analyzing the query plan is to find potential issues in the plan. It may be missed indexes, as mentioned above, confirming how parallelism is used in the query, finding implicit conversions, an incorrect join type, or any number of inefficiencies. More complicated queries have more complicated plans, but they should still be efficient.
Looking at the query plans is relatively straight forward with stored procedures, views and other database objects. You can just look at the predicted or actual plan in SSMS when you run or analyze the query. Dynamic or unknown queries, such as those coming from Entity Framework (EF) or Power BI can also be analyzed. Use SQL Profiler, extended events, DMVs, the query store or the Visual Studio tools for analyzing EF / ORM queries, PBI, or other dynamic queries.
Analyzing plans can be daunting at first but there are several rules that provide a generally-efficient query. You want each query to make use of indexes, avoid table scans and only include data needed by the query. As you start looking at query plans, look at the basics.
- Indexes used
- Seeks versus scans
- Implicit conversions
- Join types
Even if you are experienced in troubleshooting query plans, the book by Grant Fritchey in the references section is an invaluable tool for examining plans and diagnosing issues.
Gathering the query plan
If using SSMS, the query plan can be examined for the current query using the following button shown below or using the shortcut of <Ctrl> + L.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
USE WideWorldImportersStandard GO SELECT PO.PurchaseOrderID ,S.SupplierName ,PO.ExpectedDeliveryDate ,POL.Description ,POL.IsOrderLineFinalized FROM Purchasing.PurchaseOrders PO INNER JOIN Purchasing.PurchaseOrderLines POL ON PO.PurchaseOrderID = POL.PurchaseOrderID INNER JOIN Purchasing.Suppliers S ON PO.SupplierID = S.SupplierID WHERE S.SupplierName = 'The Phone Company' GO |
Showing the plan for the above query, you will see something like the following. You can see that indexes are used for each operation, but there is a clustered index scan and a key lookup. These items could be adjusted by adding or modifying existing indexes, but look at the timing for this query before making any changes. The other thing to note is that the query engine doesn’t recommend any changes. The query engine doesn’t always find the best index recommendations, but it’s a good indicator of index health.
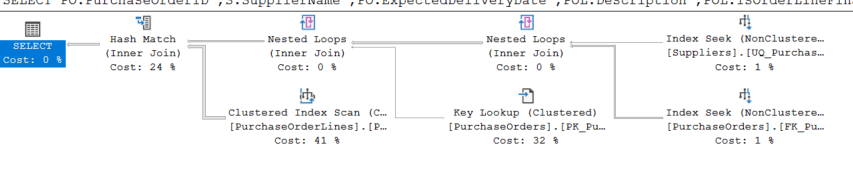
You can get the same thing by putting this SET command above your query and running it in SSMS.
|
1 2 |
SET SHOWPLAN_XML ON GO |
If you want to see a text version in a table format, the following is very helpful. It shows the estimated rows, estimated I/O, CPU and other helpful items.
|
1 2 |
SET SHOWPLAN_ALL ON GO |

If you want to find the query plan for items in the cache, you can use the following DMVs. This is especially useful for items that you didn’t run yourself or queries coming from external tools. You can add query text or object IDs in the WHERE clause to limit your results to the target queries.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED GO SELECT TOP 200 DB_NAME(QP.dbid) DatabaseName ,OBJECT_NAME(QP.objectid,QP.dbid) ObjectName ,QP.query_plan --,sys.fn_sqlvarbasetostr(CP.plan_handle) plan_handle ,QT.text ,QS.creation_time ,QS.execution_count ,QS.last_execution_time ,QS.last_elapsed_time ,QS.last_rows ,QS.total_rows FROM sys.dm_exec_cached_plans CP LEFT JOIN sys.dm_exec_query_stats QS ON CP.plan_handle = QS.plan_handle CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) QT CROSS APPLY sys.dm_exec_query_plan(CP.plan_handle) QP WHERE QP.query_plan IS NOT NULL ORDER BY QS.last_execution_time DESC GO |
Additional performance tools
Set commands
There are a few other very easy to use performance tools available in SSMS. The following are separate commands and can be used individually, but I often use them together. I mentioned above that you will want to verify the timing of queries before adding indexes or doing excessive tuning. This is how I perform that timing. Even though there is a clustered index scan, the query completes in 2 ms and generally wouldn’t be worth additional tuning.
|
1 2 3 |
SET STATISTICS IO ON SET STATISTICS TIME ON GO |
Together, these set commands show the time, in milliseconds, it takes for the query to run and the I/O demands of the query. This can be very useful when comparing different versions of a query to find the one that performs best. Pay special attention to the scan count, logical reads, and physical reads. It’s also useful to compare these values before and after adding an index.

Query store
The query store has a wealth of information about queries running on the server. It has built-in reports and queries and the underlying tables can be interrogated for additional information. This can be a useful tool for advanced performance tuning. I wouldn’t expect beginning developers to use the query store for troubleshooting, but be aware that it is available.
Plan Guides
Plan guides are another advanced tool. They can be used to force a specific query plan for a query, use a specific index or force another table hint. It is similar to using query hints, but doesn’t require direct modification of the queries. This is another item that won’t be used by beginning developers, and may only be used by DBAs in your organization. The query store can be used to easily find queries with forced plans since it is one of the base reports.
Summary
An efficient query is one that meets the business requirements with the smallest possible impact on the server and database. This can be achieved by following simple rules and having a basic understanding about how the query engine works. Each query should minimize network traffic, minimize I/O, minimize CPU usage, use set based operations, and follow coding standards for readable code. The query plan for each query should be analyzed for issues. Developers also need to be aware of factors outside of their query. Indexes, statistics, column types, and computed columns might need to be addressed with the DBA team, data modeler, or architect. Use best practices and keep the query as simple as possible. Only add complications, such as query hints, when thoroughly tested and required. A simple query usually performs better than a more complicated query and is easier to maintain. Start with the basics and try not to deviate from those basics unless you have specific, testable reasons.
References
- https://www.red-gate.com/simple-talk/databases/sql-server/database-administration-sql-server/creative-solutions-by-using-a-number-table/
- https://www.red-gate.com/simple-talk/featured/sql-server-execution-plans-third-edition-by-grant-fritchey/
- https://learn.microsoft.com/en-us/sql/t-sql/statements/set-statements-transact-sql





Load comments