
Automating Azure for Resources On-Demand
- Automating Azure: How to Deploy a Temporary Virtual Machine Resource
- Automating Azure: Creating an On-Demand HDInsight Cluster
See also: Creating a Custom .NET Activity Pipeline for Azure Data Factory
HDInsight in Azure is a great way to process Big Data, because it scales very well with large volumes of data and with complex processing requirements. Unfortunately, HDInsight clusters in Azure are expensive. The minimal configuration, as of now, costs about €5 for every hour that the cluster is running, whether you’re using it or not. Depending on your contract, the monthly cost for an HDInsight cluster can amount to thousands of Euros. Your requirements are unlikely to be anywhere near this, more likely just once a week for two hours: fifty Euros worth of computing power rather than Thousands.
For small-scale use of HDinsight, you will need a way to automate the “on-demand” creation and deletion of an HDInsight cluster. In this article, I’ll be showing you how to do this. I’ll create an HDInsight cluster with R Server, run a very simple R script on the cluster, and then close it.
For the purpose of doing this we will be using some of the ideas of my previous articles, i.e. we will be using the idea of creating resources in Azure by using Custom .NET activities and ARM templates (Create a Virtual Machine in Azure by using ARM template and C#,). Also we will automate the Custom .NET activity by scheduling it via Data Factory deployment (Creating a Custom .NET Activity Pipeline for Azure Data Factory).
To get the task done, we must prepare the following:
- Obtain the Template and Parameters files for the HDInsight cluster
- create a BLOB container where the template is stored
- create an AAD application (to be used for Service-to-service authentication) and give it authorization for the BLOB
- Get app id, key and tenant id (directory id) https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-authenticate-using-active-directory, https://docs.microsoft.com/en-us/azure/azure-resource-manager/resource-group-create-service-principal-portal#get-tenant-id
- Assign application to a role: https://docs.microsoft.com/en-us/azure/azure-resource-manager/resource-group-create-service-principal-portal#assign-application-to-role
- create a Visual Studio class for the code –
- create the cluster from the template
- use the SSH.NET to run the R script and write the script’s output to the BLOB storage
- delete the cluster
- add ADF project and add reference to the class
- create a batch service and pool
- create linked services and outputs
- create a pipeline
- Deploy the ADF and test the HDInsight creation, R script execution and HDInsight cluster deletion
This may seem to be a complex solution with a lot of steps, but the idea is, in fact, very simple: we know that we can schedule any custom C# code via Data Factory, and use this C# code to bring up any resource in Azure by using the Azure API. All of this is scheduled by using ADF and executed by an Azure Batch Service, which in this case is using the smallest “behind the scenes” VM to execute our custom code. Furthermore, there is a SSH.NET library which we are using to pass SSH commands to the HDInsight cluster. By using this, we can trigger the R script execution and ensure that the output is written back to BLOB storage outside of the HDInsight cluster. We can then delete the HDInsight Cluster that we created: We merely request the deletion of the entire resource group after the work is done. This is easy because we make sure that we create the HDInsight cluster in its own resource group so we have a handle to the resource group in our C# class.
Let’s get started:
Obtain the Template and Parameters files for the HDInsight cluster
As I mentioned in my previous article “Create a Virtual Machine in Azure by using ARM template and C#”, it is easy to obtain Templates and Parameters JSON scripts for any resource in Azure, whether the resource is up and running or about to be created.
In this case I will start creating the HDInsight cluster via the Azure portal, setup everything for it as I need it, and before I click ‘Create’, I will download the JSON definition of it and use it later on to bring up the cluster via C#.
For my purpose here I will be setting up a HDInsight cluster of the R Server type on Linux:
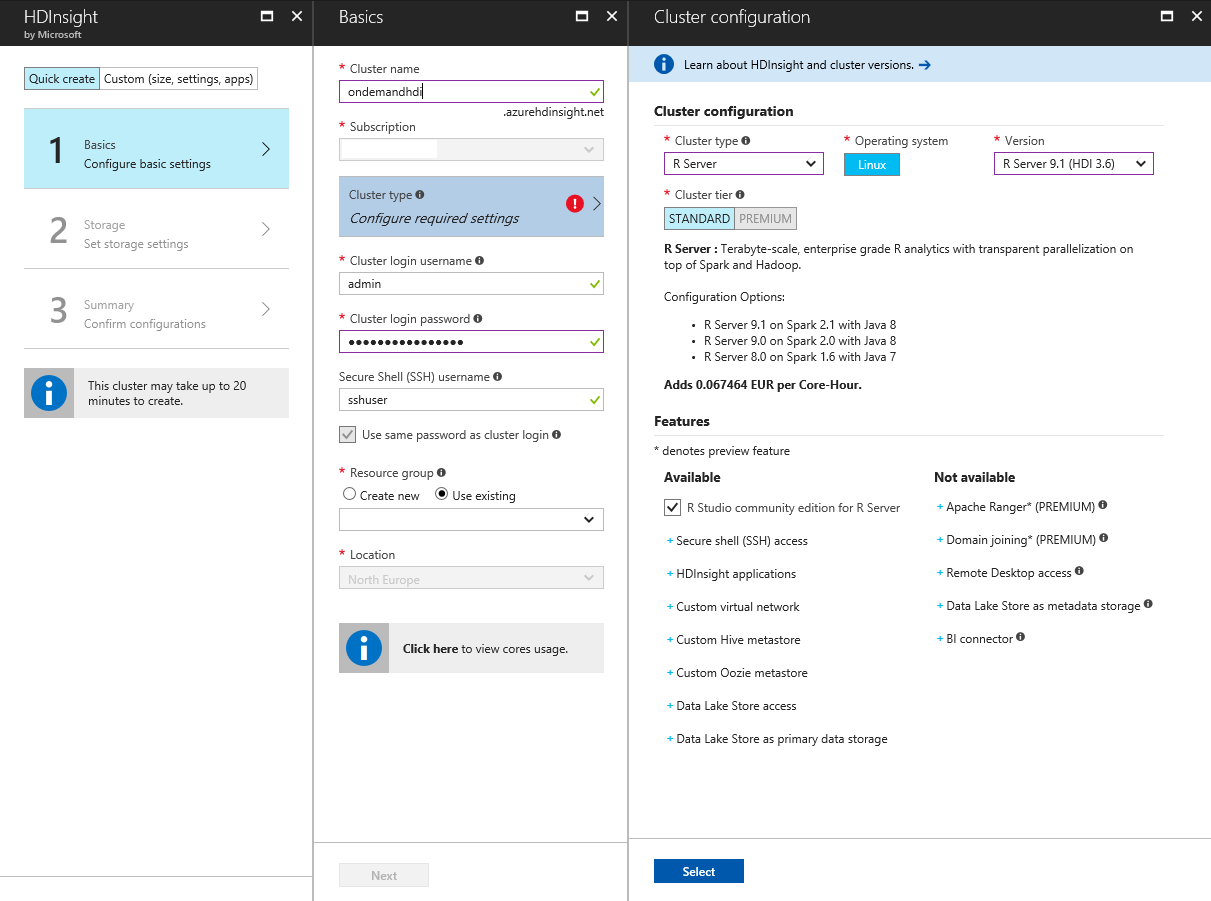
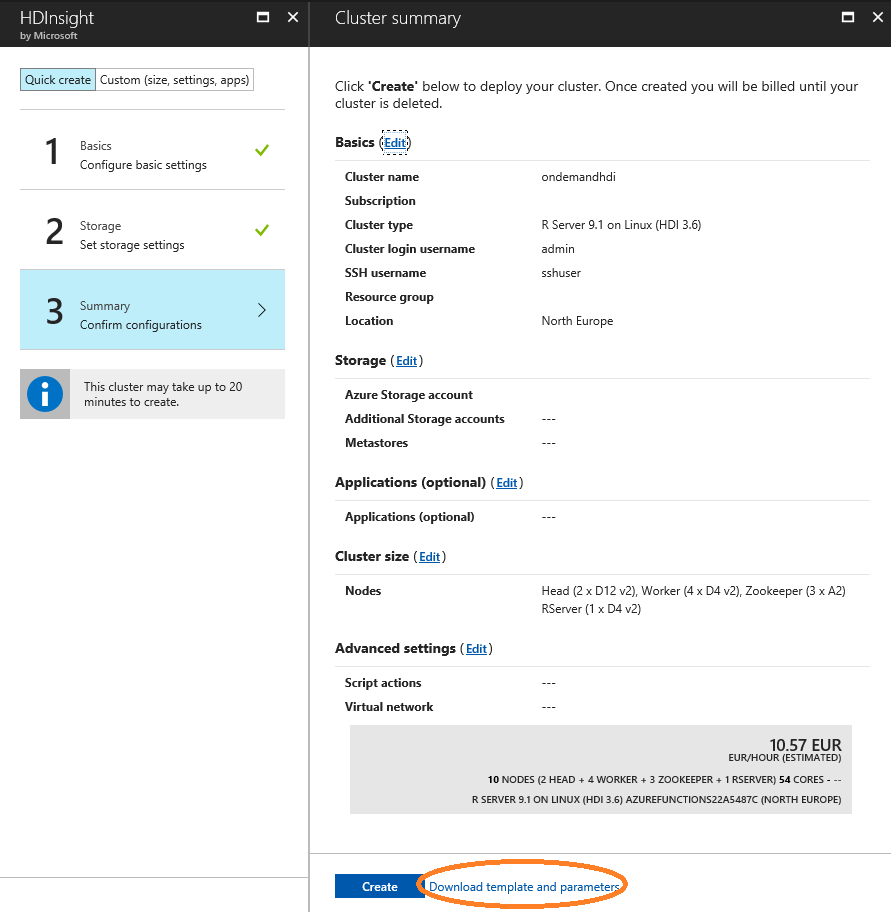
Before clicking on the ‘Create’ button, I will specify everything I need, and then click on the “Download template and parameters” link (ringed in orange below) to save the JSON files. These files will be referenced in my C# code later on.
Create a BLOB container where the template is stored
I will not spend too much time here explaining how to create a BLOB container. The important thing to note is that the container needs to contain the two JSON files for the template and the parameters. In our next step, we will create an AAD application, and this will need to have access to this BLOB container.
Create an AAD application
In this step we must create an Azure Active Directory application that will be used for Service-to-Service authentication. In this step we need to note the App ID, key and Active Directory Tenant ID. For further details on how to create an AAD Application, follow the Azure documentation:
- Get the app id, key and tenant id (directory id) https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-authenticate-using-active-directory, https://docs.microsoft.com/en-us/azure/azure-resource-manager/resource-group-create-service-principal-portal#get-tenant-id
- Assign the application to a role: https://docs.microsoft.com/en-us/azure/azure-resource-manager/resource-group-create-service-principal-portal#assign-application-to-role
Create a VS class for the code
As mentioned earlier, we will be using a C# class to create the cluster from the template. This class will be implementing the IDotNetActivity interface, provided by Microsoft.
The C# class will be similar to:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
using System; using System.Collections.Generic; using Microsoft.Azure.Management.DataFactories.Models; using Microsoft.Azure.Management.DataFactories.Runtime; using Microsoft.Azure.Management.ResourceManager.Fluent; using Microsoft.Azure.Management.ResourceManager.Fluent.Core; using Renci.SshNet; namespace VM { public class StartVM : IDotNetActivity { private IActivityLogger _logger; public IDictionary<string, string> Execute( IEnumerable<LinkedService> linkedServices, IEnumerable<Dataset> datasets, Activity activity, IActivityLogger logger) { _logger = logger; _logger.Write("Starting execution..."); var credentials = SdkContext.AzureCredentialsFactory.FromServicePrincipal( "" // enter clientId here, this is the ApplicationID , "" // this is the Application secret key , "" // this is the tenant id , AzureEnvironment.AzureGlobalCloud); var azure = Microsoft.Azure.Management.Fluent.Azure .Configure() .WithLogLevel(HttpLoggingDelegatingHandler.Level.Basic) .Authenticate(credentials) .WithDefaultSubscription(); var groupName = "myResourceGroup"; var location = Region.EuropeNorth; // create the resource group var resourceGroup = azure.ResourceGroups.Define(groupName) .WithRegion(location) .Create(); // deploy the template var templatePath = "https://myblob.blob.core.windows.net/blobcontainer/myHDI_template.JSON"; var paramPath = "https:// myblob.blob.core.windows.net/blobcontainer /myHDI_parameters.JSON"; var deployment = azure.Deployments.Define("myDeployment") .WithExistingResourceGroup(groupName) .WithTemplateLink(templatePath, "0.9.0.0") // make sure it matches the file .WithParametersLink(paramPath, "1.0.0.0") // make sure it matches the file .WithMode(Microsoft.Azure.Management.ResourceManager.Fluent.Models.DeploymentMode.Incremental) .Create(); _logger.Write("The cluster is ready..."); executeSSHCommand(); _logger.Write("The SSH command was executed..."); _logger.Write("Deleting the cluster..."); // delete the resource group azure.ResourceGroups.DeleteByName(groupName); return new Dictionary<string, string>(); } private void executeSSHCommand() { ConnectionInfo ConnNfo = new ConnectionInfo("myhdi-ssh.azurehdinsight.net", "sshuser", new AuthenticationMethod[]{ // Pasword based Authentication new PasswordAuthenticationMethod("sshuser","Addso@1234523123"), } ); // Execute a (SHELL) Command - prepare upload directory using (var sshclient = new SshClient(ConnNfo)) { sshclient.Connect(); using (var cmd = sshclient.CreateCommand( "hdfs dfs -copyToLocal \"wasbs:///rscript/test.R\";env -i R CMD BATCH --no-save --no-restore \"test.R\"; hdfs dfs -copyFromLocal -f \"test-output.txt\" \"wasbs:///rscript/test-output.txt\" ")) { cmd.Execute(); } sshclient.Disconnect(); } } } } |
It is important to note that in order for this code to work, we need to install the following NuGet packages:
- Install-Package Microsoft.Azure.Management.ResourceManager.Fluent -Version 1.2.0
- Install-Package Microsoft.Azure.Management.Fluent -Version 1.2.0
- Install-Package SSH.NET -Version 2016.0.0
Also, for the R script which is running on the HDinsight cluster I am using a very simple script, which resides on the BLOB storage and gets copied during the SSH session, executed and then the output is copied out to the BLOB storage. In this case the R script contains a very simple computation:
|
1 2 3 4 |
x <- 2 y <- 2 * x y * 2 Sys.time() |
Running this script will produce a file with the console output saved as a text file. There is nothing special about this particular computation; all it does is to prove that a ‘hello world’ R script can be executed on the HDInsight cluster we just created and that the output of this can be written back to the BLOB storage out of the HDFS system.
Delete the cluster
As mentioned earlier, it is very easy to delete the cluster because it was created from the C# code itself and we had defined its own resource group. Hence, we can just delete the entire resource group by calling:
|
1 |
azure.ResourceGroups.DeleteByName(groupName); |
Add ADF project and add reference to the class
Now it is time to add the ADF project within our solution and get ready to deploy our custom .NET activity. One very important step is to actually add a reference to the custom class above to the ADF project. We do this by right-clicking on the ADF References node and then clicking on ‘Add Reference…’. This way, we can deploy the entire solution to Data Factory from Visual Studio, including the DLL files of the Custom .NET activity.
Create a batch service and pool
As mentioned earlier, the creation of this ‘on-demand’ HDInsight cluster depends on being able to use ADF to schedule the execution of a custom C# code, which is executed by a very simple Virtual Machine behind the scenes in our Batch Service account.
For more details on how to create a Batch Service and a batch pool you can refer to the Azure documentation or even to my previous article “Creating a Custom .NET Activity Pipeline for Azure Data Factory”.
Create linked services and outputs
For this Data Factory we will need two linked services: one for the Batch Service …
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ "$schema": "http://datafactories.schema.management.azure.com/schemas/2015-09-01/Microsoft.DataFactory.LinkedService.JSON", "name": "AzureBatchLinkedService_HDI", "properties": { "type": "AzureBatch", "typeProperties": { "accountName": "HDI", "accessKey": "enter the access key here", "poolName": "HDIpool", "batchUri": "https://northeurope.batch.azure.com", "linkedServiceName": "AzureStorageLinkedService_HDI" } } } |
… and another one for the Storage:
|
1 2 3 4 5 6 7 8 9 10 |
{ "$schema": "http://datafactories.schema.management.azure.com/schemas/2015-09-01/Microsoft.DataFactory.LinkedService.JSON", "name": "AzureStorageLinkedService_HDI", "properties": { "type": "AzureStorage", "typeProperties": { "connectionString": "DefaultEndpointsProtocol=https;AccountName=myAccountName;AccountKey=enterKeyHere;EndpointSuffix=core.windows.net" } } } |
For the output, we need the following:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
{ "$schema": "http://datafactories.schema.management.azure.com/schemas/2015-09-01/Microsoft.DataFactory.Table.JSON", "name": "OutputTable_HDI", "properties": { "type": "AzureBlob", "linkedServiceName": "AzureStorageLinkedService_HDI", "typeProperties": { "folderPath": "somecontainer/customactivityoutput/{Slice}/", "partitionedBy": [ { "name": "Slice", "value": { "type": "DateTime", "date": "SliceStart", "format": "yyyyMMddHHmm" } } ] }, "availability": { "frequency": "Day", "interval": 1 } } } |
Create a pipeline
The pipeline JSON looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
{ "$schema": "http://datafactories.schema.management.azure.com/schemas/2015-09-01/Microsoft.DataFactory.Pipeline.JSON", "name": "StartVM_Pipeline", "properties": { "description": "Custom VM start Pipeline", "activities": [ { "type": "DotNetActivity", "typeProperties": { "assemblyName": " ADF_VM.dll", "entryPoint": " VM.StartVM", "packageLinkedService": "AzureStorageLinkedService_HDI", "packageFile": "customactivitycontainer/ADF_VM.zip", "extendedProperties": { "sliceStart": "", "urlFormat": "", "dataStorageAccountName": "storageAccountName", "dataStorageAccountKey": "someKeyHere", "dataStorageContainer": "customactivitycontainer" } }, "outputs": [ { "name": "OutputTable_HDI" } ], "policy": { "executionPriorityOrder": "OldestFirst", "timeout": "02:30:00", "concurrency": 1, "retry": 1 }, "scheduler": { "frequency": "Day", "interval": 1 }, "name": "DownloadData", "description": "", "linkedServiceName": "AzureBatchLinkedService_HDI" } ], "start": "2017-09-01T00:00:00Z", "end": "2017-09-02T00:00:00Z", "isPaused": false } } |
One thing to note is that the timeout is set as “timeout”: “02:30:00”: This is important because it takes up to an hour to bring up the HDInsight cluster and to delete it. If the timeout is set to less, then the ADF pipeline will be marked as failed, even though the routine might do its job anyway.
Deploy the ADF and test the HDInsight creation, R script execution and HDInsight cluster deletion
All that is left to do is to deploy the ADF pipeline to Azure by right-clicking on the project, clicking on ‘Publish’ and going through the publish wizard. Once the pipeline is published, it needs to be executed and monitored. Feel free to add more logger comments in the C# code above and follow the custom messages for debugging.
Conclusion:
In this article we saw yet again the power of Custom Activities in Azure and how this can be used to perform occasional scalable computations that use HDInsight. Microsoft Azure does not yet provide out-of-the box functionality to create on-demand HDInsight clusters for performing periodic workloads on R Server: However the solution that I’ve described in this article opens a new field of possibilities and makes HDInsight a cost-effective choice for processing large volumes of data.
Load comments