

It’s a tale as old as time. You want to read data. Your mate wants to write data. You’re stepping on each other’s toes, all the time. When we’re talking about relational data stores, one aspect that makes them what they are is the need to comply with the ACID properties. These are:
- Atomicity: A transaction fails or completes as a unit
- Consistency: Once a transaction completes, the database is in a valid, consistent, state
- Isolation: Each transaction occurs on its own and shouldn’t interfere with the others
- Durability: Basically, writes are writes and will survive a system crash
A whole lot of effort is then made to build databases that both allow you to meet the necessary ACID properties while simultaneously letting lots of people into your database. PostgreSQL does this through the Multi-version Concurrency Control (MVCC). In this article we’ll discuss what MVCC is and how PostgreSQL deals with concurrency in order to both meet ACID properties and provide a snappy performance profile. Along the way we’ll also be talking once more about the VACUUM process in PostgreSQL (you can read my introduction to the VACUUM here).
Let me start by giving you the short version of what MVCC is, and then the rest of the article explains more details. Basically, PostgreSQL is focused on ensuring, as much as possible, that reads don’t block writes and writes don’t block reads. This is done by always, only, inserting rows (tuples). No updates to an existing row. No actual deletes or updates. Instead, it uses a logical delete mechanism, which we’ll get into. This means that data in motion doesn’t interfere with data at rest, meaning a write doesn’t interfere with a read, therefore, less contention & blocking. There’s a lot to how all that works, so let’s get into it.
Concurrency Modes in PostgreSQL
The world can be a messy place. If everything in a database were ordered, completely in series, including exactly who could access what and when they could access it, we’d never really have to worry about concurrency. However, concurrency is all about simultaneous actions. Two people are going to want to perform two different actions to the same row (AKA, tuple). One person wants to read from it, the other wants to delete it. Or, both want to update it, but with different values. Before we get into describing MVCC, let’s talk concurrency. The PostgreSQL database management system has three ways, isolation levels, for dealing with concurrency:
- Read Committed
- Repeatable Read
- Serializable
Let’s examine each in turn. But first, for those of you who come from SQL Server land, one is missing. That’s right, PostgreSQL does not have a Read Uncommitted isolation level. Personally, I find this to be a feature, but we’ll talk about it.
Read Committed Isolation Level
This is a pretty straightforward concurrency model. When you read from the database, you only want to see the data that has been committed. No data in flight. No data from open transactions. Easy as can be. Well, it quickly gets sticky.
Basically, when you run a query against PostgreSQL, it gets a transaction id (and we’ll be talking about this in more detail later). That transaction id is then used to ensure that as it reads data, it only gets data with transaction ids that are older. Effectively, a snapshot of the database is created, without actually moving data round. There is a lot more to it, but that’s the gist of the behavior.
As such, when you run a SELECT, you’ll only see committed transactions, none that are in flight, based on your transaction ID. Now, if data gets committed before your SELECT, you’ll see that committed data, even if the ID is different, because we’re reading committed data. This works because, as was mentioned in my introduction to VACUUM, PostgreSQL doesn’t delete or update rows, but instead, creates a new row and marks the old row as being replaced. While your transaction is open, it can still read the old row that was “live” when your transaction started because it’s part of your snapshot.
In Read Committed however, if you ran two identical SELECT statements, one after the other, you could see two different sets of data. This is because transactions may be committed between the start of running those two SELECT statements. Read Committed only worries about a single command at a time within a transaction. If you need consistent reads across commands within a transaction, you need to use the Repeatable Read Isolation Level
Repeatable Read Isolation Level
Repeatable Read is pretty similar in behavior to Read Committed. You get your transaction id at the start and that’s used to make sure you don’t see data in flight with newer or open transactions. However, it goes a little farther. Repeatable Read ensures that even if you have two SELECT statements, starting one after the other, the results will always be based on your transaction ID. No data committed after your transaction started will be shown.
In terms of reading data then, this seems like a very attractive way to go, right? Well, sure, if all you’re doing is a SELECT, that’s easy. However, what if you’re reading data in order to UPDATE or DELETE it? Ah, then the fact that another transaction has committed ahead of you becomes an issue. In this case, you will get an error stating:
ERROR: could not serialize access due to concurrent update
This is because, while Repeatable Read ensures that reads are consistent across your transaction. ACID states that you can’t modify data that was modified by another transaction. That requires resubmitting it, if nothing else to ensure that the change didn’t exclude a given tuple from the result set you were going to modify.
Serializable Isolation Level
If you need to ensure that any given transaction sees a perfectly consistent view of the data, and that it has, more or less, exclusive control of that data, you need Serializable Isolation. In Serializable Isolation, PostgreSQL does what the name says, it makes sure that all transactions occur in a serialized fashion, one after the other, in order. For read only transactions, this has zero implications. They’ll proceed the same way as Repeatable Read. The difference is in how writes are handled.
The way this works is roughly the same as Repeatable Read. Further, you can, and may, see serializable errors in Serializable Isolation. The nature of PostgreSQL is such that it has to be able to support simultaneous transactions, otherwise, it would have to take exclusive locks on everything during a given, serialized, transaction, blocking all other transactions. Instead, Serializable adds a second kind of monitoring to prevent two transactions from doing things that would break the other. The monitor can catch when two transactions are doing something naughty to one another and will rollback one of the transactions with the following error:
ERROR: could not serialize access due to read/write dependencies among transactions
Serializable Isolation has a lot going for it in terms of ensuring absolutely consistent data, not only during a transaction, but at the end of that transaction. However, it comes with added overhead. Queries might perform slower as additional evaluations must take place to ensure that a serialized transaction isn’t interfering with another. Further, since it won’t be all that hard to hit read/write dependencies, you need a much more robust error handling mechanism to retry transactions after an error is raised, obviously resulting in slower performance as a transaction starts a second time. There are a number of suggestions on how best to deal with this in the PostgreSQL documentation.
There are more details, a lot more, to all three isolation levels, but as an introductory article, we’ll leave it at that for the moment and talk next about transactions and transaction identifiers.
The Transaction ID
At the root of meeting ACID requirements is the concept of a transaction. It is a unit of work that will be atomic, meaning it completes successfully as a whole, or it does not, and anything it did gets rolled back. Further, the transaction is fundamental to isolation within the ACID requirements, ensuring that each unit of work is independent of the others. The two work together of course to meet the other ACID requirements of consistency (driven by our Isolation Level) and durability (it all got written to disk, yay).
The way you explicitly define a transaction within PostgreSQL is through the use of BEGIN. You then complete a transaction with END. PostgreSQL takes care of every transaction in the event of an error, so there’s no need in most cases for a ROLLBACK. A query within a transaction could look something like this:
|
1 2 3 4 5 6 7 8 9 10 11 |
BEGIN; INSERT INTO radio.antenna ( antenna_name, manufacturer_id, connectortype_id ) VALUES ( 'Stubby', 3, 2 ); END; |
Executing this query will of course insert a row into the table. The BEGIN and END act as wrappers for the single statement transaction. Each transaction is assigned an identifier called a VirtualTransactionId. This value actually consists of two numbers, the process (also called backend) number for this query and a sequential identifier called LocalXID. The VirtualTransactionId is for tracking transactions within a specific process.
Then, there is the TransactionId, mentioned earlier in the article. The primary driver for all the behaviors already described is that TransactionId, or xid, value. This is the value that is used to set the snapshot of data for the various isolation levels. We can see this value easily by querying PostgreSQL:
|
1 |
SELECT txid_current(); |
That will return the highest transaction identifier (xid) at the moment:
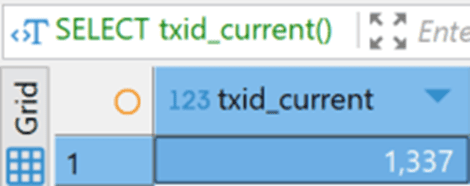
If I execute the INSERT statement and then rerun the query against txid_current, I get a new value:
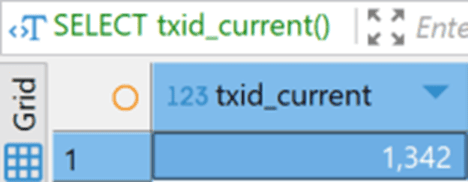
Worth noting, I’m running on a test system without any other connections, so I won’t see the transaction count jumping a whole lot, and even my act of running this SELECT statement adds to the transaction values. So, doing these experiments, you may not see exactly one value increments between checks.
I’m going to go ahead and DELETE the value I just inserted, so I can use the same query again:
|
1 2 3 4 5 |
DELETE FROM radio.antenna WHERE antenna_name = 'Stubby'; |
Now, If go back to my INSERT statement in DBeaver and I highlight the query down to, but just shy of the END; statement, and run that, I have an open, active transaction. I can now query pg_stat_activity, from a second connection, to see queries in motion:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT psa.pid, psa.backend_xid, psa.backend_xmin, psa.state, psa.query FROM pg_stat_activity AS psa WHERE psa.state <> 'idle'; |
Which results in:

I filtered on the psa.state value in order to remove connections that aren’t doing anything currently on the server. I got back two rows, one for the transaction that I have not yet completed and the other for this query itself, marked ‘active.’ The pid values 28,435 and 28,436 are the process numbers. The xid for my idle transaction is stored there in the backend_xid column. I included the backend_xmin so you can see it, but we’ll address it in the next section.
MVCC and VACUUM
Now you have a pretty good understanding of what’s going on with MVCC. Queries are assigned transaction identifier values. Those values are then used to snapshot the data, according to the isolation level of the backend. Then as new rows are added through what would otherwise be an UPDATE process, reads continue on the data that’s there in a row that was marked for later deleting. Same things when running a DELETE statement. Read queries can still hit the row which has been marked for removal. With multiple versions of the rows, you get less locking and block. That’s MVCC at work.
So, a couple of questions. First, what cleans up the rows marked for removal? Second, assuming the xid is a data type, and we’re incrementing that value once for every single transaction, can’t we run out of values?
Yeah, this is where we start talking about the VACUUM process. As I said right at the front of my introduction to VACUUM article (linked above), VACUUM is responsible for removing the rows that have been logically deleted from the database. It does this by taking advantage of the same thing that lets us have snapshots of data, the transaction identifier or xid value.
As transactions open and close, the value for backend_xmin gets updated to the minimum value for open transactions. So, take the above image where we see the backend_xid for one process is 1343 and the backend_xmin is also 1343. Now, if a second transaction starts while our first one is still running, you’ll see two things. First, the new backend_xid value will be an increment on the existing value. And you’ll see the backend_xmin value stay the same. Why?
Because that minimum value is the lowest value for rows marked for deletion. It can remove all rows before 1343, but no rows marked with the transaction ID value of 1343 or higher. That is, until and unless those transactions are also closed and the backend_xmin value gets updated to a new minimum.
As to the transaction id (xid) it does have a data type. It’s a 32-bit value, so over 4 billion transactions can take place before it runs out of room. When it runs out of room, it recycles, starting all over again at 1. Now conceivably that could lead to issues since there could be old values out there.
For example, let’s say the last transaction to create a new row was 32. Now, some period of time later, when the xid wraps around and starts again, we could see issues with concurrency, transactions, reads, who knows what as 32 is higher than 1. There’s another process within VACUUM (told you in the introduction, VACUUM is complicated) that marks “old” transactions as frozen so that they’re ignored for visibility checks as processes read data. This is calculated based on the oldest_xmin value, the minimum of the backend_xmin values, minus a configuration value, vacuum_freeze_min_age. It’s a configurable value because some systems with an extremely high number of transactions may need a very fast freeze process to keep things moving, while others don’t need to sweat it too much.
Proper maintenance on a table is ultimately accomplished through a properly tuned autovacuum process, including freezing rows to avoid transaction ID reuse issues. Autovacuum is triggered to perform maintenance on a table based on a percentage of how many rows have been updated or deleted. By default this is set at 20% of rows. The larger a table gets, the more rows that need to be updated before vacuuming takes place, and the longer between vacuums.
So, for larger, update or delete heavy tables, you shoud consider lowering the threshold percentage of rows before autovacuum kicks in. Although you can set this at the cluster level, it’s usually best (and generally advised) to focus on tuning specific tables. You modify the threshold for autovacuum by altering the table. This example sets the scale factor to 10% of rows.
|
1 2 |
ALTER TABLE my_large_table SET (autovacuum_vacuum_scale_factor=0.1); |
Setting the vacuum_freeze_min_age is one of those parameters that you may need to adjust. Too large a value could lead to:
- data corruption as the xid wraps around
- more disk usage as rows stick around through vacuum process longer
- longer vacuum times as it removes larger amounts of rows.
Of course, setting it too low can lead to things like:
VACUUMmay run more frequently as it tries to deal with marking rows as frozen- More CPU usage again because so many tuples are being checked and marked
- The possibility of lock contention as the
VACUUMis trying to clean things up so frequently
Finally, of course there are many more details and nuances to how all of this works. For example, adding in replication to the mix changes how the backend_xmin values are determined and therefore what tuples can be cleaned during the VACUUM process. Suffice to say, VACUUM and MVCC, while they work extremely well to help reduce blocking within PostgreSQL, are very complex processes that can be messed up.
Conclusion
While PostgreSQL satisfies the ACID requirements of a relational data store quite handily, you can now see that it does it in a way that’s a bit dissimilar from other database systems. MVCC certainly does help read performance for most systems. However, within PostgreSQL, there are still locks taken out and there is still blocking that occurs.
It’s even possible to get a deadlock within PostgreSQL, so MVCC isn’t magic. Overall, MVCC and VACUUM take a bit of getting used to, but as you understand them more, they actually make a great deal of sense.

Load comments