
This is part of an ongoing series of post by Grant as he takes his vast knowledge of SQL Server and applies it to adding PostgreSQL and shares it with you so you can skip learn from his triumphs and mistakes. For more you can go to the Learning PostgreSQL with Grant series home page
The focus of your backup strategy should not be backups. Instead, you should be focused on restoring databases, because, after all, that’s what matters. Simply having a backup is fine. However, if you can’t restore your data from that backup, it doesn’t matter. On top of this is the ability to ensure you can restore your databases to a point in time, not simply to the last full backup. That ability requires a different approach to how you perform your backups.
PostgreSQL has the capabilities to support backups as I already described in my first article on the topic. PostgreSQL also has the capability to restore to a point in time. However, that does require you to change the way you’re performing your backups. This article advances our understanding of how to better protect your PostgreSQL databases by expanding on the database backups and restores into a more full-blown disaster recovery process through point in time restores.
While the important part is the restore, in a classic chicken or egg conundrum, we can’t talk about restoring until we first have a backup, so I’ll start with how you need to backup your databases in preparation for a point in time restore.
Continuous Archiving
Unlike SQL Server, the backups needed for point in time recovery are a little different in PostgreSQL from the full backups. Like SQL Server though, the mechanism that makes this work is a log. In the case of PostgreSQL, it’s the WAL, or Write Ahead Log. This plays an almost identical role to the database logs within SQL Server, recording all actions that modify the data or structures. This means our core process in getting the right kind of protection in place for our PostgreSQL database is the same, conceptually, as it is for SQL Server:
- Get a database backup
- Get WAL backups
- Restore the database, but don’t finish the recovery process
- Replay the WAL files up to a point in time
- Recover our database and be back online.
The backup process I showed in the first article on backups used pg_dump and pg_dumpall to basically export data structures and the data inside them. Those backups could then be used to recover the database, in full. However, these dump files will not work with the WAL for a point in time recovery. Instead, we have to use a completely different approach. We’re going to backup the file system where the data is kept as well as backup the WAL files.
Backing up the file system has implications. We could backup the files that make up a SQL Server backup, rather than run a BACKUP command but then we’re looking at the distinct possibility of corrupt files since transactions may be in flight. Same issue here. While the PostgreSQL storage mechanisms are actually a little different, simply backing up the file system doesn’t guarantee restore. However, the incomplete data files that will be backed up, can be fixed by replaying the WAL. Yeah, I found it a bit confusing too.
Well, prepare for a little more confusion.
In order to set this up, we don’t first create our file system backups. First, we have to set up our logs so that they get archived. Let’s talk about it.
WAL Archiving
The Write Ahead Log or WAL, is in some ways similar to the logs in SQL Server. However, they are a little different. First, by default, the WAL is kept and maintained in a rolling set of files, each 16mb by default. Similar to how SQL Server maintains the error logs, rolling over a fixed number, with new names, the WAL is maintained by PostgreSQL. The WAL files can be used to, more or less, replay the log to get the database back to a moment in time. However, in order to accomplish this, you first need to set up a mechanism to save the WAL files after they’re full to a second location. That way, you can recover from a backup that predates the latest of the WAL files.
To make this work, you have to have a location where you can write the WAL files. This can be anything from attached storage to cloud-based file share or any other place where you can copy the files after they are filled. Next, you need to be able to create a batch command that can move the file to the appropriate storage location.
First, we have to make some modifications to the default behaviors in how PostgreSQL manages the WAL. Similar to how we set the recovery model in a SQL Server database, we have to change the wal_level. It has three – minimal, replica or logical – each one adding information to the WAL. Also similar to SQL Server’s ‘SIMPLE’ recovery model, minimal maintains as little WAL information as possible, purely to support recovery in the event of an unplanned outage, not a full recovery. To get a full, point in time recovery, you have to have the wal_level set to replica or logical. The default is replica, so unless you’ve changed something on your PostgreSQL instance, you should be ready for WAL archiving there.
Next, we have to change the configuration setting archive_mode. The setting has three values, off (default), on and always. On is self explanatory. Always is a setting for working with replication and goes far beyond our introduction to the concepts here. Editing the postgresql.conf file can be done through nano, vim, or whatever your OS allows. You should see the archive_mode setting in the file. If not, you can add it. Set it so that it looks like this:
|
1 |
archive_mode = on |
Then, you have to add, or change, the configuration setting for the archive_command. This is what will move the finished WAL files to your archive location. I’ve created a local directory, just for testing purposes, and I’m copying the files to there through this command:
|
1 |
archive_command = 'test ! -f /walarchive/%f $ cp %p /walarchive/%f' |
This is just a simple copy command. You can absolutely make this more sophisticated as necessary. It verifies that the file doesn’t exist through the test command, then it copies the file over. The %f is a placeholder for the file name. %p is a placeholder for the finished WAL file that is getting archived.
Now I need to restart the system:
|
1 |
Docker restart PostgreHome |
That’s it for configuring the WAL archiving. Next up, backing up all the database files.
Base Backup
The most important thing to remember when setting up for a point in time recovery is that you are recovering all the databases, not just one. To do this then, you need to backup all the databases. You can do this two ways. First, the easiest and the one I’ll cover here, is to use the pg_basebackup tool. The other way is through a series of commands called a low-level API backup. It allows you to place your server into a backup mode and use file system commands to backup the database. This method allows for a lot more granular control over exactly what is getting backed up.
The use of pg_basebackup is very simple. Here is the smallest possible command you can run to get your backups:
|
1 |
pg_basebackup -D \dbarchive |
In this case, I’m running it from the server, so there’s no need to provide a connection. I have to give it an output directory, but that’s it. You can see the output from my execution of the command here:

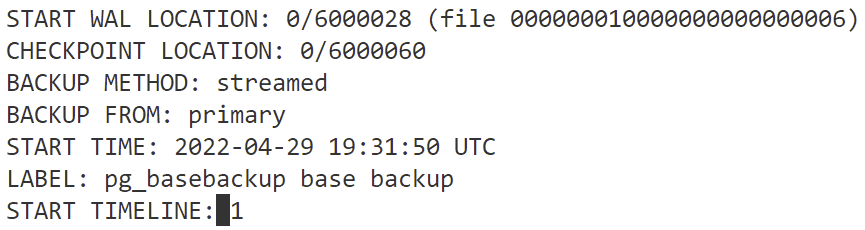
pg_basebackup puts the server into backup mode, copies all the databases into the location specified, and puts the server back into normal operation, all automatically. Additionally, and this is important, it writes out what it did to the backup_label file. This gives you the WAL file start and stop points across the backup so that you know which WAL file you’ll need to start with when running a restore. The output of the backup_label file is here:
From that core backup, you can add a whole bunch of different functionality. For example, you can choose to have your backups compressed into tar files. You can also create a label for the backup. It’s also possible to watch the progress as it goes. The command to do all this looks like this:
|
1 2 |
pg_basebackup -D \dbarchive -P -l \ "Learning PostgreSQL With Grant Backup" -F tar -z |
There are a very large number of other options to let you control your backups, however, this is enough for a recovery. All that’s left is to schedule running this command on a regular basis.
Recovery To A Point In Time
The worst thing possible has happened. Your database has been corrupted, but, you already set up continuous archiving of the WAL and you’re regularly running pg_basebackup, so you’re ready to run a restore. This process isn’t simple. I would strongly recommend you practice this a bunch. Also, prep the restore scripts ahead of time so you’re not scrambling to piece it all together in an emergency.
- Assuming you can access the server, run
pg_switch_wal. This will close out the current WAL file allowing it to get archived, making it available for your restore later. - Stop the server (if it’s online).
- Remove all files and subdirectories in your data directory (same with tablespaces, but I haven’t learned those yet, so I’m going to ignore them for now).
- Restore the Base Backup files from wherever you had them, do this using the appropriate user, in my case, the default
postgresuser. - Remove all files from
pg_wal/, they’re old since we have archiving. - Change settings in
postgresql.confto start the recovery process. - Create a file called
recovery.signalin the cluster data directory. - Start the service.
As I said, you’re really going to want to practice this a few times. Let’s address a few of these steps in more detail.
Running pg_switch_wal requires a connection so you can run a query: SELECT pg_switch_wal(). That will cause the WAL to close the current file and because you have archiving set up, it’ll get added to the archive location. If you can’t connect, then you’re losing what in SQL Server land we refer to as the tail log, the last bit since the last backup. You can still try to get this by copying the file out of the pg_wal directory and the restoring it there right before you restart the service.
You can stop the server use pg_ctl stop. Same thing in reverse to start it, pg_ctl start.
Since the base backup copies everything, you just need to get rid of everything. You want to be able to copy all the information you have stored in whatever location you used for it. The exception is the pg_wal directory. If you want to restore just the backups from pg_basebackup, that’s fine. Leave it in place. However, since we’re going to a point in time based on the archive of the WAL files, it’s best to clean out this one folder after you restore the rest. How you remove the directory depends on the OS. Same thing with the copy from backup. If you do drop and recreate the directory, make sure you set the postgresql user as the owner with appropriate security:
|
1 2 |
sudo chown postgres:postgres /var/lib/postgresql/14/data sudo chmod 700 /var/lib/postgresql/14/data |
Changing the postgresl.conf file is the thing I find the most confusing. However, that’s how recovery is done. There should be a variable called restore_command within the configuration file. It’s likely commented out. Remove the comment and edit the path. The default will be:
|
1 |
/path/to/database_archive/ |
In my case, I’m going to change it to:
|
1 |
<em>/walarchive</em> |
The full command would then be:
|
1 |
restore_command = ‘cp /walarchive/$f %p’ |
Finally, because I want to restore to a point in time, I have specify that. It can be time, a log sequence number, a transaction id, or a restore point if I’ve created them (beyond the scope of this article). Let’s assume time. I’ll add this below the restore_command:
|
1 |
Recovery_target_time = ‘2022-05-02 15:24:00 EDT’ |
That’s it.
As to the recovery.signal file, you just have to create it:
|
1 |
vi recovery.signal |
When we restart the service, it will restore all the logs up to the point in time we specified. It’ll also rename recovery.signal to recovery.done so that if you restart the service, it doesn’t restart the recovery again. No need to reedit the postgres.conf file since the existence of recovery.signal is what starts the recovery process.
That should do it. A point in time restore accomplished.
Conclusion
To say this is complicated barely begins to cover it. However, it’s really just a question of taking it one step at a time and validating that step. Ensure you have WAL archiving validating that files are being placed into your archive. Same thing with pb_basebackup. For the restore process, just script out all the steps and make darned sure you practice them before a real emergency hits.





Load comments