

Previously, we introduced and discussed the Parquet file format and SQL Server and why it is an ideal format for storing analytic data when it does not already reside in a native analytic data store, such as a data lake, data warehouse, or an Azure managed service.
Both Python and the Parquet file format are quite flexible, allowing for significant customization to ensure that file-related tasks are as optimal as possible. Compatibility with other processes, as well as keeping file sizes and properties under control will also be introduced here.
This is an area where new services, options, and optimizations are introduced on a regular basis. As data quickly grows across organizations, Microsoft, Amazon, Google, and others all need to regularly improve data storage and performance to ensure that data continues to be acceptable.
What is Next?
In addition to a review of the Parquet file format, a set of processes has been knit together using Python to connect to SQL Server, create a data set, and write it to files. The piecemeal nature of this process allows for code to easily be added, removed, or modified to change how data is written or read.
This level of customization is the focus of this article, diving into partitioning, file format details, compression, and reading Parquet files into Databricks. These examples are only the beginning and introduce how it is possible to:
- Learn about a new feature.
- Gather information about how to code the feature.
- Add/update our Python code to make use of that code.
Partitioning
The beauty of using Python is that there are more options available than could be comfortably demonstrated in this article. For example, let’s say that this output file was quite large and there was a desire to split it into smaller and more manageable chunks. This could be accomplished by partitioning the output file, as shown in this code sample:
|
1 2 3 4 |
pyarrow.dataset.write_dataset(table, FILEPATH + 'customer_totals_partitioned', format="parquet", partitioning=pyarrow.dataset.partitioning( pyarrow.schema([("CustomerOrderCount", pyarrow.int16())]))); |
The key column is specified by the column header name in the schema set provided to pyarrow.dataset.partitioning. In this scenario, I chose the CustomerOrderCount column to partition by. The result of executing this code is a new folder created at the output file path:

Within the folder are individual folders with parquet files for each partition:
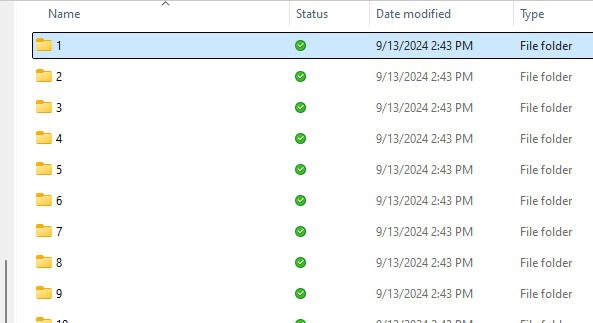
Depending on your application, a jumble of new folders may be good…or it may be annoying. Here are the contents of one of these folders:
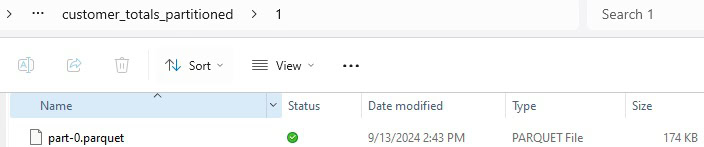
An ideal partitioning column would be selective enough to evenly partition the data set, and do so into meaningful sub-files. Note that there are limits to partition counts. Consider the following code that attempts to partition the data set by CustomerID:
|
1 |
pyarrow.dataset.write_dataset(table, FILEPATH + <br> 'customer_totals_partitioned', format="parquet", <br> partitioning=pyarrow.dataset.partitioning(<br> pyarrow.schema([("CustomerID", pyarrow.int16())]))); |
The result of executing this is an error message:

Given that there are 19,119 different customers, this would theoretically have created that many separate folders. Even the maximum of 1,024 is quite a lot of files and likely more than most people would ever want.
One alternative for partitioning is to create an artificial partitioning value within the data set. The following query contains this extra value:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT ROW_NUMBER() OVER (ORDER BY SUM(SalesOrderHeader.SubTotal) DESC) AS OverallRank, SalesOrderHeader.CustomerID, SUM(SalesOrderHeader.SubTotal) AS SalesTotal, AVG(SalesOrderHeader.SubTotal) AS AvgSaleAmount, MIN(SalesOrderHeader.SubTotal) AS MinSaleAmount, MAX(SalesOrderHeader.SubTotal) AS MaxSaleAmount, COUNT(*) AS CustomerOrderCount, CAST(CustomerID % 10 AS TINYINT) + 1 AS PartitionValue FROM Sales.SalesOrderHeader GROUP BY SalesOrderHeader.CustomerID ORDER BY SUM(SalesOrderHeader.SubTotal) DESC; |
The last column in the query applies modulus 10 math to the CustomerId, which results in a value from 1-10. Updating the query in the Python script allows us to choose the new partition column, like this:
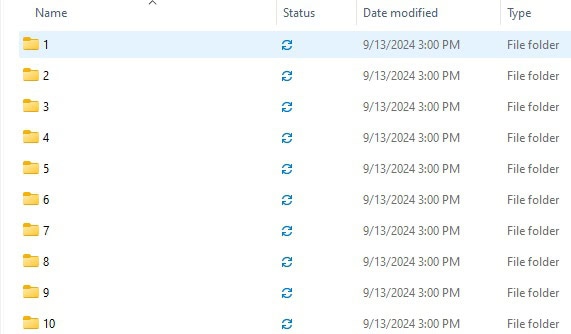
This strategy allows for customized partitioning that controls the output size and shape based on whatever criteria we can dream up!
It is important to note that the Parquet file format is not intended for small files. If a file has less than millions of rows of data, then the bloat of extra files may result in an overall larger storage footprint. Like columnstore indexes, this file format is intended for larger data that compresses well. Do not consider splitting up Parquet files unless row counts are at least into the millions, if not more, and only if file movement processes are bottlenecked by file size constraints.
File-Tuning Rowgroup Size
Unlike many highly compressed file formats, Parquet allows for fine-tuning of its compression details. In addition to compression algorithm, which was demonstrated earlier, the size of rowgroups may be customized.
Generally speaking, the Parquet format performs more optimally with larger rowgroup sizes. Like with file partitioning, this setting should only be adjusted if a reason to do so arises. Fine-tuning compression mechanics with no real-world reason to do so can cause as much harm as good.
The following lines of code will create new Parquet files using specified row group sizes, as well as the default:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
pyarrow.parquet.write_table(table, FILEPATH + 'customer_totals_parameters_1048576.parquet', row_group_size = 1048576, compression="snappy"); pyarrow.parquet.write_table(table, FILEPATH + 'customer_totals_parameters_1024.parquet', row_group_size = 1024, compression="snappy"); pyarrow.parquet.write_table(table, FILEPATH + 'customer_totals_parameters_10000.parquet', row_group_size = 10000, compression="snappy"); pyarrow.parquet.write_table(table, FILEPATH + 'customer_totals.parquet', compression="snappy"); |
The parameter row_group_size is the maximum number of rows that can be contained within a single rowgroup. The default is 10242 (1,048,576) or the entire table, if the table contains less rows than this. When executed, the following shows the resulting file sizes:

The first and last file have the same size, which helps to confirm that the default row group size is, in fact, 1,048,576 rows. The small row group size of 1,024 required slightly more space, which is expected. Smaller row groups will benefit less from the various compression algorithms that are optimized based on repeated data values.
Interestingly enough, the setting of 10,000 rows for the maximum row group size resulted in a slightly smaller file size. For the purposes of this demonstration, I would not put much value on this result. It is an excellent example of how tweaking parameters can adjust output details, but it is very difficult to determine if this is a meaningful difference or a random fluctuation based on minutia of the Parquet file format. Ultimately, a difference of 4kb is only 1% of the total file size. I’d be hesitant to draw a meaningful conclusion based on that compression behavior. Declaring instant success and setting the maximum row group size to 10,000 for this or other file generation processes would be a misguided idea and ultimately create confusion over why anyone would really want to do that.
More info on the write_table method can be found here: https://arrow.apache.org/docs/python/generated/pyarrow.parquet.write_table.html
Apache maintains excellent documentation on this and related topics, so feel free to read up on their web pages to learn more about what else is available for your use from them.
Reading Data from Parquet Files
Now that some parquet files have been created, they can be used in any service where highly compressed analytic data is appropriate. For this short demonstration, Azure Databricks will be used as the target for some of the files that we generated. Details are being kept as simple as possible as this is not a guide on Databricks, but instead a guide on file generation and usage.
The following is a Databricks service created in Azure using the default settings:
Once created, we can navigate to the workspace, import some of our Parquet files, and show how easily they can be used, once available. From here, I created a separate schema and volume to store this test data:
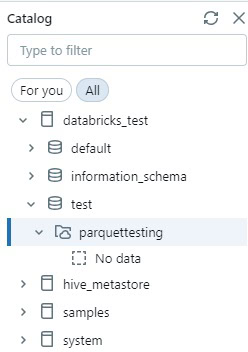
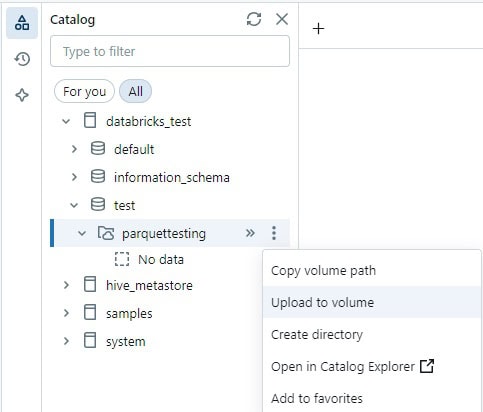
From here, I choose the “Upload to volume” option to directly import four of the Parquet files that we previously created:
Once in this menu, the four most recently created Parquet files are selected for upload: 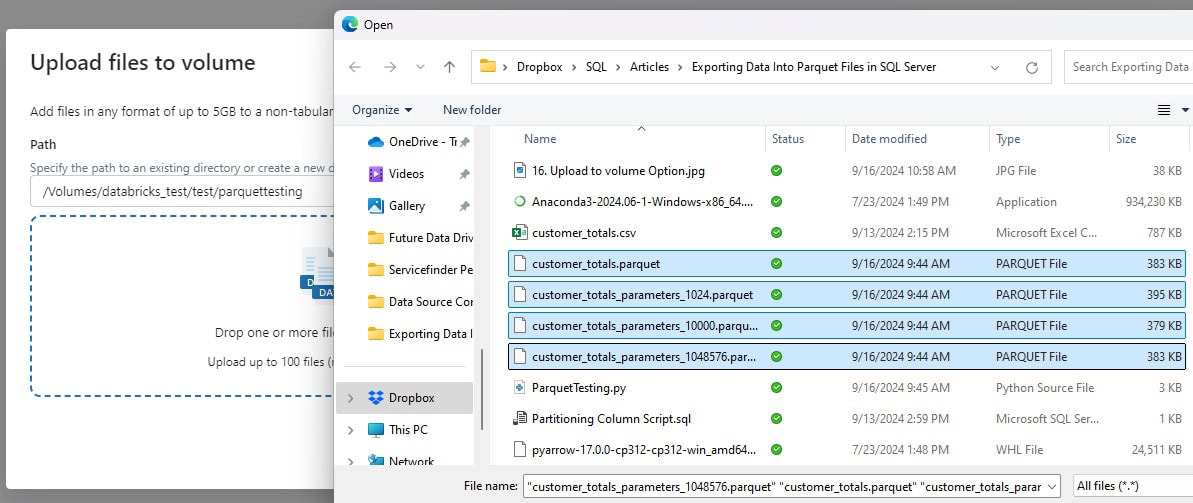
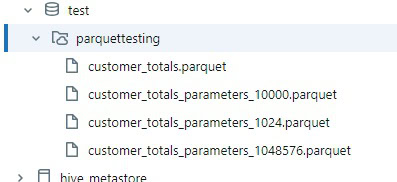
Within a few seconds, the upload completes the and the parquet files are now stored in Databricks and ready for use:
With the data now readily available, I will navigate to the SQL Editor and choose to create a new query:
SQL is used as this will be the most accessible and easiest way for a database professional to query this data. To sample the newly uploaded data, I create a LIMIT 100 query that reads directly from the Parquet file:
|
1 |
SELECT *<br>FROM read_files('/Volumes/databricks_test/test/parquettesting/customer_totals.parquet')<br>LIMIT 100; |
The results take a bit of time to generate as reading directly from a Parquet file is not as fast as reading from a table:
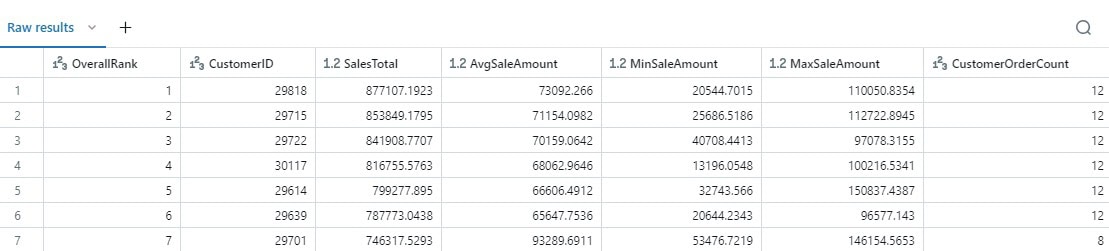
Happy with the results, we can write a query to create a table and copy the data from Parquet into it.
|
1 2 3 4 |
CREATE TABLE CustomerTotals AS SELECT * FROM read_files('/Volumes/databricks_test/test/parquettesting/customer_totals.parquet'); |
Once created, the newly created table can be quickly confirmed via the UI:
Lastly, the table can be queried to pull data as needed:
|
1 2 3 |
SELECT * FROM customertotals WHERE CustomerID = 29818; |
With the data stored in a permanent table in Databricks, the data is returned quickly:
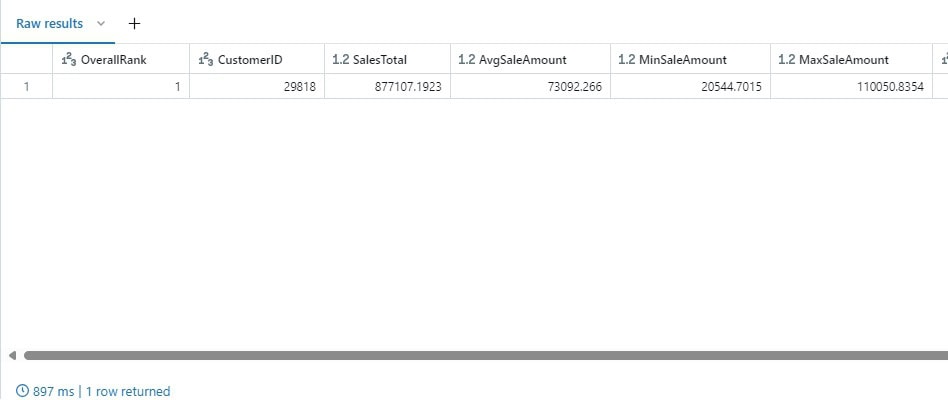
There was definitely a warm-fuzzy feeling in validating that the Parquet files we created earlier in this article can be imported and used in another application as they are intended to.
The steps taken to read this data were intentionally manual and relied heavily on the UI to return results. Any real-world process would be heavily automated. For example, a process that manages regularly generated analytic data might look something like this:
- Generate Parquet files manually from SQL Server each evening.
- Copy all new Parquet files into Azure blob storage.
- Read all Parquet files that were uploaded and not yet previously processed.
- Load the data using a standard data movement processes.
Azure Synapse or Fabric could also be targets for this data, as well. As with generating Parquet files, there is a great deal of flexibility here and these data files can be consumed practically anywhere.
Python could even be used to read data from the Parquet files in an environment where Parquet is not a native file format.
Conclusion
This article took a handful of use-cases for Parquet files, how to customize and use them, and put those ideas into practice. For every line of code and every visual demonstration of an idea here, there are a thousand more that can be brought to life and used to solve real-world problems.
If you have built useful processes using Python, feel free to share them with me and the data community! I love seeing the tools that database practitioners create and use. What may be simply a run-of-the-mill project you created to solve a day-to-day problem may be the magic solution that another data engineer has been wishing for!





Load comments