
- In-Memory OLTP – Part 1: Monitoring
- In-Memory OLTP – Part 2: Memory Optimized Tables
- In-Memory OLTP – Part 3: Row Structure and Indexes
As we continue this series of articles about In-Memory OLTP, we now come to the task of explaining the Indexing options. With Memory-Optimized Tables (MOT), Indexes are rather different to what we’ve been used to with traditional disk tables. To recap, there are two possible types of MOTs:
- Durable – Where the data is persistent
- Non-Durable – Where the data is lost upon a server restart occurence
Both of these types of table are different from disk based tables, and this is not just because the data is stored in memory. In order to achieve the best performance, the data rows aren’t stored on pages as they are in disk-based tables. In previous versions of SQL Server, the DBCC PINTABLE command allowed a traditional disk table to be kept in memory. If the MOT were merely the same as a disk table, what would be the advantage in spending time creating the In-Memory OLTP feature? Is this the same?
The answer, of course, is “no”. Memory-Optimized Tables are internally different from traditional disk tables. To merely have the data stored in memory is not sufficient to gain significant performance. You no longer need the overhead of the block-level caching of disk data. The way to deal with disk-based data, where blocks are addressed, is different from memory-based data, where bytes are addressed. By redesigning the whole stack , MOTs are structured in such a way as to deliver the best performance.
Row structure in details
In MOTs, rows are stored in memory heaps and, unlike disk-based tables, the data of a single table is not held in close proximity. This means that the rows are likely to be spread in memory, without a logical order.
The general structure for a MOT Row is:

You can see that there are two distinct general areas: the Header and the Payload. As mentioned, the row structure for a MOT is different from disk-based tables in order to achieve the best performance by taking advantage of the table being memory-based.
The Payload area contains the table columns, but what about the row header? Let’s take a deeper look:

- Begin and End Timestamp – In short, those 8-byte fields are going to store, respectively, the timestamp for the transaction that created the row and the transaction that deleted the row. But this is not that simple, there are some important details:
- The timestamp is that point in time when the transaction finishes. For this reason, both the Begin and End Timestamps are temporarely holding the “Global Transaction ID”, which is a unique incremental value that identifies the transaction. The “Global Transaction ID” is recycled when the instance is restarted.
- When a row is created, there’s (obviously) no “End Timestamp”, this way the infinity (â) value is set.
- Not only does a DELETE statement remove a row, but so also does an UPDATE. When a row is changed, a DELETE followed by an INSERT is performed under the hood.
- Statement ID – This is a 4-byte field that stores the unique ID of the statement that generated the row.
- IndexLink Count – As its name suggests, this 2-byte field stores the number of Indexes referencing this row. Every table must have at least one index, which is required in order to link its rows.
- Pointers – The remaining portion of the row header is filled with “Index Pointers”. The number of pointers is the same as the number of indexes referencing the row, which is tracked by the “IndexLink Count” field. In SQL Server 2014, a table could not be modified, and this was also true of its indexes; it wasn’t possible to change, remove or add indexes to a MOT. The reason behind this is that index pointers were part of the row structure. Happily, this limitation was removed on SQL Server 2016.
Indexes on Memory-Optimized Tables
An Index is a structure that can provide performance miracles. Indexes are well known by everyone, but Memory-Optimized Tables are special, so indexes for In-Memory OLTP are also…special!
Indexes are used as entry points for memory-optimized tables, based on the fact that indexes are a requirement to link together the rows for a MOT. Currently, there’s a limit of eight indexes in total per Memory-Optimized Table.
Operations that are targeting indexes for MOTs are never logged or written to the disk at all. This means that the index is based on its definition and the in-memory data for its respective table. On every restart of the instance, the index is entirely rebuilt in-memory, based on its definition.
There are two kinds of indexes that are supported for both Durable and Non-Durable Memory-Optimized Tables:
- Hash Indexes
- Nonclustered Indexes (a.k.a Range Indexes)
Hash Indexes
A hash index consists of a collection of buckets organized in an array of pointers. The name “Hash Index” came up because this kind of index applies a deterministic “hash function” over the index key value. This kind of index is efficient for pointer-lookup operations.
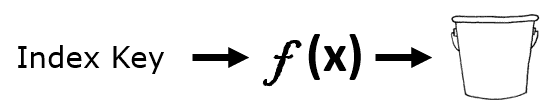
The bucket where the pointer for a row will be located is dependent on the hash generated by the function. Keys that result in the same hash value will be accessed from the same pointer and linked in a chain.
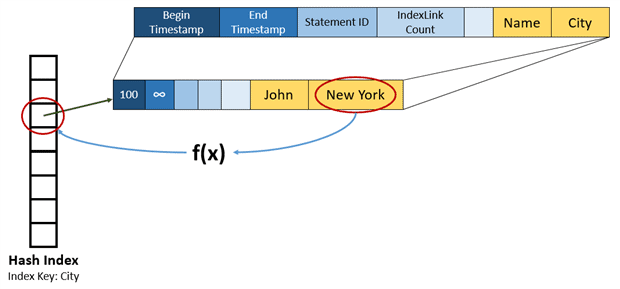
The following example shows a representation of a Hash Index on the “City” column. The hash function receives the value “New York” and generates a hash which identifies its respective bucket.
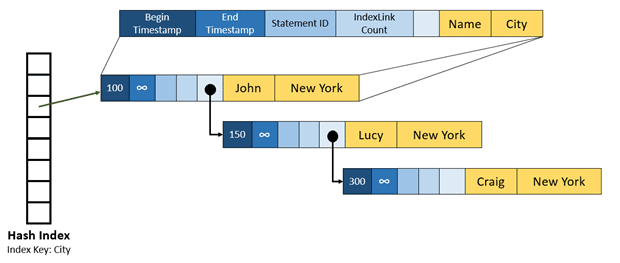
By adding more rows with the same value in the index key, a chain will be created. In the following example, two new rows were added, one for Lucy and the other one for Craig. Both have “New York” as city, resulting in the same hash value. For this reason, those rows are now part of an index chain.
This could be made more complex by just adding additional indexes. For example, we could add an index using the name as ‘Index Key’. By doing this, another Array of buckets would be created and all the rows would have one more index pointer to link the rows in a chain, resulting in two pointers per row.
When a Hash Index is being planned, a rather tricky decision needs to be made as to the number of buckets. This decision is even more critical if you are using SQL Server 2014, where there’s no option to change the index after its creation – which can only be done within the CREATE TABLE statement, in this case.
There’re two possible problems: You can opt for a very high number of buckets or a very low number. Both options are bad, but the side effects are different. So consider well before setting the number of buckets.
As I’ve explained already, when a row is inserted in a table with a hash index, a hash function gets the value of the index key and produces a hash that will point the row to an specific bucket. Knowing this, we may speculate as to what happens if we have more “unique values” than available buckets? Here is the danger. In this situation, that the Hash Function will start to produce the same hash for different values, which will thereby cause Hash collisions and the mixing of different key values in its linked list, which is not ideal. Microsoft assumes that it’s acceptable to have hash collisions on up to 30% of the buckets, but no more than this percentage, otherwise performance problems could affect operations targeting the table.
On the other hand, it is not a good idea to set a very high number of buckets. In order to maintain each bucket, 8-bytes of memory are used. Add to this the fact that the number of buckets is always rounded-up to the next power of two, meaning that if you set a BUCKET_COUNT=10, a number of 16 buckets will be created, in fact. From here you can see the problem: by creating more buckets then needed, more memory will be allocated… using up memory for no good purpose.
In summary, the goal is to avoid setting too low or a too high a value for the BUCKET_COUNT parameter when a Hash Index is being created. Incidentally, we can create a Hash Index once the table is created, or take advantage of the ALTER TABLE command (SQL Server 2016+) after the table creation.
The following example shows how to create a Hash Index within the CREATE TABLE statement:
|
1 2 3 4 5 |
CREATE TABLE Customers ( ID INT NOT NULL, NAME VARCHAR(10) NOT NULL, PRIMARY KEY NONCLUSTERED HASH (NAME) WITH ( BUCKET_COUNT = 124 ) ) WITH ( MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_AND_DATA ) |
If we need to add a new index after the table has been created, you can use the following command, which is supported from In-Memory OLTP from SQL Server 2016:
|
1 2 3 |
ALTER TABLE [MemProduct] ADD INDEX idx_hash_Ident HASH (ID) WITH (BUCKET_COUNT = 64); |
Nonclustered Indexes
The name is the same, but the Nonclustered Index for Memory-Optimized Tables is different from what we are used to in traditional disk tables. The Nonclustred Indexes for MOTs are based on a structure called Bw-tree, a lock-and-latch-free variation of the already known B-tree. This kind of index is a good option when the objective is to search your rows based on a range of values. The following picture shows a logical view of a Bw-Tree:
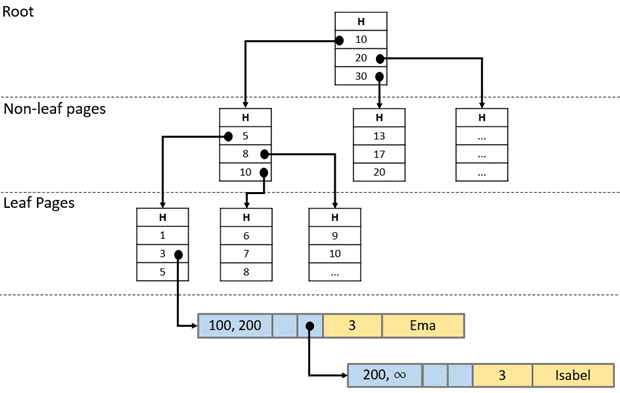
As you can see, the structure of a Bw-Tree is almost the same of a B-Tree. Each page has a set of ordered values with a pointer to the next level. In the intermediate level, the pointers are indicating pages and in the leaf level, the pointers are referencing data rows.
If the value for an index key is the same for multiple rows, a chain is created just the same way as on Hash Indexes. You can see in the example that ‘Ema’ and ‘Isabel’ have the same Index Key value (3), so both rows are part of a linked list.
Internally, a Bw-Tree relies in a structure called Page Mapping Table (PMT) to link its pages. The PMT is organized by Page IDs (PID), which are utilized to refer the physical memory address of each index page.
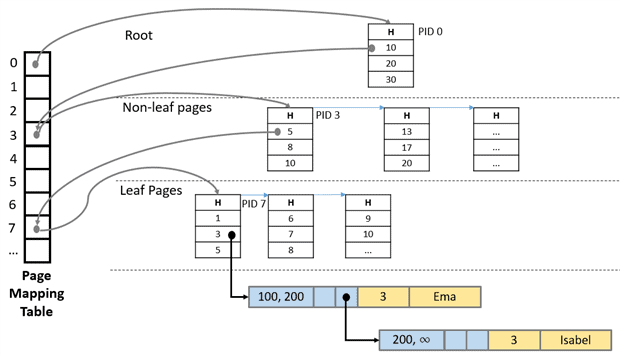
A page pointer contains a Page ID value from the Page Mapping Table. The PMT will, at that point, map the PID to the corresponding Physical Memory Address of the referred page. This rule is not true for the leaf level pages, where the rows are referenced directly by their physical memory address, instead of using the PMT.
If you need to change an index page, SQL Server will discard the old page and create a new one containing the differences. This way, the Page Mapping Table will be updated, changing the physical memory address that corresponds for the PID of the “changed” index page. Also, the leaf-level pages are behaving differently: When an INSERT or DELETE command affects a key value of a leaf level index page, a delta record is created to reflect this change. After that, the Mapping Page Table will update its pointer to the physical address of this delta page, which in its turn, will point to the original page. The “delta page” strategy forces SQL Server to combine the original page with all the deltas in order to answer a request, which will make the operation a little more expensive – however the gains in using this strategy make it worth this “penalty”.
Still on the topic of delta records, there’s a known limit of six deltas. Once this value is hit, SQL Server will start a consolidation process where the page will be rebuilt, taking into account all the changes tracked by the delta records. This will generate a new page with a different physical memory address, mapped by the same (old) Page ID.
The case of the “six delta records” is a mechanism to ensure good performance, but there’s another limit related to the index page structure. Once an index page reaches 8Kb, a page split will occur in order to accommodate new key values. In other hands, when a page has less than 10% of the maximum page size (8Kb) or a single row, a page merge operation will be triggered, joining two adjacent index pages in a single one.
As an example of the Hash Indexes, we can create memory-optimized Nonclustered Indexes when the table is created, or we can take adavantage of the ALTER TABLE support that was added on SQL Server 2016:
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE [dbo].[MemProduct] ( [ID] [int] IDENTITY(1,1) NOT NULL, [Product] [nvarchar](100) COLLATE Latin1_General_CI_AS NOT NULL, [Price] [decimal](18, 2) NOT NULL, PRIMARY KEY NONCLUSTERED ( [ID] ASC ) )WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA ) |
Here is an example on how to add a nonclustered index to an already existing Memory-Optimized Table:
|
1 2 3 4 |
ALTER TABLE [MemProduct] ADD INDEX idx_nc_Price NONCLUSTERED (Price ASC) go |
Dealing with indexes
The way to CREATE, DROP, and ALTER an index on Memory-Optimized Tables is to use the ALTER TABLE command. You can find more information about the syntax here.
Conclusion
In this article we considered some of the decisions that have to be made when setting up the indexes for memory-optimised tables, and described some of the relevant details of the row structure and indexes for Memory-Optimized Tables, as well as how to use T-SQL to create them.
Load comments