
Index selection is one of the most important techniques used in query optimization. By using the right indexes, SQL Server can speed up your queries and dramatically improve the performance of your applications. In this article I will show you how SQL Server selects indexes, how you can use this knowledge to provide better indexes, and how you can verify your execution plans to make sure these indexes are correctly used.
This article also includes sections about the Database Engine Tuning Advisor and the Missing Indexes feature, which will show how you can use the Query Optimizer itself to provide index tuning recommendations. However, it is important to emphasize that, no matter what index recommendations these tools give, it is ultimately up to the database administrator or developer to do their own index analysis and finally decide which of these recommendations to implement. Also, since we’ll be covering these tools mainly from the point of view of the Query Optimizer, you should use Books Online to obtain more in-depth information regarding using these features.
Finally, the sys.dm_db_index_usage_stats DMV will be introduced as a tool to identify existing indexes which your queries may not be using. Indexes that are not being used will provide no benefit to your databases, but will use valuable disk space and slow your update operations, and so they should be considered for removal.
Note:
The example SQL queries in this article are all based on the AdventureWorks database, and all code has been tested for both the SQL Server 2008 and SQL Server 2008 R2 versions of these databases. Note that these sample databases are not included in your SQL Server installation by default, but can be downloaded from the CodePlex web site. You need to download the family of sample databases for your version, either SQL Server 2008 or SQL Server 2008 R2. During installation you may choose to install all the databases or at least the AdventureWorks and AdventureWorksDW (which is needed at other points in the book beyond this sample).
You should bear in mind that learning how to manage indexes and understand what makes them useful (or not) is a long road, and you’ll be taking just the first few practical steps here. The skills you gain from this article will put you in good stead, but I would urge you to do some further reading around the subject.
Introduction
As mentioned in Chapter 2 of the book, (Which discusses The Execution Engine), SQL Server can use indexes to perform seek and scan operations. Indexes can be used to speed up the execution of a query by quickly finding records without performing table scans; by delivering all the columns requested by the query without accessing the base table (i.e. covering the query, which I’ll return to in a moment), or by providing sorted order, like in queries with GROUP BY, DISTINCT or ORDER BY clauses.
Part of the Query Optimizer’s job is to determine if an index can be used to evaluate a predicate in a query. This is basically a comparison between an index key and a constant or variable. In addition, the Query Optimizer needs to determine if the index covers the query; that is, if the index contains all the columns required by the query (referred to as a “covering index”). It needs to confirm this because, as you’ll hopefully remember, a non-clustered index usually contains only a subset of the columns of the table.
SQL Server can also consider using more than one index, and joining them to cover all the columns required by the query (index intersection). If it’s not possible to cover all of the columns required by the query, then the query optimizer may need to access the base table, which could be a clustered index or a heap, to obtain the remaining columns. This is called a bookmark lookup operation (which could be a Key Lookup or an RID Lookup, as explained in Chapter 2 of the book. However, since a bookmark lookup requires random I/O, which is a very expensive operation, using both an index seek and a bookmark lookup can only be effective for a relatively small number of records.
Also keep in mind that although one or more indexes can be used, it does not mean that they will be finally selected in an execution plan, as this is always a cost-based decision. So, after creating an index, make sure you verify that the index is, in fact, used in a plan (and of course, that your query is performing better, which is probably the primary reason why you are defining an index!) An index that it is not being used by any query will just take up valuable disk space, and may negatively impact the performance of update operations without providing any benefit. It is also possible that an index which was useful when it was originally created is no longer used by any query. This could be as a result of changes in the database schema, the data, or even the query itself. To help you avoid this frustrating situation, the last section in this chapter will show you how you can identify which indexes are no longer being used.
The Mechanics of Index Selection
In a seek operation, SQL Server navigates throughout the B-tree index to quickly find the required records without the need for an index or table scan. This is similar to using an index at the end of a book to find a topic quickly, instead of reading the entire book. Once the first record has been found, SQL Server can then scan the index leaf level forward or backward to find additional records. Both equality and inequality operators can be used in a predicate, including =, <, >, <=, >=, <>, !=, !<, !>, BETWEEN, and IN. For example, the following predicates can be matched to an index seek operation if there is an index on the specified column, or a multi-column index with that column as a leading index key:
- ProductID = 771
- UnitPrice < 3.975
- LastName = ‘Allen’
- LastName LIKE ‘Brown%’
As an example, look at the next query, which uses an index seek operator and produces the plan in Figure 1-1.
|
1 2 3 |
SELECT ProductID, SalesOrderID, SalesOrderDetailID FROM Sales.SalesOrderDetail WHERE ProductID = 771 |
Listing 1-1

Figure 1 – Plan with Index Seek
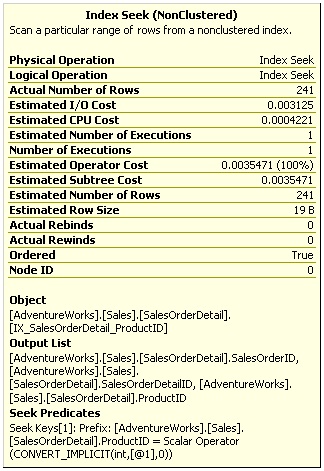
Figure 1-2: Index Seek Operator Properties
The SalesOrderDetail table has a multi-column index with ProductID as the leading column. The Index Seek operator properties, which you can see in Figure 1-2, include the following seek predicate on the ProductID column, which shows that SQL Server was effectively able to use the index to seek on the ProductID column:
|
1 |
Seek Keys[1]: Prefix: [AdventureWorks].[Sales]. [SalesOrderDetail].ProductID = Scalar Operator (CONVERT_IMPLICIT(int,[@1],0)) |
Listing 1-2
An index cannot be used to seek on some complex expressions, expressions using functions, or strings with a leading wildcard character, like in the following predicates:
- ABS(ProductID) = 771
- UnitPrice + 1 < 3.975
- LastName LIKE ‘%Allen’
- UPPER(LastName) = ‘Allen’
Compare the following query to the previous example; by adding an ABS function to the predicate, SQL Server is no longer able to use an Index Seek operator, and instead chooses to do an Index Scan as shown on the plan on Figure 1-3.
|
1 2 3 |
SELECT ProductID, SalesOrderID, SalesOrderDetailID FROM Sales.SalesOrderDetail WHERE ABS(ProductID) = 771 |
Listing 1-3

Figure 1-3: Plan with an Index Scan
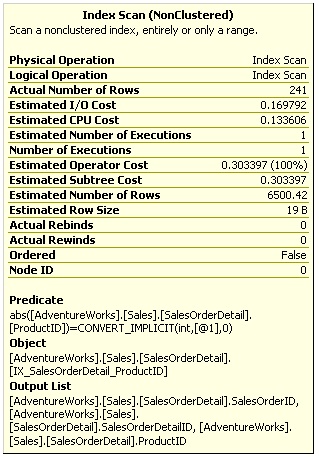
Figure 1-4: Index Scan Operator Properties
Note that in Figure 1-4, the following predicate is, however, still evaluated on the Index Scan operator:
|
1 2 |
abs([AdventureWorks].[Sales].[SalesOrderDetail]. [ProductID]) =CONVERT_IMPLICIT(int,[@1],0) |
Listing 1-4
In the case of a multi-column index, SQL Server can only use the index to seek on the second column if there is an equality predicate on the first column. So SQL Server can use a multi-column index to seek on both columns in the following cases, supposing that a multi-column index exists on both columns in the order presented:
- ProductID = 771 AND SalesOrderID > 34000
- LastName = ‘Smith’ AND FirstName = ‘Ian’
That being said, if there is no equality predicate on the first column, or if the predicate can not be evaluated on the second column, as is the case in a complex expression, then SQL Server may only be able to use a multi-column index to seek on just the first column, like in the following examples:
- ProductID = 771 AND ABS(SalesOrderID) = 34000
- ProductID < 771 AND SalesOrderID = 34000
- LastName > ‘Smith’ AND FirstName = ‘Ian’
However, SQL Server is not able to use a multi-column index for an Index Seek in the following examples, as it is not even able to search on the first column:
- ABS(ProductID) = 771 AND SalesOrderID = 34000
- LastName LIKE ‘%Smith’ AND FirstName = ‘Ian’
Finally, take a look at the following query, and the Index Seek operator properties in Figure 1-5:
|
1 2 3 |
SELECT ProductID, SalesOrderID, SalesOrderDetailID FROM Sales.SalesOrderDetail WHERE ProductID = 771 AND ABS(SalesOrderID) = 45233 |
Listing 1-5.
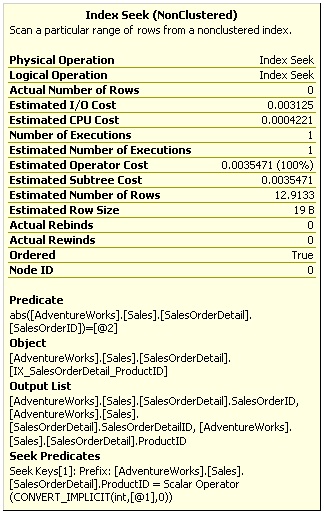
Figure 1-5: Index Seek Operator Properties
The seek predicate is using only the ProductID column as shown here:
|
1 2 |
Seek Keys[1]: Prefix: [AdventureWorks].[Sales]. [SalesOrderDetail].ProductID = Scalar Operator (CONVERT_IMPLICIT(int,[@1],0) |
Listing 1-6.
An additional predicate on the SalesOrderID column is evaluated like any other scan predicate, as listed in:
|
1 |
abs([AdventureWorks].[Sales].[SalesOrderDetail]. [SalesOrderID])=[@2] |
Listing 1-7.
So in summary, this shows that, as we expected, SQL Server was able to perform a seek operation on the ProductID column but, because of the use of the ABS function, was not able to do the same for SalesOrderID. The index was used to navigate directly to find the rows that satisfy the first predicate, but then had to continue scanning to validate the second predicate.
The Database Engine Tuning Advisor
Currently, all major commercial database vendors include a physical database design tool to help with the creation of indexes. However when these tools were first developed, there were just two main architectural approaches considered for how these tools should recommend indexes. The first approach was to build a stand-alone tool with its own cost model and design rules. The second approach was to build a tool that could use the query optimizer cost model.
A problem with building a stand-alone tool is the requirement for duplicating the cost module. On top of that, having a tool with its own cost model, even if it’s better than the optimizer’s cost model, may not be a good idea because the optimizer clearly still chooses its plan based on its own model.
The second approach, using the query optimizer to help in physical database design, has been proposed in the database research community as far as back as 1988. Since it’s the optimizer which chooses the indexes for an execution plan, it makes sense to use the optimizer itself to help find which missing indexes would benefit existing queries. In this scenario, the physical design tool would use the optimizer to evaluate the cost of queries given a set of candidate indexes. An additional benefit of this approach is that, as the optimizer cost model evolves, any tool using its cost model can automatically benefit from it.
SQL Server was the first commercial database product to include a physical design tool, in the shape of the Index Tuning Wizard which shipped with SQL Server 7.0, and which was later replaced by the Database Engine Tuning Advisor (DTA) in SQL Server 2005. Both tools use the query optimizer cost model approach and were created as part of the AutoAdmin project at Microsoft, the goal of which was to reduce the total cost of ownership (TCO) of databases by making them self-tuning and self-managing. In addition to indexes, the DTA can help with the creation of indexed views and table partitioning.
However, creating real indexes in a DTA tuning session is not feasible; its overhead could impact operational queries and degrade the performance of your database. So how does the DTA estimate the cost of using an index that does not yet exist? Actually, even during a regular query optimization, the Query Optimizer does not use actual indexes to estimate the cost of a query. The decision of whether to use an index or not depends only on some metadata and the statistical information regarding the columns of the the index. Index data itself is not needed during query optimization, but of course will be required during query execution if the index is chosen.
So, to avoid creating indexes during a DTA session, SQL Server uses a special kind of indexes called hypothetical indexes, which were also used by the Index Tuning Wizard. As the name implies, hypothetical indexes are not real indexes; they only contain statistics and can be created with the undocumented WITH STATISTICS_ONLY option of the CREATE INDEX statement. You may not be able to see these indexes during a DTA session because they are dropped automatically when they are no longer needed, but you can see the CREATE INDEX WITH STATISTICS_ONLY and DROP INDEX statements if you run a SQL Server Profiler session to see what the DTA is doing.
Let’s take a quick tour to some of these concepts; To get started, create a new table on the AdventureWorks database:
|
1 2 |
SELECT * INTO dbo.SalesOrderDetail FROM Sales.SalesOrderDetail |
Listing 1-8.
Copy the following query and save it to a file:
|
1 2 |
SELECT * FROM dbo.SalesOrderDetail WHERE ProductID = 897 |
Listing 1-9.
Open a new DTA session, and you can optionally run a SQL Server Profiler session if you want to inspect what the DTA is doing. On the Workload File option, select the file containing the SQL statement that you just created with Listing 1-9, and specify AdventureWorks as both the database to tune and the database for workload analysis. Click the Start Analysis button and, when the DTA analysis finishes, run this query to inspect the contents of the msdb..DTA_reports_query table:
|
1 |
SELECT * FROM msdb..DTA_reports_query |
Listing 1-10.
Running that query shows the following output, edited for space:
|
1 2 3 |
StatementString CurrentCost RecommendedCost ------------------------------------------- ----------- --------------- SELECT * FROM dbo.SalesOrderDetail WHERE... 1.2434 0.00328799 |
Listing 1-11
Notice that this returns information like the query that was tuned, as well as the current and recommended cost. The current cost, 1.2434, is easy to obtain by directly requesting an estimated execution plan for the query as shown in Figure 1-6 (as is discussed in Chapter 2 of the book).
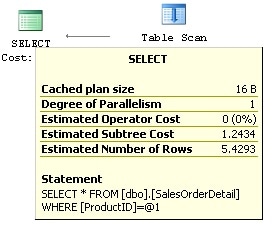
Figure 1-6: Plan showing Total Cost
Since the DTA analysis was completed, the required hypothetical indexes were already dropped. To now obtain the indexes recommended by the DTA, click on the Recommendations tab and look at the Index Recommendations section, where you can find the code to create any recommended index by then clicking on the Definition column. In our example, it will show the following code:
|
1 2 3 4 5 |
CREATE CLUSTERED INDEX [_dta_index_SalesOrderDetail_c_5_ 1915153868__K5] ON [dbo].[SalesOrderDetail] ( [ProductID] ASC )WITH (SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [PRIMARY] |
Listing 1-12.
In the next statement and for demonstration purposes only, I will go ahead and create the index recommended by the DTA but, instead of a regular index, I will create it as a hypothetical index by adding the WITH STATISTICS_ONLY clause:
|
1 2 |
CREATE CLUSTERED INDEX cix_ProductID ON dbo.SalesOrderDetail(ProductID)WITH STATISTICS_ONLY |
Listing 1-13.
You can validate that a hypothetical index was created by running the next query:
|
1 2 3 |
SELECT * FROM sys.indexes WHERE object_id = object_id('dbo.SalesOrderDetail') AND name = 'cix_ProductID' |
Listing 1-14.
The output is show next below; note that the is_hypothetical field shows that this is, in fact, just a hypothetical index:
|
1 2 3 |
object_id name index_id type type_desc is_hypothetical ---------- ------------- -------- ---- --------- --------------- 1915153868 cix_ProductID 3 1 CLUSTERED 1 |
Listing 1-15.
Remove the hypothetical index by running this statement:
|
1 |
DROP INDEX dbo.SalesOrderDetail.cix_ProductID |
Listing 1-16.
Finally, implement the DTA recommendation, this time as a regular clustered index:
|
1 |
CREATE CLUSTERED INDEX cix_ProductID ON dbo.SalesOrderDetail(ProductID) |
Listing 1-17.
After implementing the recommendation and running the query again, the clustered index is in fact now being used by the Query Optimizer. This time, the plan shows a clustered index seek operator and an estimated cost of 0.0033652, which is very close to the recommended cost listed previously when querying the msdb..DTA_reports_query table.
Finally, drop the table you just created by running the following statement:
|
1 |
DROP TABLE dbo.SalesOrderDetail |
Listing 1-18.
The Missing Indexes Feature
SQL Server does provide a second approach that can help you to find useful indexes for your existing queries. Although not as powerful as the DTA, this option, called the Missing Indexes feature, does not require the database administrator to decide when tuning is needed, to explicitly identify what workload represents the load to tune, or to run any tool. This is a lightweight feature which is always on and, same as the DTA, was also introduced with SQL Server 2005. Let’s take a look at what it does.
During optimization, the Query Optimizer defines what the best indexes for a query are, and if these indexes don’t exist, it will make this index information available in the XML plan for a particular plan (as well as the graphical plan, as of SQL Server 2008). Alternatively, it will aggregate this information for queries optimized since the instance was started, and make it all available on the sys.dm_db_missing_index DMV. Note that, just by displaying this information, the Query Optimizer is not only warning you that it might not be selecting an efficient plan, but it is also showing you which indexes may help to improve the performance of your query. In addition, database administrators and developers should be aware of the limitations of this feature, as described on the Books Online entry ‘Limitations of the Missing Indexes Feature‘.
So, with all that in mind, let’s take a quick look to see how this feature works. Create the dbo.SalesOrderDetail table on the AdventureWorks database by running the following statement:
|
1 2 3 |
SELECT * INTO dbo.SalesOrderDetail FROM sales.SalesOrderDetail |
Listing 1-19.
Run this query and request a graphical or XML execution plan:
|
1 2 |
SELECT * FROM dbo.SalesOrderDetail WHERE SalesOrderID = 43670 AND SalesOrderDetailID > 112 |
Listing 1-20.
This query could benefit from an index on the SalesOrderID and SalesOrderDetailID columns, but no missing indexes information is shown this time. One limitation of the Missing Indexes feature, which this example has revealed, is that it does not work with a trivial plan optimization. You can verify that this is a trivial plan by looking at the graphical plan properties, shown as Optimization Level TRIVIAL, or by looking at the XML plan, where the StatementOptmLevel is shown as TRIVIAL.
You can avoid the trivial plan optimization in several ways, as I’ll explain in Chapter 5 of the book (The Optimization Process), but (for now, you’ll just have to take it on faith. In our case, we’re just going to create a non-related index by running the following statement:
|
1 |
CREATE INDEX IX_ProductID ON dbo.SalesOrderDetail(ProductID) |
Listing 1-21.
What is significant about this is that, although the index created will not be used by our previous query, the query no longer qualifies for a trivial plan. Run the query again, and this time the XML plan will contain the following entry.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<MissingIndexes> <MissingIndexGroup Impact="99.7137"> <MissingIndex Database="[AdventureWorks]" Schema="[dbo]" Table="[SalesOrderDetail]"> <ColumnGroup Usage="EQUALITY"> <Column Name="[SalesOrderID]" ColumnId="1" /> </ColumnGroup> <ColumnGroup Usage="INEQUALITY"> <Column Name="[SalesOrderDetailID]" ColumnId="2"/> </ColumnGroup> </MissingIndex> </MissingIndexGroup> </MissingIndexes> |
Listing 1-22.
The MissingIndexes entry in the XML plan can show up to three groups – equality, inequality, and included – and the first two are shown in this example using the ColumnGroup attribute. The information contained in these groups can be used to create the missing index; the key of the index can be built by using the equality columns, followed by the inequality columns, and the included columns can be added using the INCLUDE clause of the CREATE INDEX statement. SQL Server 2008 Management Studio can build the CREATE INDEX statement for you and, in fact, if you look at the graphical plan, you can see a Missing Index warning at the top including a CREATE INDEX command, as shown in Figure 1-7.
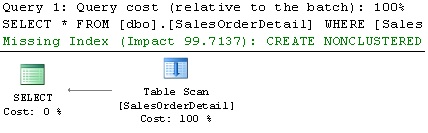
Figure 1-7: Plan with a Missing Index Warning.
Notice the impact value of 99.7137 – Impact is a number between 0 and 100 which gives you an estimate of the average percentage benefit that the query could obtain if the proposed index were available.
You can right-click on the graphical plan and select Missing Index Details to see the CREATE INDEX command that can be used to create this desired index, as shown next:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
/* Missing Index Details from SQLQuery1.sql - The Query Processor estimates that implementing the following index could improve the query cost by 99.7137%. */ /* USE [AdventureWorks] GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[SalesOrderDetail] ([SalesOrderID], [SalesOrderDetailID]) GO */ |
Listing 1-23.
Create the recommended index, after you provide a name for it, by running the following statement:
|
1 2 |
CREATE NONCLUSTERED INDEX IX_SalesOrderID_SalesOrderDetailID ON [dbo].[SalesOrderDetail]([SalesOrderID], [SalesOrderDetailID]) |
Listing 1-24.
If you run the query in Listing 1-21 again and look at the execution plan, this time you’ll see an index seek operator using the index you’ve just created, and both the Missing Index warning and the MissingIndex element of the XML plan are gone, as shown in Figure 1-8.
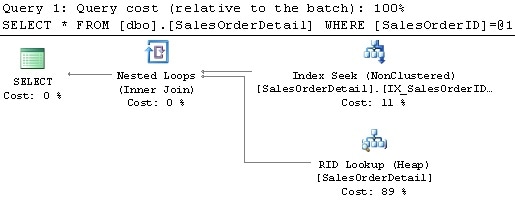
Figure 1-8: Plan without the Missing Index Warning.
Finally, remove the dbo.SalesOrderDetail table you’ve just created by running the following statement:
|
1 |
DROP TABLE dbo.SalesOrderDetail |
Listing 1-25.
Unused Indexes
I’ll end this article on indexes by introducing the functionality of the sys.dm_db_index_usage_stats DMV, which you can use to learn about the operations performed by your indexes, and is especially helpful in discovering indexes that are not used by any query or only minimally used. As we’ve already discussed, indexes that are not being used will provide no benefit to your databases, but will use valuable disk space, slow your update operations, and should be considered for removal.
The sys.dm_db_index_usage_stats DMV stores the number of seek, scan, lookup, and update operations performed by both user and system queries, including the last time each type of operation was performed. Keep in mind that this DMV, in addition to non-clustered indexes, will also include heaps, listed as index_id equal to 0, and clustered indexes, listed as index_id equal to 1. For the purposes of this section, you may want to just focus on non-clustered indexes, which include index_id values 2 or greater; since heaps and clustered indexes contain the table’s data, they may not even be candidates for removal in the first place.
By inspecting the user_seeks, user_scans and user_lookup values of your non-clustered indexes you can see how your indexes are being used, and you can inspect the user_updates values to see the amount of updates performed on the index. All of this information will help to give you a sense as to how useful an index actually is. Bear in mind that all I’ll be demonstrating is how to call up information from this DMV, and what sort of situations will trigger different updates to the information it returns. How you deploy the DMV, and how you react to the information it returns, is a task I leave to you.
Now for an example; run the following code to create a new table with a non-clustered index on it:
|
1 2 3 4 5 |
SELECT * INTO dbo.SalesOrderDetail FROM Sales.SalesOrderDetail CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.SalesOrderDetail(ProductID) |
Listing 1-26.
If you want to keep track of the values for this example, follow these steps carefully as every query execution may change the index usage statistics. When you run the following query, it will initially contain only one record, which was created because of table access performed when the index on Listing 1-26 was created:
|
1 2 3 4 5 |
SELECT DB_NAME(database_id) as database_name, OBJECT_NAME(s.object_id) as object_name, i.name, s.* FROM sys.dm_db_index_usage_stats s join sys.indexes i ON s.object_id = i.object_id AND s.index_id = i.index_id and s.object_id = object_id('dbo.SalesOrderDetail') |
Listing 1-27.
However, the values that we will be inspecting in this exercise, user_seeks, user_scans, user_lookups, and user_updates are all set to 0.
Now run the following query, let’s say, 3 times:
|
1 |
SELECT * FROM dbo.SalesOrderDetail |
Listing 1-28.
This query is using a Table Scan operator, so, if you rerun the code in Listing 1-27, the DMV will show the value 3 on the user_scans column. Note that the column index_id is 0, denoting a heap, and the name of the table is also listed (as a heap is just a table with no clustered index).
Run the next query, which uses an Index Seek, twice. After the query is executed, a new record will be added for the non-clustered index, and the user_seeks counter will show a value of 2:
|
1 2 |
SELECT ProductID FROM dbo.SalesOrderDetail WHERE ProductID = 773 |
Listing 1-29.
Now, run the following query 4 times, and it will use both Index Seek and RID Lookup operators. Since the user_seeks for the non-clustered index had a value of 2, it will be updated to 6, and the user_lookups value for the heap will be updated to 4:
|
1 2 |
SELECT * FROM dbo.SalesOrderDetail WHERE ProductID = 773 |
Listing 1-30.
Finally, run the following query once:
|
1 2 3 |
UPDATE dbo.SalesOrderDetail SET ProductID = 666 WHERE ProductID = 927 |
Listing 1-31.
Note that the UPDATE statement is doing an Index Seek and a Table Update, so user_seek will be updated for the index, and user_updates will be updated once for both the non-clustered index and the heap. This is the final output of the query in Listing 1-27 (edited for space):
|
1 2 3 4 |
name index_id user_seeks user_scans user_lookups user_updates ------------ -------- ---------- ---------- ------------ ------------ NULL 0 0 3 4 1 IX_ProductID 2 7 0 0 1 |
Listing 1-32.
Finally, drop the table you just created:
|
1 |
DROP TABLE dbo.SalesOrderDetail |
Listing 1-33.
Summary
This article explained how can you define the key of your indexes so that they are likely to be considered for seek operations, which can improve the performance of your queries by finding records more quickly. Predicates were analyzed in the contexts of both single and multi-column indexes, and we also covered how to verify an execution plan to validate that indexes were selected and properly used by SQL Server.
The Database Engine Tuning Advisor and the Missing Indexes feature, both introduced with SQL Server 2005, were presented to show how the Query Optimizer itself can be used to provide index tuning recommendations.
Finally, the sys.dm_db_index_usage_stats DMV was introduced, together with its ability to provide valuable information regarding non-clustered indexes. While we didn’t have time to discuss all the practicalities of using this DMV, we covered enough for you to be able to easily find non-clustered indexes that are not being used by your SQL Server instance. A lot of the advice we covered in this chapter came in the form of demonstrations, so you should now be familiar with index creation, and understand how maximize the usefulness of indexes, and identify indexes that are not as useful.
Load comments