




SQL Server stores JSON data in VARCHAR or NVARCHAR columns (or, starting in 2024 with Azure SQL Database, in a native JSON data type). To work with JSON effectively: validate documents with ISJSON() before storage, read values with JSON_VALUE() and JSON_QUERY(), convert JSON arrays to table rows with OPENJSON(), and write relational data back to JSON with FOR JSON.
For better query performance, create computed columns on frequently accessed JSON properties and index them. For storage efficiency, compress large JSON documents using COMPRESS()/DECOMPRESS(). This guide covers the complete JSON storage lifecycle in SQL Server – from validation and storage architecture to indexing, compression, and the new native JSON data type.
Read also:
XML storage and parsing strategies for SQL Server
Storing and parsing JSON in SQL Server
Generating HTML from SQL Server using FOR XML PATH
Using the FOR XML clause for query output
CHAR and VARCHAR data type considerations
Introduction
Like XML, JSON is an open standard storage format for data, metadata, parameters, or other unstructured or semi-structured data. Because of its heavy usage in applications today, it inevitably will make its way into databases where it will need to be stored, compressed, modified, searched, and retrieved.
Even though a relational database is not the ideal place to store and manage less structured data, application requirements can oftentimes override an “optimal” database design. There is a convenience in having JSON data close to related relational data and architecting its storage effectively from the start can save significant time and resources in the future.
This article delves into how JSON is stored in SQL Server and the different ways in which it can be written, read, and maintained.
JSON and Strings are Not the Same!
Data stored as JSON will likely enter and exit a database in the JSON format. While stored in SQL Server, JSON should be queried in its native format.
For most data engineers and application developers, working with strings is fast, easy, and second nature. Functions such as SUBSTRING, LEFT, TRIM, and CHARINDEX are well-documented and standard across many platforms. For this reason, it is a common mistake when working with unstructured or semi-structured data to convert it to a VARCHAR/NVARCHAR format and using string-manipulation to work with it.
Because JSON is stored in SQL Server in VARCHAR/NVARCHAR formats, it is even easier to use this strategy than when working with XML, which is stored in XML-typed columns.
There are performance benefits and cost-savings when using the built-in JSON functionality. This article will focus on using SQL Server’s JSON functionality and omit demonstrations that work around it.
Lastly, be sure to only use JSON where it is needed by an application. Only store JSON data in SQL Server when required by an application and do not parse it unless component data from within it is required and cannot be obtained in an easier fashion.
Starting in 2024, in Azure SQL Database, JSON can be stored natively using the newly-provided JSON data type. This will be demonstrated later in this article. For now, in on-premises SQL Server, JSON is stored in VARCHAR/NVARCHAR columns. In both scenarios, JSON functions may be used to validate, read, and write the underlying data as JSON.
Note that native JSON support is likely to be added to SQL Server in the future, but as of the writing of this article, there is currently no timeline available for that feature. It is also very likely that the techniques provided here will still be useful, much like the XML functionality that operates on string data is.
A Quick Note on SQL Server Version
JSON support was introduced with SQL Server 2016. This equates to compatibility level 130. If any JSON functions are used in older versions of SQL Server, they will fail with an error that they are not found.
Note that JSON functions are available, even if a database is in a compatibility level less than 130, but SQL Server itself must be on at least SQL Server 2016 for this to work. For example, if any of the demonstrations in this article are run on compatibility level 100, but on SQL Server 2022, they would work. While I cannot think of any reason to do this, I suspect someone out there can!
Validating JSON Documents
The ideal use-case for JSON in the database is to be written and read in-place, without any complex I/O requirements to be managed along the way. Whether its use is this simple or not, reading JSON from the database can be accomplished relatively easily.
JSON can be stored and parsed from scalar values, such as parameters or locally declared variables, or it can be written and read to a column within a table. These first examples work with a simple variable that describes some (somewhat) hypothetical metadata about people:
|
1 2 3 4 5 6 7 8 9 10 |
DECLARE @PersonInfo VARCHAR(MAX) = '{ "PersonInfo": { "City": "Albany", "State": "New York", "SpiceLevel": "Extreme", "FavoriteSport": "Baseball", "Skills": ["SQL", "Baking", "Running", "Minecraft"] } }'; |
This JSON document describes a single person using a list of attributes. Note the syntax used in creating the document as it is important to create JSON that is well-formed with valid syntax. Forgetting a detail such as a quotation mark or comma can render the JSON impossible to validate or read using SQL Server’s built in functions.
For this reason, if there is any question at all as to the validity of JSON that is to be read, validate it first. This may be done using the ISJSON() function, like this:
|
1 2 |
--code works in conjunction with previous code. SELECT ISJSON(@PersonInfo) AS IsValidJSON; |
The result is either a zero if invalid, one if valid, and NULL if the value of the input, or in the case, @PersonInfo is NULL:
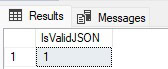
This is a great way to avoid unexpected errors. If zero is returned, then code can be executed to handle that scenario in whatever way makes the most sense. For example, if the T-SQL should throw an error, then this would be a simple way to do so:
|
1 2 3 4 5 6 7 8 9 10 11 |
--code works in conjunction with previous code. DECLARE @IsValidJSON BIT SELECT @IsValidJSON = ISJSON(@PersonInfo); IF @IsValidJSON = 0 BEGIN DECLARE @msg nvarchar(200) = 'The JSON entered is not' + ' valid. Please investigate and resolve' + ' this problem!'--broken up to format for screen RAISERROR(@msg, 16, 1); RETURN END |
If the JSON had not been well-formed, then the error would have been thrown immediately and RETURN would ensure that the calling process would end immediately. Alternatively, the error could be handled less viciously with a log entry, quiet skipping of invalid data, or some other method that doesn’t end processing immediately.
JSON can be written as a set of values, as well, like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
DECLARE @PersonInfo VARCHAR(MAX) = '{ "PersonInfo": { "FirstName": "Edward", "LastName": "Pollack", "City": "Albany", "State": "New York", "SpiceLevel": "Extreme", "FavoriteSport": "Baseball", "Skills": ["SQL", "Baking", "Running", "Minecraft"] }, { "FirstName": "Edgar", "LastName": "Codd", "City": "Fortuneswell", "State": "Dorset", "SpiceLevel": "Medium", "FavoriteSport": "Flying", "Skills": ["SQL", "Computers", "Flying", "Normalizing Data Models"] } }'; |
The following is a small table that includes a JSON-containing string column:
|
1 2 3 4 5 6 7 |
CREATE TABLE dbo.PersonInfo ( PersonId INT NOT NULL IDENTITY(1,1) CONSTRAINT PK_PersonInfo PRIMARY KEY CLUSTERED, FirstName VARCHAR(100) NOT NULL, LastName VARCHAR(100) NOT NULL, PersonMetadata VARCHAR(MAX) NOT NULL ); |
In addition to the two examples already provided of person data, a few additional rows will be inserted into the table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
INSERT INTO dbo.PersonInfo (FirstName, LastName, PersonMetadata) VALUES ('Thomas', 'Edison', '{ "PersonInfo": { "City": "Milan", "State": "Ohio", "SpiceLevel": "Mild", "FavoriteSport": "Reading", "Skills": ["Technology", "Business", "Communication"] } }') , ('Nikola', 'Tesla', '{ "PersonInfo": { "City": "Smiljan", "State": "Croatia", "SpiceLevel": "Hot", "FavoriteSport": "Inventing", "Skills": ["Lighting", "Electricity", "X-Rays", "Motors"] } }') , ('Edward', 'Pollack', '{ "PersonInfo": { "City": "Albany", "State": "New York", "SpiceLevel": "Extreme", "FavoriteSport": "Baseball", "Skills": ["SQL", "Baking", "Running", "Minecraft"] } }'), ('Edgar','Codd', '{ "PersonInfo": { "City": "Fortuneswell", "State": "Dorset", "SpiceLevel": "Medium", "FavoriteSport": "Flying", "Skills": ["SQL", "Computers", "Flying", "Normalizing Data Models"] } }') |
The validity of each JSON document can be verified similarly to the scalar example from earlier:
|
1 2 3 4 |
SELECT * FROM dbo.PersonInfo WHERE ISJSON(PersonInfo.PersonMetadata) = 1; |
Four rows are returned, confirming that each JSON document is valid:

Reading JSON Documents
Data can be read from JSON documents by either brute-force string searching or by using native JSON functions. Generally speaking, using native JSON functions will result in more reliable results and better performance. This is especially significant if using the native JSON data type in Azure SQL Database as it automatically offers performance improvements for native operations that are forfeited if string-searching is used instead.
Full-Text Indexing can be used on JSON columns that are typed as VARCHAR or NVARCHAR, though this is not advisable unless you already use Full-Text Indexing and/or all other search solutions have been exhausted.
It is important to repeat here: JSON documents are ideally stored as pass-through data for basic writes and reads. Since JSON columns cannot be natively indexed: searching, updating, and otherwise complex parsing will be potentially slow and challenging to code.
All demonstrations here use native functions and do not show string manipulation as a way to parse JSON data.
The JSON_VALUE function can be used to return a value from a JSON document. It can also be used for filtering, grouping, etc…The following example returns the values for City and State for each row in the table:
|
1 2 3 4 5 6 7 |
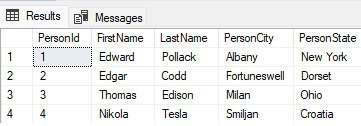
SELECT PersonId, FirstName, LastName, JSON_VALUE(PersonMetadata, '$.PersonInfo.City') AS PersonCity, JSON_VALUE(PersonMetadata, '$.PersonInfo.State') AS PersonState FROM dbo.PersonInfo; |
The results are what we expect, knowing the data in the table:
If the path requested in JSON_VALUE doesn’t exist, NULL will be returned. There will not be an error or indication of why NULL is returned, though. Similarly, JSON_VALUE, when evaluated against NULL will simply return NULL, with no further fanfare. The following code provides an example of this:
|
1 2 3 4 5 6 7 |
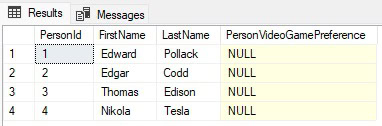
SELECT PersonId, FirstName, LastName, JSON_VALUE(PersonMetadata, '$.PersonInfo.VideoGamePreference') AS PersonVideoGamePreference FROM dbo.PersonInfo; |
The results show the expected NULL for the JSON_VALUE expression:
If the inputs to a JSON expression like this may not be valid, ensure that they are tested (if needed) to catch bad data, since there will not be an error or other indication of a problem (other than all NULL values returned).
An expression like JSON_VALUE can be placed in the WHERE clause for a query. Keep in mind that this will result in an index/table scan on a relatively large wide column value to be fully evaluated. Therefore, be sure to include additional filters if the table is particularly large, or if queries get slow.
The following example shows a query that returns all rows for people with a City defined as Albany:
|
1 2 3 4 5 |
SELECT * FROM dbo.PersonInfo WHERE ISJSON(PersonMetadata) = 1 AND JSON_VALUE(PersonMetadata, '$.PersonInfo.City') = 'Albany'; |
The results show a single row returned that matches the filter:

If there is a need to test whether a path exists within a JSON document, the function JSON_PATH_EXISTS may be used. It will return a 1 if the path exists, 0 if it does not, or NULL if the input it NULL. Like JSON_VALUE, this function does not return errors, regardless of whether the path exists or not. The following query can provide a test as to whether a person has a path exists for VideoGamePreference:
|
1 2 3 4 5 6 7 |
SELECT PersonId, FirstName, LastName, JSON_PATH_EXISTS(PersonMetadata,'$.PersonInfo.VideoGamePreference') AS PersonVideoGamePreference FROM dbo.PersonInfo; |
The results show that the path doesn’t exist for any of our examples:
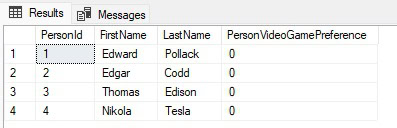
Remove the .VideoGamePreference from the string and you will see that $.PersonInfo does exist. This can be a good way to understand how the paths work in JSON documents.
This can also be used in the WHERE clause to ensure that only rows are returned that include a given path, or that values are only returned when a specified path exists.
Updating JSON Documents
While JSON documents can be updated en masse, that can be an expensive process if the documents are large, or if there are downstream calculations made based on documents. Being able to tactically make changes when and where needed can reduce IO and be a faster and more efficient way to update, add, or remove paths. Similarly, they may also be a need to modify documents after being read.
The simplest way to make changes to a JSON document is using the JSON_MODIFY function. This allows properties to be added, removed, or updated with relative ease. For example, the following query updates the City and State columns for any matching a specific City/State filter:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT PersonId, FirstName, LastName, JSON_MODIFY(JSON_MODIFY(PersonMetadata, '$.PersonInfo.City', 'London'), '$.PersonInfo.State', 'London') AS UpdatedDocument FROM dbo.PersonInfo WHERE JSON_VALUE(PersonMetadata, '$.PersonInfo.City') = 'Fortuneswell' AND JSON_VALUE(PersonMetadata, '$.PersonInfo.State') = 'Dorset'; |
The result is an updated document with London replacing Fortuneswell:

Note that this was not an UDPATE statement and that JSON_MODIFY does not write to the underlying table. It modifies the string value to include the new data you are asking it to. To permanently make this change to the table, the SELECT needs to be adjusted to an UPDATE, like this:
|
1 2 3 4 5 6 7 8 |
UPDATE PersonInfo SET PersonMetadata = JSON_MODIFY(JSON_MODIFY(PersonMetadata, '$.PersonInfo.City', 'London'), '$.PersonInfo.State', 'London') FROM dbo.PersonInfo WHERE JSON_VALUE(PersonMetadata, '$.PersonInfo.City') = 'Fortuneswell' AND JSON_VALUE(PersonMetadata, '$.PersonInfo.State') = 'Dorset'; |
This query can be used to validate the result:
|
1 2 3 4 |
SELECT * FROM dbo.PersonInfo WHERE JSON_VALUE(PersonMetadata, '$.PersonInfo.City') = 'London'; |
The result shows that the change has now been made permanent:

Updating JSON List Elements
A list may be updated with new elements by using the append option for JSON_MODIFY. This example adds the skill “Mustaches” to the list for a specific person:
|
1 2 3 4 5 6 7 8 9 |
SELECT PersonId, FirstName, LastName, JSON_MODIFY(PersonMetadata, 'append $.PersonInfo.Skills', 'Mustaches') FROM dbo.PersonInfo WHERE FirstName = 'Nikola' AND LastName = 'Tesla'; |
The results confirm that the list has been returned with the added element:

Like before, the underlying document has not been updated, but could be if the SELECT is adjusted into an UPDATE, like this:
|
1 2 3 4 5 6 7 |
UPDATE PersonInfo SET PersonMetadata = JSON_MODIFY(PersonMetadata, 'append $.PersonInfo.Skills', 'Mustaches') FROM dbo.PersonInfo WHERE FirstName = 'Nikola' AND LastName = 'Tesla'; |
Querying JSON List Elements
We can query to confirm the existence of the new skill in the list by using OPENJSON:
|
1 2 3 4 5 |
SELECT * FROM dbo.PersonInfo CROSS APPLY OPENJSON(PersonMetadata, '$.PersonInfo.Skills') WHERE [value] = 'Mustaches'; |
This query creates a full list of people with one row per person and skill. Removing the WHERE clause shows the full output of the CROSS APPLY, which in effect normalizes the data in the skills column to another table, just like if you were joining to a PersonInfoSkills table:
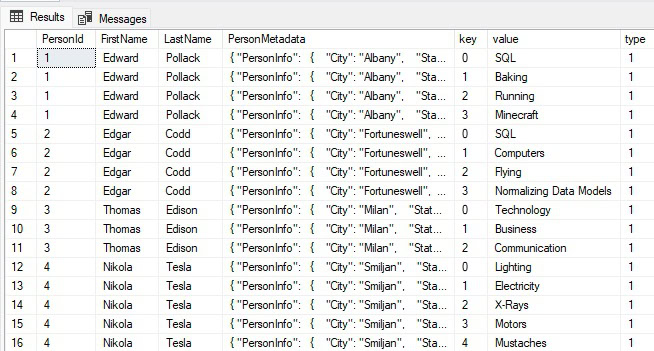
The filter checks the [value] column returned by OPENJSON and returns only the rows that are filtered for.
The following syntax can also be used to search for one or many list elements:
|
1 2 3 4 5 6 |
SELECT * FROM dbo.PersonInfo WHERE 'Mustaches' IN (SELECT [value] FROM OPENJSON(PersonMetadata, '$.PersonInfo.Skills')); |
Whether mustaches are a skill is up for grabs, but there are at least easy ways to search for them within a JSON list!
Read also: Consuming and querying JSON strings in SQL Server
Removing a JSON Property
A property may be deleted by setting it to NULL. The following example shows the State attribute being removed from the document:
|
1 2 3 4 5 6 |
SELECT PersonId, FirstName, LastName, JSON_MODIFY(PersonMetadata, '$.PersonInfo.State', NULL) FROM dbo.PersonInfo; |
The results show that State no longer exists for any rows in the table:

A property can be renamed, if needed. This can be helpful when system or product names change, or simply to correct a mistake within a document. This cannot be accomplished in a single step, though, and is done via a deletion and an insertion, like this:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT PersonId, FirstName, LastName, JSON_MODIFY(JSON_MODIFY(PersonMetadata, '$.PersonInfo.State', NULL), '$.PersonInfo.Region', JSON_VALUE(PersonMetadata, '$.PersonInfo.State')) FROM dbo.PersonInfo; |
Note that to maintain the existing value, JSON_VALUE is used to set the value for the new attribute equal to its previous value. The result shows that “State” has been renamed to “Region”:

The new Region attribute is appended to the end of the document and retains its original value prior to the rename.
The final example shows how updating JSON can become complex and difficult to read in T-SQL. If the application that manages this data can perform updates as it would update a value to any other column, the result would be simpler code and likely code that is more efficient. Since JSON is not relational data, even simple operations such as an attribute rename can become convoluted.
The longer and more complex a query is, the more likely it is for a mistake to be made when writing or modifying it. Consider this when deciding how documents will be updated, and what application will be used to do so.
Indexing JSON Documents
While no native indexing exists (yet) for JSON columns, hope is not lost! If a JSON document is often searched based on a specific attribute, then a computed column may be added that evaluates that attribute. Once a computed column exists, it may be indexed, just like any other computed column.
Consider the example earlier of a JSON document that contains a variety of attributes. Let’s say that a very common search occurs against the City attribute. To begin to solve this problem, a computed column will be created on the PersonInfo table that isolates City
|
1 2 |
ALTER TABLE dbo.PersonInfo ADD City AS JSON_VALUE(PersonMetadata, '$.PersonInfo.City'); |
The resulting column shows that it is set equal to the value of the City attribute.
|
1 2 |
SELECT * FROM dbo.PersonInfo; |
Now there is a new City column added.
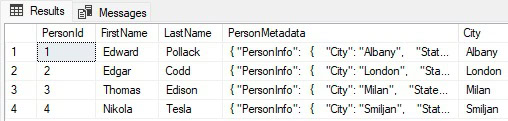
While the new column is convenient, it provides no performance help as it is just an embedded query against the JSON document. Indexing it provides the ability to search it:
|
1 2 |
CREATE NONCLUSTERED INDEX IX_PersonInfo_CityJSON ON dbo.PersonInfo (City ASC); |
This executes successfully, but does return a warning message:
Warning! The maximum key length for a nonclustered indexis 1700 bytes. The index 'IX_PersonInfo_CityJSON' hasmaximum length of 8000 bytes. For some combination of large values, the insert/update operation will fail.
Viewing the column’s definition shows that it indeed inherited a biggie-sized column length:
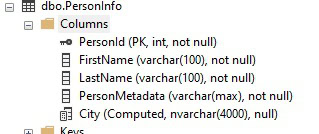
That column size is unnecessarily massive and can both impact performance, as well as confuse developers who are guaranteed to scratch their heads at a City that can be 4000 multi-byte characters long. To address this, we will remove the index and column and recreate it with a minor adjustment:
|
1 2 3 4 5 6 |
DROP INDEX IX_PersonInfo_CityJSON ON dbo.PersonInfo; ALTER TABLE dbo.PersonInfo DROP COLUMN City; ALTER TABLE dbo.PersonInfo ADD City AS CAST(JSON_VALUE(PersonMetadata, '$.PersonInfo.City') AS VARCHAR(100)); |
The new column includes a CAST that forces the column length to be VARCHAR(100). Assuming that City does not require double-byte characters and will always be under 100 characters, then this is a beneficial change. The new column size can be quickly validated, like before:
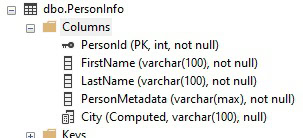
With that problem out of the way, an index can be placed on the column, this time without a warning message:
|
1 2 |
CREATE NONCLUSTERED INDEX IX_PersonInfo_CityJSON ON dbo.PersonInfo (City ASC); |
The final test of this indexed computed column is to select a row using a simple JSON search and then the indexed City column:
|
1 2 3 4 5 6 7 8 |
SELECT COUNT(*) FROM dbo.PersonInfo WHERE JSON_VALUE(PersonMetadata, '$.PersonInfo.City') = 'Albany'; SELECT COUNT(*) FROM dbo.PersonInfo WHERE City = 'Albany'; |
Note the difference in execution plans:
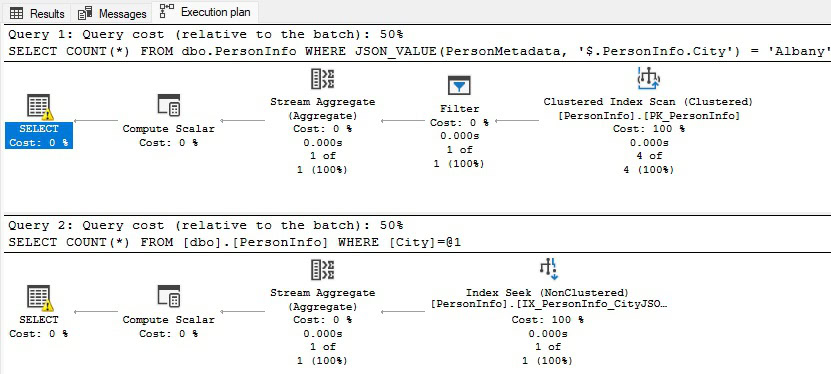
The search against the unindexed JSON column requires a table scan as the function must be evaluated against every JSON doc in the table prior to returning results. Alternatively, the search against the City column can use the newly created index and a seek to get its result.
An alternative to this strategy would be for the application that uses this table to persist the City column itself. Instead of a computed column, the City could be maintained completely by the application, ensuring the correct value is updated whenever the JSON document is created, updated, or deleted. This would be less convoluted but would require that the application be solely responsible for always maintaining the column. Depending on the app, this may or may not be a simple request.
Consider the cost of maintaining a persisted computed column when implementing a performance change like this. The cost for improving search performance for a column is that write operations against the JSON document will be slightly slower as each update will need to re-evaluate the definition for the computed column and update the index. Adding many columns like this can quickly become expensive and cause write operations to both perform slower and be more likely to introduce contention. Carefully weigh the importance and frequency of a search query against the IO needed to maintain a persisted column with its value.
Compressing JSON
There is no unique way to compress a JSON column, regardless of whether it is stored in VARCHAR/NVARCHAR format, or in native JSON format.
The option available for compressing JSON documents is to use the COMPRESS and DECOMPRESS functions, which use the Gzip compression algorithm to decrease the size of text columns that are stored as off-row data. These functions are not unique to JSON and are also used to compress large text or binary data that row/page compression will not handle by default.
It is important to note that compression has ramifications that go beyond simply reducing the table’s size and therefore the size of the data file for its database. Compressed data remains compressed in memory and is only decompressed at runtime, when needed by SQL Server. If you are running SQL Server in Web Edition, or if backup compression is unavailable, then compressing data translates to compressing data within backups. This results in smaller backup files. Therefore, data compression can save storage space in multiple locations, as well as memory.
Schema changes are required to use COMPRESS and DECOMPRESS as the output of compression is a VARBINARY data type, and not a VARCHAR/NVARCHAR data type. This can be observed by selecting JSON data and compressing it prior to displaying it:
|
1 2 3 4 5 6 |
SELECT PersonId, FirstName, LastName, COMPRESS(PersonMetadata) AS PersonMetadataCompressed FROM dbo.PersonInfo |
The result of this query is a VARBINARY string that is visually meaningless:

To use compression via this method, there are some basic steps to follow:
- Ensure the table has a
VARBINARY(MAX)column available to store the compressed data. - When writing data to the table, use
COMPRESSon the string data prior to inserting it into theVARBINARYcolumn. - When reading data from the table, use
DECOMPRESSon the binary data. - When the data is ready to be used, cast the
VARBINARYoutput ofDECOMPRESSas theVARCHAR/NVARCHARthat the column is intended to be.
To begin the walkthrough of this process, a new table will be created that uses a VARBINARY(MAX) column, instead of a VARCHAR(MAX).
|
1 2 3 4 5 6 7 8 |
CREATE TABLE dbo.PersonInfoCompressed ( PersonId INT NOT NULL IDENTITY(1,1) CONSTRAINT PK_PersonInfoCompressed PRIMARY KEY CLUSTERED, FirstName VARCHAR(100) NOT NULL, LastName VARCHAR(100) NOT NULL, PersonMetadata VARBINARY(MAX) NOT NULL ); |
The PersonMetadata column is now a VARBINARY(MAX) column now, rather than VARCHAR(MAX).
With this table created, it can be populated similarly to before:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
INSERT INTO dbo.PersonInfoCompressed (FirstName, LastName, PersonMetadata) VALUES ('Edward', 'Pollack', COMPRESS('{ "PersonInfo": { "City": "Albany", "State": "New York", "SpiceLevel": "Extreme", "FavoriteSport": "Baseball", "Skills": ["SQL", "Baking", "Running", "Minecraft"] } }')), ('Edgar', 'Codd', COMPRESS('{ "PersonInfo": { "City": "Fortuneswell", "State": "Dorset", "SpiceLevel": "Medium", "FavoriteSport": "Flying", "Skills": ["SQL", "Computers", "Flying", "Normalizing Data Models"] } }')); INSERT INTO dbo.PersonInfoCompressed (FirstName, LastName, PersonMetadata) VALUES ('Thomas', 'Edison', COMPRESS('{ "PersonInfo": { "City": "Milan", "State": "Ohio", "SpiceLevel": "Mild", "FavoriteSport": "Reading", "Skills": ["Technology", "Business", "Communication"] } }')), ('Nikola', 'Tesla', COMPRESS('{ "PersonInfo": { "City": "Smiljan", "State": "Croatia", "SpiceLevel": "Hot", "FavoriteSport": "Inventing", "Skills": ["Lighting", "Electricity", "X-Rays", "Motors"] } }')); |
The big difference is that each JSON document is wrapped in a call to the COMPRESS function. This is now a necessary step, and attempting to insert the VARCHAR JSON data directly into the VARBINARY column will result in a conversion error. Selecting data from the table will show the same results as the compression test in the previous demonstration.
To read data from this column, it needs to have the DECOMPRESS function applied, like this:
|
1 2 3 4 5 6 7 |
SELECT PersonId, FirstName, LastName, DECOMPRESS(PersonMetadata) AS PersonMetadata FROM dbo.PersonInfoCompressed WHERE LastName = 'Tesla'; |
The results show the decompressed VARBINARY output:

To convert this into meaningful data, it needs to be converted to its intended VARCHAR format:
|
1 2 3 4 5 |
SELECT CAST(DECOMPRESS(PersonMetadata) AS VARCHAR(MAX)) AS PersonMetadata FROM dbo.PersonInfoCompressed WHERE LastName = 'Tesla'; |
This time, the output is the JSON document, as it was originally inserted:

There is value in keeping the JSON document compressed for as long as possible, prior to decompressing and converting to a string that can be read or parsed. The longer it is compressed, the longer computing resources are saved in moving it around.
Because the compressed JSON document is stored in VARBINARY format, there is no simple way to search the column that will not involve a table scan. This is because all rows need to be decompressed and converted to a string first, prior to searching. If there is a frequent need to search the compressed JSON column, consider persisting the search column as a separate indexed column.
Note that COMPRESS and DECOMPRESS are deterministic and will always yield the same results. There is no random element to the algorithm, nor does the compression algorithm/results change for different versions or editions of SQL Server.
Read also: Temporary tables for staging parsed JSON results
The JSON Data Type in Azure SQL Database
Azure SQL Database added native JSON support in May 2024, allowing columns and variables to be declared as JSON, rather than VARCHAR or NVARCHAR. This support is available regardless of database compatibility level. Native support provides significantly improved performance as the document is stored in an already-parsed format. This reduces its storage size, IO needed to read and write JSON data, and allows for efficient compression.
As a bonus, no code changes are required to take advantage of the native JSON data type. A column’s data type may be altered from VARCHAR/NVARCHAR to JSON and existing functions will continue to work. As always, it is important to test schema changes before deploying to a production environment, but the ability to improve JSON performance without code changes is hugely beneficial to any organization managing JSON documents in SQL Server.
These demos are executed against a small test database in Azure SQL Database that contains the default test objects from Microsoft.
Consider the simple example from earlier in this article, rewritten slightly to use the native JSON data type:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
-- In Azure SQL Database DECLARE @PersonInfo JSON = '[ { "FirstName": "Edward", "LastName": "Pollack", "City": "Albany", "State": "New York", "SpiceLevel": "Extreme", "FavoriteSport": "Baseball", "Skills": ["SQL", "Baking", "Running", "Minecraft"] }, { "FirstName": "Edgar", "LastName": "Codd", "City": "Fortuneswell", "State": "Dorset", "SpiceLevel": "Medium", "FavoriteSport": "Flying", "Skills": ["SQL", "Computers", "Flying", "Normalizing Data Models"] } ]'; SELECT ISJSON(@PersonInfo); |
This code executes exactly the same way as it did earlier, returning a “1”, indicating that this is valid JSON. All the other code in the chapter will work the same way as well, just in a more efficient manner internally.
For columns that use the native JSON data type, constraints may be placed against them, just like any other column data type. While ISJSON() may be used in the column’s definition, allowing JSON to only be stored if it is valid and well-formed, this check is already performed as part of the JSON data type. An attempt to insert JSON that is not properly formed will result in an error.
The following is a simple table that contains a JSON column:
|
1 2 3 4 5 6 7 8 |
CREATE TABLE dbo.JSONTest ( ID INT NOT NULL IDENTITY(1,1) CONSTRAINT PK_JSONTest PRIMARY KEY CLUSTERED, DocName VARCHAR(50) NOT NULL, JSONDocument JSON NOT NULL CONSTRAINT CK_JSONTest_Check_FirstName CHECK (JSON_PATH_EXISTS(JSONDocument, '$.FirstName') = 1)); |
Note the CHECK constraint on the JSONDocument column. This constraint will check the document to ensure that FirstName is present, and if not, the document will not be allowed. For example, the following T-SQL will result in an error:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
INSERT INTO dbo.JSONTest (DocName, JSONDocument) VALUES ( 'A name entry', '{ "LastName": "Pollack", "City": "Albany", "State": "New York", "SpiceLevel": "Extreme", "FavoriteSport": "Baseball", "Skills": ["SQL", "Baking", "Running", "Minecraft"] }'); |
The error is the standard check constraint failure error:
Msg 547, Level 16, State 0, Line 158
The INSERT statement conflicted with the CHECK constraint "CK_JSONTest_Check_FirstName". The conflict occurred in database "EdTest", table "dbo.JSONTest", column 'JSONDocument'.
The statement has been terminated.
The ability to embed JSON functions into check constraints can help to add firm data validation to documents before they enter the database. This can be exceptionally valuable in scenarios where an application is unable to ensure different criteria up-front.
There are no native indexes supported (yet) for JSON data types, though a JSON column may be part of the INCLUDE columns in an index definition. The JSON data type is compatible as a stored procedure parameter, in triggers, views, and as a return type in functions.
If using Azure SQL Database and JSON, then the native data type is an easy way to improve performance and data integrity.
Read also:
Azure SQL’s native JSON data type
CHAR vs VARCHAR data type considerations
Conclusion
JSON documents can be stored in SQL Server and accessed similarly to data stored in any other typed column using specialized JSON functions. This provides applications the ability to store JSON in SQL Server alongside relational data when needed.
While there are many considerations for how to store, index, compress, and manage JSON data that differ from traditional data types, the ability to maintain this data in SQL Server allows applications to manage it conveniently, rather than needing another storage location for it.
The JSON data type is a game-changer for these applications as it allows JSON documents to be stored natively in SQL Server, where they can be stored and read far more efficiently than as a string (or compressed string) column. While this feature is only available in Azure SQL Database as of June 2024, it is very likely to be available in future versions of SQL Server. Similarly, native JSON indexing is also a likely future feature addition. If this is an important feature to your development team, then keep an eye out for its availability in the near future.
Lastly, consider how and why JSON is stored in a relational database. Part of planning good data architecture is understanding the WHY and HOW behind data decisions, as well as what the future of that data will be. The ideal scenario for JSON is to be stored, maybe compressed, but filtered and manipulated as little as possible. While this may not always be possible, it is important to remember that a relational database engine is not optimized for document storage. Even with a native JSON data type, compression, and other (really cool) trickery, it is still a bit of an edge-case that should be managed carefully.
Thanks for reading, and hopefully this information helps you manage JSON documents more efficiently in the world of SQL Server!
Fast, reliable and consistent SQL Server development…
FAQs: How to store and parse JSON in SQL Server
1. How do you store JSON in SQL Server?
In on-premises SQL Server (2016+), store JSON in NVARCHAR(MAX) or VARCHAR(MAX) columns – there is no native JSON data type. Use ISJSON() as a CHECK constraint to validate that only well-formed JSON documents are inserted. In Azure SQL Database (2024+), you can use the native JSON data type, which provides built-in validation and more efficient storage. For large documents, consider COMPRESS() to reduce storage footprint, and create computed columns with indexes on frequently queried JSON properties.
2. What is the difference between JSON_VALUE and JSON_QUERY in SQL Server?
JSON_VALUE extracts a scalar value (string, number, boolean) from a JSON document and returns it as NVARCHAR(4000). JSON_QUERY extracts a JSON object or array and returns it as NVARCHAR(MAX), preserving the JSON structure. Use JSON_VALUE for leaf-level properties like names or prices; use JSON_QUERY for nested objects or arrays that need to remain as JSON.
3. How do you index JSON data in SQL Server?
Create a computed column that extracts the JSON property with JSON_VALUE(), then add a standard index on that computed column. For example: ALTER TABLE Orders ADD CustomerName AS JSON_VALUE(OrderData, ‘$.customer.name’); CREATE INDEX IX_CustomerName ON Orders(CustomerName). The computed column can be persisted for better performance. This approach works for both NVARCHAR-stored JSON and the native JSON data type.
4. Should you store JSON in SQL Server or a document database?
Store JSON in SQL Server when the JSON data is closely related to relational data in the same database, when the application needs ACID transactions across JSON and relational data, or when JSON is primarily stored and retrieved without complex querying. Use a document database (MongoDB, Cosmos DB) when JSON is the primary data model, when you need flexible schemas across large datasets, or when you need specialized JSON indexing and query capabilities beyond what SQL Server provides.



Load comments