
String manipulation is an inevitable task for developers and data professionals alike. Despite all the best efforts to normalize databases, eventually we are faced with some sort of text-based data stored within a relational database and need to extract detailed information from it.
Those of us who have tackled these challenges fully understand how code can quickly go from simple to absurdly complex, one function at a time. When the time comes to troubleshoot someone else’s endless block of spaghetti-code to determine what exactly it is trying to do, we realize that simple is always better.
This article is focused on how to write, simplify, and get the most out of string data using the least amount of code to do so. It’s a reminder that code complexity is equivalent to technical debt and that in these scenarios, less is always more.
Text-manipulating functions will be introduced and reviewed throughout this article, so feel free to perform searches against it to find what you are looking for.
Delimited Lists
While storing a list of values in a string is inherently messy, it is a frequently-chosen solution as it is easy to manage within an application, even if parsing it in the database can be a hassle. Managing string-based lists has become much, much easier across database platforms as standardized functions for slicing and concatenating strings have been widely available for a while now.
If your code uses XML, WHILE loops, cursors, JSON, or other eye-squinting solutions to create/parse a simple delimited list, please consider one of the following functions to greatly improve the performance and maintainability of your code.
Note that all functions in this article can be applied to column values in a table from within a query, in addition to scalar values. The syntax is the same, regardless of usage.
STRING_SPLIT()
Introduced in SQL Server 2016, this function accepts a delimited list and a delimiter, returning a data set with a value per row. SQL Server 2022 enhanced this function with the optional ordinal parameter, which when used will add an integer key to each row.
Consider the following simple comma-separated list:
|
1 |
DECLARE @CsvString VARCHAR(MAX) = '17, 23, 289, 1024, 9999'; |
Using STRING_SPLIT, the following code will convert the string into a list of values:
|
1 2 3 |
SELECT [value] AS SplitValue FROM STRING_SPLIT(@CsvString, ','); |
The results are as follows:
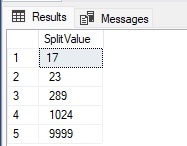
Note that the column returned by the function is named [value]. I find it is helpful to rename it to whatever the data represents, or at least something that is not a system identifier. The ordinal parameter is an optional 3rd value that may be passed into the function and adds a potentially useful column to the output. This code demonstrates its use:
|
1 2 3 4 5 6 |
DECLARE @CsvString VARCHAR(MAX) = '17, 23, 289, 1024, 9999'; SELECT ordinal, [value] AS SplitValue FROM STRING_SPLIT(@CsvString, ',', 1); |
Note the additional value of “1” that is passed in after the delimiter. There are only two valid uses of this parameter. Either “1” is specified or the parameter is omitted. “0” is not a valid entry here. The results will look like this:
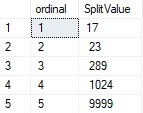
Ordinal is an auto-incrementing BIGINT value that allows the output of the function to be both ordered and numbered. This can be helpful when sorting, joining, or inserting this data into a table. Not that the SplitValue column is not sorted by the list order, not the values that are in the list. Without the ordinal value, there is no safe way to know the order of the input, as the order in the output table may change depending on how the query is processed.
There are many other solutions out there for splitting strings, but this is by and far the ideal one. Regardless of the complexity of a string or the delimiter, please consider using this function as it will result in smaller/simpler code that consistently performs better than the alternatives.
STRING_AGG()
The flip-side of needing to parse a delimited list is the need to generate a delimited list from a list of values. Introduced in SQL Server 2017, the aggregate function STRING_AGG operates on a set of values and returns a string.
This is exceptionally convenient and can be augmented with the WITHIN GROUP…ORDER BY clause, that allows the results to be sorted prior to string-generation.
The separator provided is not appended to the end of the string, which removes the hassle introduced by many of the older/more complex solutions to this problem.
Consider the table of values created below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE TABLE #ListOfFoods ( FoodId INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED, FoodName VARCHAR(100) NOT NULL); INSERT INTO #ListOfFoods (FoodName) VALUES ('Taco'), ('Pizza'), ('Chicken Alfredo'), ('Super-Spicy Spinach Curry'), ('Hamburger'), ('Brownie a la Mode'); |
If we wanted to convert this into a comma-separated list for use within a report, STRING_AGG could do so like this:
|
1 2 3 |
SELECT STRING_AGG(FoodName, ',') AS FoodNameList FROM #ListOfFoods; |
This basic implementation shows how every value in the list is aggregated and returned in a list. The results are as follows:

While the values above are in the order they were inserted into the temporary table, SQL Server does NOT guarantee order in the result set, and query/execution plan details can result in the order being different than expected at runtime. Therefore, the ability to order the results can be added, using this modified code:
|
1 2 3 4 |
SELECT STRING_AGG(FoodName, ',') WITHIN GROUP (ORDER BY FoodName ASC) AS FoodNameList FROM #ListOfFoods; |
The results contain the same values, but ordered by the food name, rather than the arbitrary order that the data was inserted:

Like all other aggregate functions, a GROUP BY may be added to the query. When this is done, the results of STRING_AGG will contain only the values relevant to each grouped value much like any aggregate function would do. Similarly, the WITHIN GROUP…ORDER BY clause will only apply to each list within each row in the result set.
As with STRING_SPLIT, this function is indispensable. It is fast, flexible, and performs very well. When a list needs to be built from a delimited string, use STRING_AGG whenever possible.
Extracting Text from a String
One of the messiest text operations faced by developers is the need to search a string and return a specific portion when the location is determined by the presence of a character, character pattern, or another string. This section will use a variety of functions and build on itself to solve increasingly complex challenges.
CHARINDEX()
This function returns the starting position of the first location of a character/string within another string. A start location may be optionally provided that determines where in the string to begin the search. If either input is NULL, the result will be NULL. If the search expression is not found, then “0” is returned.
The code below provides a simple use of CHARINDEX to return the start location for a key component within a string:
|
1 2 3 4 |
DECLARE @StringToSearch VARCHAR(MAX) = 'The answer to the problem is as follows: 42!'; SELECT CHARINDEX(': ', @StringToSearch); |
Note that the expression to search for is provided first and the string to search is provided second. It is easy to reverse these by accident, but fortunately easy to diagnose and resolve. The numeric result will look like this:
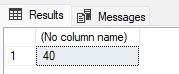
Note that the first character in the string is numbered “1” and not “0”. The result of “40” is the position in the string where the first character in the string-to-locate is found. In this case, character 40 corresponds to the colon in @StringToSearch. This will be the case, regardless of if the string to locate is one character or many.
The next logical step here would be to extract the text following the colon and return it for use by an application. This can be done using RIGHT or SUBSTRING. For demonstration purposes, both will be shown here, along with the benefits/drawbacks of each:
RIGHT()
This function returns the rightmost N characters from a string. This example returns the right-most 3 characters from the string introduced above:
|
1 |
SELECT RIGHT(@StringToSearch, 3); |
The result is a string that looks like this:
![]()
While this code returned the desired result, the value of “3” was hard coded into the query. A common need is to find the location of an expression within a string and then return all of the text afterwards, or some other amount that is dynamic.
In this scenario, the number 3 needs to be calculated on-the-fly. To do this, we need to determine the difference between the length of the string and the location of the colon. To calculate the length of a string requires the use of a new string function, LEN(), which will be covered in the next section.
LEN()
This function returns an integer that represents the length of a string, excluding trailing whitespaces. The function is easy to use:
|
1 |
SELECT LEN(@StringToSearch); |
This query returns the length of the string, in characters:
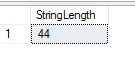
If you would like the results to be returned in bytes, rather than characters, use the DATALENGTH() function instead. That function will return 1 byte for VARCHAR data type characters and 2 bytes for NVARCHAR data type characters. The syntax is the same, with only the results being impacted.
Using these functions, we can return the text to the right of the colon using this query:
|
1 2 3 |
SELECT RIGHT(@StringToSearch, LEN(@StringToSearch) - CHARINDEX(': ', @StringToSearch)); |
The result looks like this:
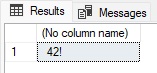
When viewing this syntax, it becomes obvious that our T-SQL can quickly get messy if we need to continue nesting various functions within each other. This same result can be achieved using SUBSTRING() instead, which may (or may not be) be preferable to using RIGHT():
SUBSTRING()
Given a string, start position, and length, SUBSTRING() will return a substring of the string given those parameters. For example:
|
1 |
SELECT SUBSTRING(@StringToSearch, 42, 3) AS TheAnswer; |
This query returns a substring of @StringToSearch that is 3 characters long starting at character 42. The result (“42!”) is the answer we have previously calculated above.
Real-life scenarios would not benefit from hard-coded values, and therefore this query needs to be expanded to include a dynamically calculated start position and length:
|
1 2 3 4 |
SELECT SUBSTRING(@StringToSearch, CHARINDEX(': ', @StringToSearch) + 2, LEN(@StringToSearch) – CHARINDEX(': ', @StringToSearch)); |
This query returns the same results but is unfortunately more complex. In this example, RIGHT and LEN require less code and would generally be preferable. Depending on your string-parsing needs, different functions and combinations of them will result in code of varying complexity. Code with less function calls and less complexity will be typically be easier to maintain and typically perform better than more complicated code.
Finding Patterns in a String
Sometimes string-searching does not target a specific string, but instead may be looking for a pattern. In scenarios like this, the search may be a fuzzy one that involves wildcards and (maybe) some regex. So far, all functions provided have been very specific. Enter exact numbers and values and receive a single value in return. In contrast, this function is a bit different:
PATINDEX()
Given a string, this function will locate the first occurrence of a string pattern within it. The pattern may use wildcards, regex, and/or constructed variables to arrive at a result. To demonstrate its usage, consider the following T-SQL:
|
1 2 3 4 |
DECLARE @NotesText VARCHAR(MAX) = 'Drive straight for 400 feet and then turn right.'; SELECT PATINDEX('%[0-9]%', @NotesText) AS DistanceLocation; |
The goal of this query is to return the number 400 from the string provided above. The number may not be 400, though. It could be any integer value whose value is not known ahead of time. Therefore, we can use PATINDEX and some basic regex to locate the starting position of the first number in the string. The result is as follows:
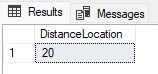
Position 20 is the location of the number 4 in the string. If there was a need to only locate the first number that is at least three digits long, the following query illustrates how to accomplish that:
|
1 2 3 4 5 |
DECLARE @NotesText VARCHAR(MAX) = 'Step 1: Drive straight for 400 feet and then turn right.'; SELECT PATINDEX('%[0-9][0-9][0-9]%', @NotesText) AS DistanceLocation; |
This query simply repeats the [0-9] regex operator two times. The result ensures that the search pattern is checking for three consecutive numbers, rather than the first occurrence of a number, which would return the “1” in position #6.
Regex can quickly get complicated. Always consider ways to simplify code and avoid hellish regex that is challenging to read and decode. While complex regex will not make a query perform noticeably worse, it will be hard to maintain and more error prone.
For example, if the goal was to identify the location of the first non-alphanumeric character excluding spaces, it could ALMOST be accomplished like this:
|
1 2 |
SELECT PATINDEX('%[^0-9a-zA-Z]%', @NotesText) AS NonAlphaNumericLocation; |
This returns “5”, which is the location of the space after the word “Step”. We want to exclude that, and so the resulting T-SQL looks like this:
|
1 2 |
SELECT PATINDEX('%[^0-9a-zA-Z ]%', @NotesText) AS NonAlphaNumericLocation; |
The added space at the end of the regex string is bit awkward and easy to overlook. This will change the result from “5” to “7”, which is the location of the colon. The following alternative assumes a short list of known characters that are being looked for in the string:
|
1 2 |
SELECT PATINDEX('%[!@#$*:;"]%', @NotesText) AS NonAlphaNumericLocation; |
This query is no simpler than the previous one, but it has an explicit character list, rather than a NOT IN character list relationship. This will generally be easier to read and understand.
Note that documentation is important when building larger or complex string-manipulating queries. Consider the comments needed to explain what a query does and (if needed) why it was accomplished using the given method.
Searching from the End of a String
Sometimes there is a need to return a variable length segment from the end of a string, instead of the front of one. This is a little trickier, but not terribly difficult. Consider the following string:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
DECLARE @RecipeDirections VARCHAR(MAX) = 'Double Chocolate Chip Cookies Ingredients: 1 cup (2 sticks) cold, unsalted butter, cubed 1.25 cup sugar 2 large eggs 0.5 cup dark cocoa powder 2.25 cups all-purpose flour 0.25 tsp. coarse salt 1 tsp. baking powder 2.5 cups semi-sweet chocolate chips Directions: 1. Combine butter and sugar in a mixing bowl. 2. Mix in eggs, one at a time, until combined. Add cocoa powder and mix until incorporated. 3. Add flour, salt, baking powder, cinnamon, and cayenne powder and mix until well combined. 4. Mix in chocolate chips. 5. Roll into 20-24 dough balls and flatten into cookie shapes on two baking sheets. 6. Bake at 350° F for 17-18 minutes. Yield: 20-24 large cookies.'; |
This string contains a recipe – but it could be any recipe with any number of steps that use any words. Let’s say the yield is always at the end of the recipe and we wanted to extract it from all recipes in a set that are structured like this one. Consider too, the word yield may be in the string multiple times, for example it might say “Mix ingredients together, this will yield 2 loafs.”
There are many ways to solve this problem, though an ideal solution would make no unneeded assumptions and would not be excessively complicated.
Since the recipe may contain the word “yield”, simply searching for the first occurrence of the word could result in mistakes. Similarly, the recipe could contain periods, colons, or any other symbols/words included in the yield. The only guarantee we have is that the actual yield is the last part of the recipe.
REVERSE()
The function REVERSE() accepts a string and reverses its order, returning the backwards string as the result. It can be used to provide easier access to the end of a string for additional string manipulation. If the goal is to remove a substring of a known structure from the end of a string, then REVERSE can be a sneaky way to do so.
The following T-SQL will reverse the recipe directions and find the location of ‘ :dleiY’, which is the string ‘Yield: ‘ backwards:
|
1 |
SELECT CHARINDEX(':dleiY', REVERSE(@RecipeDirections)); |
That provides the character position where the yield text begins. From here, the number can be used to remove the rightmost N characters from the recipe string:
|
1 2 3 4 |
SELECT RIGHT(@RecipeDirections, CHARINDEX(' :dleiY', REVERSE(@RecipeDirections)) + LEN('Yield:')) AS Yield; |
Note that the length of the string ‘Yield:’ is added to the number of characters to capture, ensuring that the string ‘Yield:’ is included in the results, which look like this:
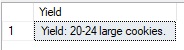
There are other ways to solve problems like this, but some care is needed to find the solution that is simplest and does not make the results susceptible to bad data if the string contains unexpected inputs.
XML, JSON, and Other Document Formats
While a discussion about parsing other file or document formats is out-of-scope for this article, it is important to note that if a string is presented in a specific format, the ideal solution will use functions that are built to work with that format.
For example, if a JSON string requires parsing, the ideal solution will include use of SQL Server’s JSON functions (or JSON functionality from another application or library). The results are guaranteed to be simpler, easier to understand, and more accurate. The following page lists and describes each function and how to use them: https://learn.microsoft.com/en-us/sql/t-sql/functions/json-functions-transact-sql?view=sql-server-ver16
Similarly, this page provides extensive information about how best to collect, index, and query XML data within SQL Server: https://learn.microsoft.com/en-us/sql/relational-databases/xml/xml-data-sql-server?view=sql-server-ver16
Lastly, if any sort of file data is required in SQL Server and cannot be stored in a file system elsewhere, consider the most lightweight option possible for storage. Opening and reading files within SQL Server is a slow and resource-intensive process that should generally be left to applications to manage. When architecting solutions around files, images, or documents, consider all options for lightening the impact on the database server as applications and file systems are far better suited to managing files than a relational database.
The goal of this reminder is to choose appropriate formats for data, store it in an efficient location, and use the most well-suited tools for accessing that data. String manipulation is not ideal for any of these formats and should be avoided if possible.
Conclusion
String manipulation is inherently a messy challenge where it is easy to develop larger and more complex T-SQL to the point where it becomes hard to read, understand, and maintain. Solving these challenges in the simplest way possible is key, and doing so often requires little more effort than learning a few new functions.
In the scenarios where data is stored in other formats, always try to architect solutions that leverage those formats, rather than raw string manipulation. The results will be simpler, more efficient, and easier to maintain.
What is presented in this article is only the beginning, though. There are many other string-related functions that can be leveraged to address common stringy problems. Any individual solution can be used as a building block for more adventurous solutions as well, combining different functions and queries into larger ones that solve more complex problems.
Regardless of details, consider simplicity an asset and try to write and document code in a way that ensures that when the next developer reads your code, they are able to easily understand and work with it.





Load comments