
Code reviews are a huge factor in improving code quality. You can find this supported in Karl Wiegers Humanizing Peer Reviews and in Steve McConnell’s Code Complete, to name just a couple well-known sources. But how you approach a code review can mean a vast difference in its effectiveness. This article shares some tips and techniques to help you make your code reviews as effective as possible: in short getting you better feedback with less net effort.
In my earlier 4-part series, The Zen of Code Reviews, I discussed general principles and practices of code reviews, but focused on Team Foundation Server (now known as Azure DevOps Server) because that is what my team was embroiled in. Fast forward a couple years later to today–new company, new team, new environment–now heavily weighted in Git and GitHub. So this time around, I want to share some new “tips from the trenches”, revisit some prior ideas, and generally expound upon things from the Git perspective, showing you simple ideas that can improve your code quality. Since this article is focused on Git, I will primarily use Git’s term—pull request or PR for short—to refer to code reviews.
Why do you want your code reviewed? So you can get feedback from your peers on inefficient, inaccurate, invalid, inexplicable, insufficient, or otherwise sub-optimal areas of your code and then make improvements. In order to do that, your job as the author of a code review is to present your case as clearly as possible. A reviewer’s job, on the other hand, is to be able to provide useful feedback, which means that the reviewer must understand the issue that your code addresses, then peruse your changes (whether really relevant to the issue at hand or not), and finally figure out what your changes mean in context, i.e. the ramifications of those changes. As the author, you have an unfair advantage. You already know the issue that your code addresses. You know which changes are significant and which are just noise. You know most (or sometimes all) the ramifications of your changes. So why not share that valuable insight with your code reviewers?
What do I mean? In its most basic form: explain yourself. Help your reviewers help you; enlighten them on anything that is less than obvious. In doing that, you also cover the other side of the coin that is just as important: justify yourself. You are making changes to your company’s crown jewels–the code that powers your website, drives your equipment, manages your processes… whatever it may be, you need to be able to show that you have clear and useful reasons for the changes you want to make.
In Zen, part 1, I described three types of comments that all play a part in helping you explain yourself: in-code comments, code-review description, and pre-review comments. With Git, I am renaming code-review description to PR preamble and I am adding a new, fourth item to that list that is a variant of pre-review comments, but deserves to be called out separately: commit comments. The four types are summarized in this table and then explained further. These are listed in the order they would typically be used.
|
Type |
Details |
When to Use |
|
In-code Comments |
Annotate your code to explain obscure, tricky, and otherwise non-obvious bits. |
Before creating your pull request, during development |
|
Commit Comments |
Break your development up into mini-milestones; commit each milestone and add a commit message describing the milestone. |
Before creating your pull request, during development |
|
Pull Request Preamble |
Detailed description of the purpose of your pull request with text and pictures including: what “done” means, how to exercise it, and more. |
When creating a pull request |
|
Pre-Review Comments |
Explain non-obvious changes from the prior version to the current version. |
Immediately after creating a pull request but before notifying reviewers |
In-code Comments
These are your usual, garden variety comments:
- Why does your loop start with x + 2 instead of x?
- If you wrote a function that is a variant of the Lempel–Ziv–Welch algorithm, say so.
- When you find a handy little function that is unfortunately not in a pluggable library, certainly go ahead and paste into your file but be sure to add a URL for where you found it.
Using in-code comments has its proponents and its detractors. In fact, it is often one of those sacred cows that gets some folks riled up, like “tabs vs. spaces”, “vim vs. emacs”, etc. I submit, however, that it gets folks riled up because they are looking at the wrong question. “Are comments good or bad?” is a meaningless question until you qualify that with what kind of comment you are talking about. Some types of comments are just evil. Some are not evil at all. Thus, it definitely depends which of the 9 types of comments you mean when you ask “Are comments good or bad?” See my article Fighting Evil in Your Code: Comments on Comments for details.
Commit Comments
This is the exciting new piece I am adding for Git users, because it is so natural to work in this fashion. In my experience, the most digestible types of pull requests are those that include multiple commits (for all but the most trivial pull request), where each commit represents a sub-task or milestone along the way towards the aggregate goal of your pull request. Think of this in terms of applying the Single Responsibility Principle to building your pull request. Instead of a single commit with a commit message that reads like this…
|
1 2 3 4 5 6 7 8 |
Implemented the boojum for the cantilevered praxis: * Back-end database wiring * Exposed API on the gateway * Connected to GUI and command-line front-ends Took the liberty of refactoring some back-end unit tests as well to make the intent more clear. Oh, and found a couple spelling mistakes in the related docs--don’t those tech writers use a spell checker? |
… break that up into smaller pieces. You could easily make a case for this example to use 3 pieces (one for the boojum, one for the refactoring, and one for the spelling corrections) or perhaps 5 pieces. (You could also make a case to use separate PRs instead of just separate commits, but let’s assume that the sum of these is small enough to result in a PR that is modest in size.)
What is powerful about breaking this up into separate commits is that it makes your PR much more digestible by a reviewer. Instead of having to grasp the context of changes in 15 files at once, you might have one commit that involves 5 files, another that involves just 1 file, etc. The set of commits collectively tell a story, but each “chapter” can be read one at a time. In fact, just like you might read an actual book by first skimming through the table of contents, you can similarly begin your review of a PR by skimming through the commit messages. You should then be able to get a sense of the journey that the author went on to get from the start to the end.
Here is a simple, real-life example. Of course, you have absolutely no context, so I will supplement the image with this short description: Using TDD (test driven development), a new test is added in the first commit. The next commit does not say explicitly, but it is implementing new behavior to make that test pass, which involves hydrating some endpoints (the details of what hydration means in this context are unimportant). This hydration needs to be used in some cases but not others, so the third commit allows for that, with both the code and the tests. The final commit, labeled a ‘drive-by’ is unrelated to the PR proper, but it is a one-line change noticed during development so I added it here just to get it done. In GitHub, here are the commits in the PR:
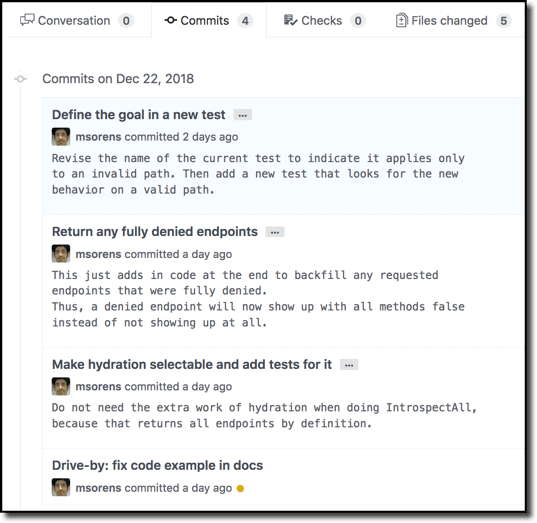
The commit titles tell a story as you read through them. And the details of each commit provide further color to make that story more clear to the reader.
By the way, for a great guide to writing good commit messages, see Chris Beams’ How to Write a Git Commit Message.
PR Preamble
When working on GitHub and you press the button to create a pull request, you are immediately presented with a field for a title and a big empty text box for what I like to call the PR preamble. It is the starting point, the introduction, for your PR. It should include a summary of what the reader will be reviewing, details on how to exercise the code so a reviewer could prove that it works themselves, and more. You and your colleagues should agree upon a standard set of information you want all PRs to include and then store these in a PR template that pre-populates the text box when you create a new PR. See Creating a pull request template for your repository for more.
Your list of items to cover will be uniquely yours, but at a minimum I would recommend a description or summary, a definition of ‘done’ (how does one know your PR achieves its goal?), and the steps to exercise your code (how can a reader prove that your code changes do what they say?).
You should also include a checklist. The one my organization uses every day reminds the PR author to make sure that they have updated docs, added tests, run the tests, and exercised the code. I hear you scoff. But that “silly” checklist works. It substantially increases the likelihood of those “obvious” tasks getting done. I don’t have any citations to back that claim specifically for software, but there are many articles espousing the benefits of a checklist, for example, for a doctor performing a medical procedure or for a pilot readying an aircraft for takeoff. (Example: https://khn.org/news/hospital-checklist-mainbar/).
Here is an example preamble, short enough to fit in a screenshot:
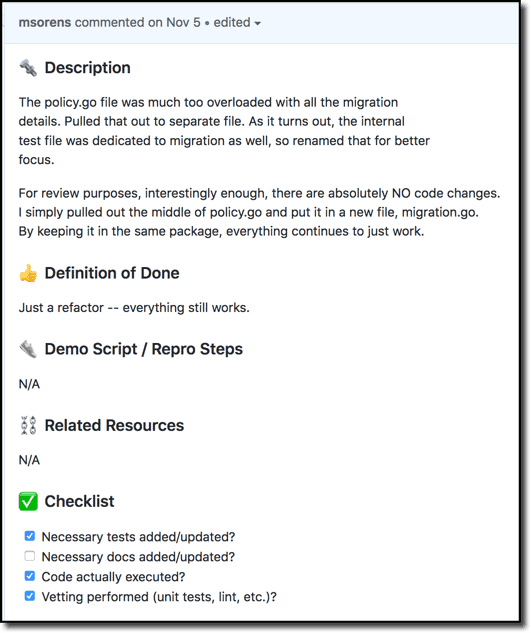
Does your code touch anything in the UI? If so, include screenshots or videos. If you do include screenshots, add arrows, captions and the like to show what code has changed; there is always a lot going on in most any screen shot so, again, help the reader see what your code did.
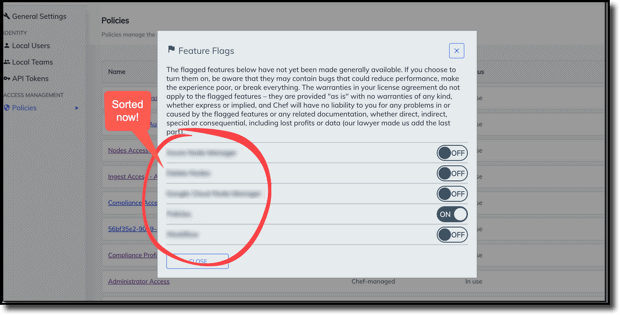
I will often use diagrams, charts, or other images of data even when I am not working in UI-facing code, if I think it will help make my intent more clear.
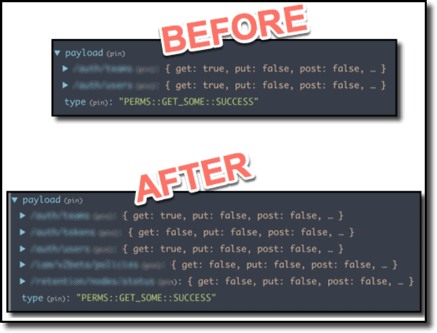
Pre-review Comments
My Zen, part 1, was all about pre-review comments. That was, in fact, its title. In that article I propose that, once your PR is ready to be reviewed, you be your own first reviewer. Read through every changed line of code–not with the intent of critiquing though, rather with the intent of clarifying or explaining if something is not obvious. Pre-review comments serve a similar purpose to in-code comments; the latter also should clarify or explain the non-obvious. The important distinction, though, is that in-code comments explain things that are in the code while pre-review comments explain code that has been changed by the PR. There could certainly be overlap between the two; sometimes it is not clear cut whether a comment should be an in-code comment or a pre-review comment, in which case either will do. But consider the next example. GitHub only presents a small window of context for a given change, a couple lines before and after. In this case, just looking at that window did not seem to me to provide enough clues as to what a reviewer might be looking at, so I introduce the pre-review comment shown. In the finished code, that comment would be useless and, indeed, confusing. But here in the PR it immediately takes the guesswork out of what the reviewer is seeing.
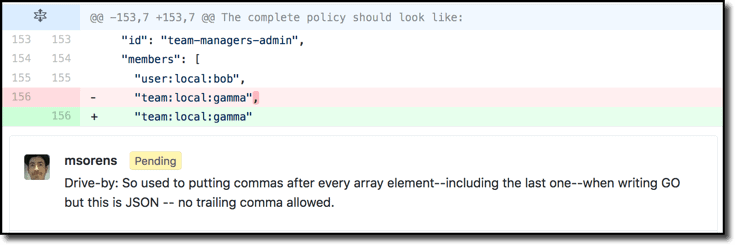
When I wrote that previous article it was without the benefit of commit comments, described above. These add a richer dimension to tell a story, offloading a good portion of what I used to do with just pre-review comments. Commit comments make it so much simpler now to say that such-and-such is the case and applies to these specific lines in these 5 files. When I had only pre-review comments, I would have to add comments on each chunk of code in each relevant file. But these files and these chunks were interspersed with all the other things going on in the code review. So frequently you might see comments saying something like “this line is part of the change for such-and-such, described earlier”. Pre-review comments are still useful, though! They are quite helpful for notating something remarkable within a single commit. I definitely use less of them in favor of commit comments nowadays, but they still prove their value again and again.
Summary
Code reviews are vital when developing software, so understanding how to make a code review more effective and more productive is important for every developer. Besides this article, I encourage you to read my earlier 4-part series, The Zen of Code Review, with two parts devoted to authors and two parts devoted to reviewers:
- Part 1: Pre-Review Comments
- Part 2: Best Practices
- Part 3: The Reviewer’s Tale
- Part 4: Review as if You Own the Code
Load comments