
The Process of Database Refactoring
===+===
This article is excerpted from Chapter 3 of the book titled, ‘Refactoring Databases: Evolutionary Database Design’, authored by Scott Ambler and Pramod Sadalage. Published by Addison-Wesley Professional in March, 2006, ISBN 0-321-29353-3, Copyright 2006. Please visit www.awprofessional.com/title/0321293533 for further information, including a Table of Contents.
===+===
A new scientific truth does not triumph by convincing its opponents and making them see the light, but rather because its opponents eventually die, and a new generation grows up that is familiar with it.
-Max Planck
This article describes how to implement a single refactoring within your database. It contains a worked example of the Move Column structural refactoring, whereby we move the Customer.Balance column to the Account table, a seemingly straightforward change to improve the database design. However, as you will see, even a relatively simple refactoring can be difficult to implement safely within a production environment.
An overview of the refactoring process
Figure 3.1 describes how we will move the Customer.Balance column to the Account table:
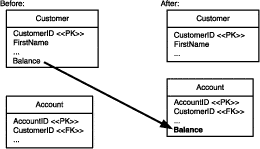
Figure 3.1 Moving the Customer.Balance column to Account
The work carried out in this chapter is that which should be performed within your development sandbox – a working environment in which developers have their own copy of the source code and database to work with. The hard work of database refactoring is done within your development sandbox-it is considered, implemented, and tested before it is promoted into other environments.
NOTE:
Likewise, there are sandboxes for the project-integration environment, where team members promote and then test their changes; preproduction environments for system, integration, and user acceptance testing; and production. This is covered in full detail in Chapter 1 of the book.
Because we are describing what occurs within your development sandbox (Chapter 4 of the book covers the promotion and eventual deployment of your refactorings), this process applies to both the single-application database as well as the multi-application database environments. The only real difference between the two situations is the need for a longer transition period (more on this later) in the multi-application scenario.
Figure 3.2 depicts a UML 2 Activity diagram that overviews the database refactoring process.
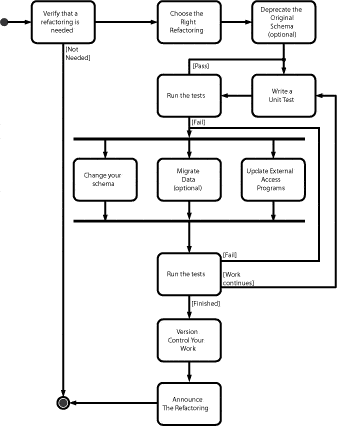
Figure 3.2 The database refactoring process.
The process begins with a developer who is trying to implement a new requirement to fix a defect. The developer realizes that the database schema may need to be refactored. In this example, Eddy, a developer, is adding a new type of financial transaction to his application and realizes that the Balance column actually describes Account entities, not Customer entities. Because Eddy follows common agile practices such as pair programming (Williams & Kessler 2002) and modeling with others (Ambler 2002), he decides to enlist the help of Beverley, the team’s database administrator (DBA), to help him to apply the refactoring. Together they iteratively work through the following activities:
- Verify that a database refactoring is appropriate.
- Choose the most appropriate database refactoring.
- Deprecate the original database schema.
- Test before, during, and after.
- Modify the database schema.
- Migrate the source data.
- Modify external access program(s).
- •Run regression tests.
- Version control the work.
- Announce the refactoring.
3.1 Verify that a database refactoring is appropriate
First, Beverley determines whether the suggested refactoring needs to occur. There are three issues to consider:
Does the refactoring make sense?
Perhaps the existing table structure is correct. It is common for developers to either disagree with, or to simply misunderstand, the existing design of a database. This misunderstanding could lead them to believe that the design needs to change when it really does not. The DBA should have a good knowledge of the project team’s database, other corporate databases, and will know whom to contact about issues such as this. Therefore, they will be in a better position to determine whether the existing schema is the best one. Furthermore, the DBA often understands the bigger picture of the overall enterprise, providing important insight that may not be apparent when you look at it from the point of view of the single project. However, in our example, it appears that the schema needs to change.
Is the change actually needed now?
This is usually a “gut call” based on her previous experience with the application developer. Does Eddy have a good reason for making the schema change? Can Eddy explain the business requirement that the change supports? Does the requirement feel right? Has Eddy suggested good changes in the past? Has Eddy changed his mind several days later, requiring Beverley to back out of the change? Depending on this assessment, Beverley may suggest that Eddy think the change through some more or may decide to continue working with him, but will wait for a longer period of time before they actually apply the change in the project-integration environment, if they believe the change will need to be reversed.
—TIP: Take Small Steps—
Database refactoring changes the schema in small steps; each refactoring should be made one at a time. For example, assume you realize that you need to move an existing column, rename it, and apply a common format to it. Instead of trying this all at once, you should instead successfully implement Move Column, then successfully implement Rename Column, and then apply Introduce Common Format one step at a time. The advantage is that if you make a mistake, it is easy to find the bug because it will likely be in the part of the schema that you just changed.
Is it worth the effort?
The next thing that Beverley does is to assess the overall impact of the refactoring. To do this, Beverley should have an understanding of how the external program(s) are coupled to this part of the database. This is knowledge that Beverley has built up over time by working with the enterprise architects, operational database administrators, application developers, and other DBAs. When Beverley is not sure of the impact, she needs to make a decision at the time and go with her gut feeling or decide to advise the application developer to wait while she talks to the right people. Her goal is to ensure that she implements database refactorings that will succeed-if you are going to need to update, test, and redeploy 50 other applications to support this refactoring, it may not be viable for her to continue. Even when there is only one application accessing the database, it may be so highly coupled to the portion of the schema that you want to change that the database refactoring simply is not worth it. In our example, the design problem is so clearly severe that she decides to implement it even though many applications will be affected.
—TIP: Sometimes the Data Is Elsewhere—
Your database is likely not the only source of data within your organization. A good DBA should at least know about, if not understand, the various data sources within your enterprise to determine the best source of data. In our example, another database could potentially be the official repository of Account information. If that is the case, moving the column may not make sense because the true refactoring would be Use Official Data Source (covered on page 271 of the book).
3.2 Choose the most appropriate database refactoring
You could potentially apply a large number of refactorings to your database schema. To determine which is the most appropriate refactoring for your situation, you must first analyze and understand the problem you face. When Eddy first approached Beverley, he may or may not have done this analysis. For example, he may have just gone to her and said that the Account table needs to store the current balance; therefore, we need to add a new column (via the Introduce Column transformation). However, what he did not realize was that the column already exists in the Customer table, which is arguably the wrong place for it to be-Eddy had identified the problem correctly, but had misidentified the solution. Based on her knowledge of the existing database schema, and her understanding of the problem identified by Eddy, Beverley instead suggests that they apply the Move Column refactoring.
3.3 Deprecate the original database schema
If multiple applications access your database, you will likely need to work under the assumption that you cannot refactor and then deploy all of these programs simultaneously. Instead, you need a transition period, also called a deprecation period, for the original portion of the schema that you are changing (Sadalage & Schuh 2002; Ambler 2003). During the transition period, you support both the original and new schemas in parallel to provide time for the other application teams to refactor and redeploy their systems. Typical transition periods last for several quarters, if not years. The potentially long time to fully implement a refactoring underscores the need to automate as much of the process as possible. Over a several-year period, people within your department will change, putting you at risk if parts of the process are manual. Having said that, even in the case of a single-application database, your team may still require a transition period of a few days within your project-integration sandbox-your teammates need to refactor and retest their code to work with the updated database schema.
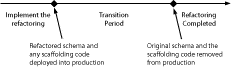
Figure 3.3 The life cycle of a database refactoring in a multi-application scenario.
Figure 3.3 depicts the life cycle of a database refactoring within a multi-application scenario. You first implement it within the scope of your project, and if successful, you eventually deploy it into production. During the transition period, both the original schema and the new schema exist, with sufficient scaffolding code to ensure that any updates are correctly supported. During the transition period, you need to assume two things: first, that some applications will use the original schema whereas others will use the new schema; and second, that applications should only have to work with one but not both versions of the schema. In our example, some applications will work with Customer.Balance and others with Account.Balance, but not both simultaneously. Regardless of which column they work with, the applications should all run properly. When the transition period has expired, the original schema plus any scaffolding code is removed and the database retested. At this point, the assumption is that all applications work with Account.Balance.
Figure 3.4 depicts the original database schema, and Figure 3.5 shows what the database schema would look like during the transition period, when we apply the Move Column database refactoring to Customer.Balance.

Figure 3.4 The original database schema.
In Figure 3.5, the changes are shown in bold, a style that we use throughout the book. Notice how both versions of the schema are supported during this period.
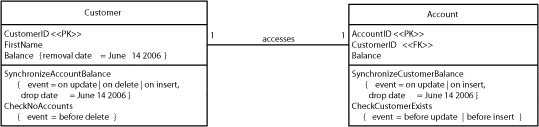
Figure 3.5 Supporting both versions of the schema.
Account.Balance has been added as a column, and Customer.Balance has been marked for removal on or after June 14, 2006. A trigger was also introduced to keep the values contained in the two columns synchronized, the assumption being that new application code will work with Account.Balance but will not keep Customer.Balance up-to-date. Similarly, we assume that older application code that has not been refactored to use the new schema will not know to keep Account.Balance up-to-date. This trigger is an example of database scaffolding code, simple and common code that is required to keep your database “glued together.” This code has been assigned the same removal date as Customer.Balance.
Not all database refactorings require a transition period. For example, neither Introduce Column Constraint nor Apply Standard Codes database refactorings require a transition period because they simply improve the data quality by narrowing the acceptable values within a column. A narrower value may break existing applications, so beware of the refactorings.
NOTE:
Chapter 5, “Database Refactoring Strategies”, of the book discusses strategies for choosing an appropriate transition period.
3.4 Test before, during, and after
You can have the confidence to change your database schema if you can easily validate that the database still works with your application after the change, and the only way to do that is to take a Test-Driven Development (TDD) approach. With a TDD-based approach, you write a test and then you write just enough code, often data definition language (DDL), to fulfill the test. You continue in this manner until the database refactoring has been implemented fully. You will potentially need to write tests that do the following:
- Test your database schema.
- Test the way your application uses the database schema.
- Validate your data migration.
- Test your external program code.
3.4.1 Testing your database schema
Because a database refactoring will affect your database schema, you need to write database-oriented tests. Although this may sound strange at first, you can validate many aspects of a database schema:
- Stored procedures and triggers. Stored procedures and triggers should be tested just like your application code would be.
- Referential integrity (RI). RI rules, in particular cascading deletes in which highly coupled “child” rows are deleted when a parent row is deleted, should also be validated. Existence rules, such as a customer row corresponding to an account row, must exist before the row can be inserted into the Account table, and can be easily tested, too.
- View definitions. Views often implement interesting business logic. Things to look out for include: Does the filtering/select logic work properly? Do you get back the right number of rows? Are you returning the right columns? Are the columns, and rows, in the right order?
- Default values. Columns often have default values defined for them. Are the default values actually being assigned? (Someone could have accidentally removed this part of the table definition.)
- Data invariants. Columns often have invariants, implemented in the forms of constraints, defined for them. For example, a number column may be restricted to containing the values 1 through 7. These invariants should be tested.
- Database testing is new to many people, and as a result you are likely to face several challenges when adopting database refactoring as a development technique:
- Insufficient testing skills. This problem can be overcome through training, through pairing with someone with good testing skills (pairing a DBA without testing skills and a tester without DBA skills still works), or simply through trial and error. The important thing is that you recognize that you need to pick up these skills.
- Insufficient unit tests for your database. Few organizations have yet to adopt the practice of database testing, so it is likely that you will not have a sufficient test suite for your existing schema. Although this is unfortunate, there is no better time than the present to start writing your test suite.
- Insufficient database testing tools. Luckily, tools such as DBUnit (dbunit.sourceforge.net) for managing test data and SQLUnit (sqlunit .sourceforge.net) for testing stored procedures are available as open source software (OSS). In addition, several commercial tools are available for database testing. However, at the time of this writing, there is still significant opportunity for tool vendors to improve their database testing offerings.
So how would we test the changes to the database schema? As you can see in Figure 3.5, there are two changes to the schema during the transition period that we must validate. The first one is the addition of the Balance column to the Account table. This change is covered by our data migration and external program testing efforts, discussed in the following sections. The second change is the addition of the two triggers, SynchronizeAccountBalance and SynchronizeCustomerBalance, which, as their names imply, keep the two data columns synchronized. We need tests to ensure that if Customer.Balance is updated that Account.Balance is similarly updated, and vice versa.
3.4.2 Validating your data migration
Many database refactorings require you to migrate and sometimes even cleanse the source data. In our example, we must copy the data values from Customer.Balance to Account.Balance as part of implementing the refactoring. In this case, we want to validate that the correct balance was in fact copied over for individual customers.

Figure 3.6 The final version of the database schema.
In refactorings such as Apply Standard Codes and Consolidate Key Strategy, you actually “cleanse” data values. This cleansing logic must be validated. With the first refactoring, you may convert code values such as USA and U.S. all to the standard value of US throughout your database. You would want to write tests to validate that the older codes were no longer being used and that they were converted properly to the official value. With the second refactoring, you might discover that customers are identified via their customer ID in some tables, by their social security number (SSN) in other tables, and by their phone number in other tables. You would want to choose one way to identify customers, perhaps by their customer ID, and then refactor the other tables to use this type of column instead. In this case, you would want to write tests to verify that the relationship between the various rows was still being maintained properly. For example, if the telephone number 555-1234 referenced the Sally Jones customer record, the Sally Jones record should still be getting referenced when you replace it with customer ID 987654321.
3.4.3 Testing your external access programs
Your database is accessed by one or more programs, including the application that you are working on. These programs should be validated just like any other IT asset within your organization. To successfully refactor your database, you need to be able to introduce the final schema, shown in Figure 3.6, and see what breaks in your external access programs. The only way that you can have the confidence to refactor your database schema is if you have a full regression test suite for these programs-yes, we realize that you likely do not have these test suites. Once again, there is no better time than the present to start building up your test suite. We suggest that you write all the testing code you require to support each individual database refactoring for all external access programs. (Actually, the owners of these systems need to write those tests, not you.) If you work this way, over time you will build up the test suite that you require.
Load comments