
SQL Server triggers are a subject of both functionality and controversy on any database platform. They can provide immense utility at a low cost, but are often misused by developers, DBAs, and architects alike, resulting in performance bottlenecks or maintainability challenges.
This article briefly reviews DML (data manipulation language) triggers and delves into a discussion about how triggers can be efficiently and effectively used as well as when triggers can dig developers into holes that are hard to escape.
While all demos in this article are in SQL Server, the advice presented here is universal across database platforms. The challenges posed by triggers are also seen in MySQL, PostgreSQL, MongoDB, and many others.
What are triggers?
SQL Server triggers can be defined on the server, database, or table and allow code to automatically execute when specific actions occur. This article focuses on DML triggers on tables as they tend to bear the brunt of over-usage. In contrast, DDL (data definition language) triggers on the database or server are typically more focused and less harmful to performance.
A trigger is a set of code that is evaluated when a data change is made to a table. Triggers may be defined to execute on INSERT, UPDATE, DELETE, or any combination of those operations. MERGE operations fire triggers based on the operations performed by each operation within the MERGE statement.
Triggers may be defined as INSTEAD OF or AFTER the write operation. AFTER triggers take place after data is written to the table and are a distinct and separate set of operations that execute as part of the same transaction that wrote to the table, but after that write occurs. If the trigger fails, the original operation also fails. INSTEAD OF triggers replace the calling write operation. In these scenarios, the INSERT, UPDATE, or DELETE operation never occurs, and the contents of the trigger are executed instead. Each can be valuable depending on the circumstances and the type of code that needs to be managed via triggers.
Ultimately, triggers allow TSQL to be executed when write operations occur, regardless of the source of those writes. They are typically used to run critical operations such as logging, validation, or additional DML in scenarios where there is a desire to ensure that the added code always executes. This is convenient as the source of code does not matter. It could be from an API, application code, release script, or an internal process, and triggers would fire regardless.
What do triggers look like?
Consider the Sales.Orders table in the WideWorldImporters sample database. Imagine that a need arose to log all update or delete actions on this table, along with some detail as to who and when the change occurred. This action could be done via a stored procedure or code, but doing so would require changes to every place in code writes to the table.
To solve this problem via triggers, the following steps could be taken:
1. Create a log table to accept data as it is written. The following TSQL creates a simple log table with all original columns, as well as a few added data points to help understand the source and cause of the change:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
CREATE TABLE Sales.Orders_log ( Orders_log_ID int NOT NULL IDENTITY(1,1) CONSTRAINT PK_Sales_Orders_log PRIMARY KEY CLUSTERED, OrderID int NOT NULL, CustomerID_Old int NOT NULL, CustomerID_New int NOT NULL, SalespersonPersonID_Old int NOT NULL, SalespersonPersonID_New int NOT NULL, PickedByPersonID_Old int NULL, PickedByPersonID_New int NULL, ContactPersonID_Old int NOT NULL, ContactPersonID_New int NOT NULL, BackorderOrderID_Old int NULL, BackorderOrderID_New int NULL, OrderDate_Old date NOT NULL, OrderDate_New date NOT NULL, ExpectedDeliveryDate_Old date NOT NULL, ExpectedDeliveryDate_New date NOT NULL, CustomerPurchaseOrderNumber_Old nvarchar(20) NULL, CustomerPurchaseOrderNumber_New nvarchar(20) NULL, IsUndersupplyBackordered_Old bit NOT NULL, IsUndersupplyBackordered_New bit NOT NULL, Comments_Old nvarchar(max) NULL, Comments_New nvarchar(max) NULL, DeliveryInstructions_Old nvarchar(max) NULL, DeliveryInstructions_New nvarchar(max) NULL, InternalComments_Old nvarchar(max) NULL, InternalComments_New nvarchar(max) NULL, PickingCompletedWhen_Old datetime2(7) NULL, PickingCompletedWhen_New datetime2(7) NULL, LastEditedBy_Old int NOT NULL, LastEditedBy_New int NOT NULL, LastEditedWhen_Old datetime2(7) NOT NULL, LastEditedWhen_New datetime2(7) NOT NULL, ActionType VARCHAR(6) NOT NULL, ActionTime DATETIME2(3) NOT NULL, UserName VARCHAR(128) NULL); |
This table logs the old and new values for all columns. This is very thorough and realistically we could simply log the old version of the rows and be able to infer changes by joining new and old versions together. The choice is up to the developer to determine if the extra columns are acceptable or wasteful and this decision will vary based on each situation. The last 3 columns are new and provide context as to the type of action performed (INSERT, UPDATE, or DELETE), the time, and which user did it.
2. Create a trigger to log changes to the new table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 |
CREATE TRIGGER TR_Sales_Orders_Audit ON Sales.Orders AFTER INSERT, UPDATE, DELETE AS BEGIN SET NOCOUNT ON; INSERT INTO Sales.Orders_log (OrderID, CustomerID_Old, CustomerID_New, SalespersonPersonID_Old, SalespersonPersonID_New, PickedByPersonID_Old, PickedByPersonID_New, ContactPersonID_Old, ContactPersonID_New, BackorderOrderID_Old, BackorderOrderID_New, OrderDate_Old, OrderDate_New, ExpectedDeliveryDate_Old, ExpectedDeliveryDate_New, CustomerPurchaseOrderNumber_Old, CustomerPurchaseOrderNumber_New, IsUndersupplyBackordered_Old, IsUndersupplyBackordered_New, Comments_Old, Comments_New, DeliveryInstructions_Old, DeliveryInstructions_New, InternalComments_Old, InternalComments_New, PickingCompletedWhen_Old, PickingCompletedWhen_New, LastEditedBy_Old, LastEditedBy_New, LastEditedWhen_Old, LastEditedWhen_New, ActionType, ActionTime, UserName) SELECT ISNULL(Inserted.OrderID, Deleted.OrderID) AS OrderID, Deleted.CustomerID AS CustomerID_Old, Inserted.CustomerID AS CustomerID_New, Deleted.SalespersonPersonID AS SalespersonPersonID_Old, Inserted.SalespersonPersonID AS SalespersonPersonID_New, Deleted.PickedByPersonID AS PickedByPersonID_Old, Inserted.PickedByPersonID AS PickedByPersonID_New, Deleted.ContactPersonID AS ContactPersonID_Old, Inserted.ContactPersonID AS ContactPersonID_New, Deleted.BackorderOrderID AS BackorderOrderID_Old, Inserted.BackorderOrderID AS BackorderOrderID_New, Deleted.OrderDate AS OrderDate_Old, Inserted.OrderDate AS OrderDate_New, Deleted.ExpectedDeliveryDate AS ExpectedDeliveryDate_Old, Inserted.ExpectedDeliveryDate AS ExpectedDeliveryDate_New, Deleted.CustomerPurchaseOrderNumber AS CustomerPurchaseOrderNumber_Old, Inserted.CustomerPurchaseOrderNumber AS CustomerPurchaseOrderNumber_New, Deleted.IsUndersupplyBackordered AS IsUndersupplyBackordered_Old, Inserted.IsUndersupplyBackordered AS IsUndersupplyBackordered_New, Deleted.Comments AS Comments_Old, Inserted.Comments AS Comments_New, Deleted.DeliveryInstructions AS DeliveryInstructions_Old, Inserted.DeliveryInstructions AS DeliveryInstructions_New, Deleted.InternalComments AS InternalComments_Old, Inserted.InternalComments AS InternalComments_New, Deleted.PickingCompletedWhen AS PickingCompletedWhen_Old, Inserted.PickingCompletedWhen AS PickingCompletedWhen_New, Deleted.LastEditedBy AS LastEditedBy_Old, Inserted.LastEditedBy AS LastEditedBy_New, Deleted.LastEditedWhen AS LastEditedWhen_Old, Inserted.LastEditedWhen AS LastEditedWhen_New, CASE WHEN Inserted.OrderID IS NULL THEN 'DELETE' WHEN Deleted.OrderID IS NULL THEN 'INSERT' ELSE 'UPDATE' END AS ActionType, SYSUTCDATETIME() ActionTime, SUSER_SNAME() AS UserName FROM Inserted FULL JOIN Deleted ON Inserted.OrderID = Deleted.OrderID; END |
The trigger’s sole function is to insert rows into the log table, one for each row affected by a given write operation. It is simple, set-based, and easy to document and maintain as time passes, and the table changes. Additional columns could be added if needed to track other details, such as database name, server name, a list/count of columns affected, or the calling application.
3. The last step is to test and validate that the log table is populating correctly. The following is a test of an UPDATE on the table after the trigger is added:
|
1 2 3 4 5 6 7 8 |
UPDATE Orders SET InternalComments = 'Item is no longer backordered', BackorderOrderID = NULL, IsUndersupplyBackordered = 0, LastEditedBy = 1, LastEditedWhen = SYSUTCDATETIME() FROM sales.Orders WHERE Orders.OrderID = 10; |
Selecting * from Sales.Orders_log shows the results of the trigger’s execution:
![]()
![]()
Some columns are omitted above, but we can quickly confirm that the changes were captured, including the added action, user, and time columns at the end of the log table.
INSERTED and DELETED tables
In the previous example, data used in the log table was read from INSERTED and DELETED. These are special tables that are available as part of any relevant write operation. INSERT operations will include an INSERTED table, DELETE operations will include a DELETED table, and UPDATE operations will include both an INSERTED and DELETED table.
For INSERT and UPDATE operations, the INSERTED table will include a snapshot of the new values for each column in the table. For DELETE and UPDATE operations, the DELETED table will contain a snapshot of the old values for each column in the table prior to the write operation.
For INSERT operations, the DELETED table will exist but contain no data. Similarly, for DELETE operations, the INSERTED table will not contain any data. Because of this, it is possible to determine programmatically in a trigger what the calling operation is against the table. If DELETED contains no data, then the operation is an INSERT; if INSERTED contains no data, then the operation is a DELETE; if both tables contain data, then the operation is an UPDATE.
These tables are exceptionally convenient as they provide a way to access data affected by a write operation without needing to go back to the underlying table and query for it. Note that INSERTED and DELETED both reside in tempdb and are subject to any space or performance limitations that tempdb has on a given SQL Server.
Because INSTEAD OF INSERT triggers act on data that has yet to be written to a table, identity values will not yet have been determined. If a table contains an identity value, then it will be NULL within an INSTEAD OF INSERT trigger.
When are triggers most useful?
The optimal use of DML triggers is for short, simple, and easy to maintain write operations that act largely independent of an applications business logic.
Some great uses of triggers include:
- Logging changes to a history table
- Auditing users and their actions against sensitive tables.
- Adding additional values to a table that may not be available to an application (due to security restrictions or other limitations), such as:
- Login/user name
- Time an operation occurs
- Server/database name
- Simple validation.
The key to these examples is for trigger code to remain compact enough that it is maintainable. When triggers grow to thousands or tens of thousands of lines, they become black boxes that developers fear to disturb. As a result, more code is added, but old code is rarely reviewed. Even with documentation, this can be challenging to maintain.
For triggers to function efficiently, they should be written to be set-based. If a trigger contains loops (WHILE or CURSOR) or scalar-parameter stored procedures, then operations on multiple rows will be forced to operate on data one row at a time.
If stored procedures must be used within a trigger, ensure that they use table-valued parameters when needed so that data can be moved in a set-based fashion. The following is an example of a trigger that iterates through IDs in order to execute an example stored procedure using the resulting Order IDs:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
CREATE TRIGGER TR_Sales_Orders_Process ON Sales.Orders AFTER INSERT AS BEGIN SET NOCOUNT ON; DECLARE @count INT; SELECT @count = COUNT(*) FROM inserted; DECLARE @min_id INT; SELECT @min_id = MIN(OrderID) FROM inserted; DECLARE @current_id INT = @min_id; WHILE @current_id < @current_id + @count BEGIN EXEC dbo.process_order_fulfillment @OrderID = @current_id; SELECT @current_id = @current_id + 1; END END |
While relatively simple, performance on INSERT operations against Sales.Orders will suffer when multiple rows are inserted at once as SQL Server will be forced to iterate one-by-one as it executes the process_order_fulfillment stored procedure. An easy fix is to rewrite the stored procedure and this code to pass a set of Order IDs into the stored procedure, rather than doing so one-at-a-time:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE TYPE dbo.udt_OrderID_List AS TABLE( OrderID INT NOT NULL, PRIMARY KEY CLUSTERED ( OrderID ASC)); GO CREATE TRIGGER TR_Sales_Orders_Process ON Sales.Orders AFTER INSERT AS BEGIN SET NOCOUNT ON; DECLARE @OrderID_List dbo.udt_OrderID_List; EXEC dbo.process_order_fulfillment @OrderIDs = @OrderID_List; END |
The result of these changes is that the full set of IDs is passed from trigger to stored procedure and processed. As long as the stored procedure manages this data in a set-based fashion, then iteration will be avoided,
That being said, there is great value in avoiding stored procedures within triggers as they add an additional layer of encapsulation that further hides the TSQL that executes when data is written to a table. They should be considered a last resort and used only when the alternative would be to rewrite TSQL many times across many places in an application.
When are triggers dangerous?
Triggers are like Pringles: Once you pop, you can’t stop. One of the greatest challenges for architects and developers is to ensure that triggers are used only as needed, and to not allow them to become a one-size-fits-all solution for any data needs that happen to come along. Adding TSQL to triggers is often seen as faster and easier than adding code to an application, but the cost of doing so is compounded over time with each added line of code.
Triggers can become dangerous when:
- There are too many. Maintain as few triggers as possible to minimize complexity.
- Trigger code becomes complex. If updating a row in a table results in thousands of lines of added trigger code to execute, then it becomes hard for developers to fully understand what happens when data is written to a table. Even worse, troubleshooting can be very challenging when things go wrong.
- Triggers go cross-server. This introduces the network into trigger operations and can result in writes becoming slow or failing when connectivity problems occur. Even cross-database triggers can be problematic if the target database is the subject of maintenance.
- Triggers call triggers. The greatest pain of triggers is when a single row is inserted, and that write operation results in 100 triggers across 75 tables to execute. When writing trigger code, ensure that triggers can perform all necessary logic without triggering more triggers. The extra trigger calls are often unnecessary, but it may be hard to avoid once this deep in the rabbit hole.
- Recursive triggers are set to
ON. This is a database-level setting that is set to off by default. When on, it allows the contents of a trigger to call the same trigger. If recursion is needed, implement it using a less obfuscated method. Recursive triggers can greatly harm performance and are exceptionally confusing to debug. Often, recursive triggers are used when DML within one trigger fires other triggers as part of an operation. Reducing the number of write operations against a table can eliminate the need for this. ConsiderINSTEADOFtriggers as a way to allow data to be altered once, without additional operations after-the-fact being required. - Functions, stored procedures, or views are in triggers. Encapsulating more business logic in triggers makes them more complicated and provides a false impression that a trigger’s code is short and simple, when, in fact, it is not. Avoid using stored procedures and functions when possible in triggers and limit views to scenarios where they are simple and straightforward.
- Iteration occurs.
WHILEloops andCURSORsby nature operate row-by-row and may result in an operation against 1000 rows occurring one row at a time, 1000 times, greatly harming query performance.
This is a long list, but generally can be summarized by stating that short and simple triggers will perform better and avoid most of the pitfalls above. If triggers are used to maintain complex business logic, then it will become more likely with time that more and more business logic will be added, and inevitably best practices above will be violated.
It is important to note that in order to maintain atomic, durable transactions, any objects impacted by a trigger will hold a transaction open until that trigger (and any subsequent triggers) are complete. This means that long triggers will not only make transactions last longer, but will hold locks and cause contention to last longer as well. Therefore, when testing triggers, the effect they have on locking, blocking, and waits should be understood when creating or adding additional logic to existing triggers.
How to improve triggers
There are many ways to make triggers more maintainable, easier to understand, and more performant. The following are some additional thoughts on how to manage triggers effectively and avoid falling into traps.
Document!
The trigger itself should be well documented:
- Why does this trigger exist?
- What does it do?
- How does it work (if it is not blatantly obvious)?
- Are there any exceptions or caveats to how the trigger works?
In addition, if any TSQL within a trigger is confusing or hard to understand for anyone not already familiar with it, then add inline comments to assist developers that may be viewing it for the first time. The following is a sample of how documentation in a trigger can look:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
/* 12/29/2020 EHP This trigger logs all changes to the table to the Orders_log table that occur for non-internal customers. CustomerID = -1 signifies an internal/test customer and these are not audited. */ CREATE TRIGGER TR_Sales_Orders_Audit ON Sales.Orders FOR INSERT, UPDATE, DELETE AS BEGIN SET NOCOUNT ON; INSERT INTO Sales.Orders_log (OrderID, CustomerID_Old, CustomerID_New, SalespersonPersonID_Old, SalespersonPersonID_New, PickedByPersonID_Old, PickedByPersonID_New, ContactPersonID_Old, ContactPersonID_New, BackorderOrderID_Old, BackorderOrderID_New, OrderDate_Old, OrderDate_New, ExpectedDeliveryDate_Old, ExpectedDeliveryDate_New, CustomerPurchaseOrderNumber_Old, CustomerPurchaseOrderNumber_New, IsUndersupplyBackordered_Old, IsUndersupplyBackordered_New, Comments_Old, Comments_New, DeliveryInstructions_Old, DeliveryInstructions_New, nternalComments_Old, InternalComments_New, PickingCompletedWhen_Old, PickingCompletedWhen_New, LastEditedBy_Old, LastEditedBy_New, LastEditedWhen_Old, LastEditedWhen_New, ActionType, ActionTime, UserName) SELECT ISNULL(Inserted.OrderID, Deleted.OrderID) AS OrderID, -- The OrderID can never change. --This ensures we get the ID correctly, --regardless of operation type. Deleted.CustomerID AS CustomerID_Old, Inserted.CustomerID AS CustomerID_New, Deleted.SalespersonPersonID AS SalespersonPersonID_Old, Inserted.SalespersonPersonID AS SalespersonPersonID_New, Deleted.PickedByPersonID AS PickedByPersonID_Old, Inserted.PickedByPersonID AS PickedByPersonID_New, Deleted.ContactPersonID AS ContactPersonID_Old, Inserted.ContactPersonID AS ContactPersonID_New, Deleted.BackorderOrderID AS BackorderOrderID_Old, Inserted.BackorderOrderID AS BackorderOrderID_New, Deleted.OrderDate AS OrderDate_Old, Inserted.OrderDate AS OrderDate_New, Deleted.ExpectedDeliveryDate AS ExpectedDeliveryDate_Old, Inserted.ExpectedDeliveryDate AS ExpectedDeliveryDate_New, Deleted.CustomerPurchaseOrderNumber AS CustomerPurchaseOrderNumber_Old, Inserted.CustomerPurchaseOrderNumber AS CustomerPurchaseOrderNumber_New, Deleted.IsUndersupplyBackordered AS IsUndersupplyBackordered_Old, Inserted.IsUndersupplyBackordered AS IsUndersupplyBackordered_New, Deleted.Comments AS Comments_Old, Inserted.Comments AS Comments_New, Deleted.DeliveryInstructions AS DeliveryInstructions_Old, Inserted.DeliveryInstructions AS DeliveryInstructions_New, Deleted.InternalComments AS InternalComments_Old, Inserted.InternalComments AS InternalComments_New, Deleted.PickingCompletedWhen AS PickingCompletedWhen_Old, Inserted.PickingCompletedWhen AS PickingCompletedWhen_New, Deleted.LastEditedBy AS LastEditedBy_Old, Inserted.LastEditedBy AS LastEditedBy_New, Deleted.LastEditedWhen AS LastEditedWhen_Old, Inserted.LastEditedWhen AS LastEditedWhen_New, CASE -- Determine the operation type based on whether --Inserted exists, Deleted exists, or both exist. WHEN Inserted.OrderID IS NULL THEN 'DELETE' WHEN Deleted.OrderID IS NULL THEN 'INSERT' ELSE 'UPDATE' END AS ActionType, SYSUTCDATETIME() ActionTime, SUSER_SNAME() AS UserName FROM Inserted FULL JOIN Deleted ON Inserted.OrderID = Deleted.OrderID WHERE Inserted.CustomerID <> -1 -- -1 indicates an internal/non-production --customer that should not be audited. OR Deleted.CustomerID <> -1; -- -1 indicates an internal/non-production --customer that should not be audited. END |
Note that the documentation is not extensive, but includes a brief header and explains a few key pieces of TSQL within the trigger:
- The exclusion of CustomerID = -1. This would not be obvious to anyone who does not happen to know it, so it is an excellent comment.
- What the CASE statement for ActionType is for.
- Why ISNULL is used on the OrderID column between Inserted and Deleted.
Use IF UPDATE
Within triggers, the UPDATE function provides the ability to determine if an update or insert operation attempted to write data to a given column. This can allow a trigger to check to see if a column changed prior to joining tables and performing operations. The following is an example of this syntax:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE TRIGGER TR_Sales_Orders_Log_BackorderID_Change ON Sales.Orders AFTER UPDATE AS BEGIN SET NOCOUNT ON; IF UPDATE(BackorderOrderID) BEGIN UPDATE OrderBackorderLog SET BackorderOrderID = Inserted.BackorderOrderID, PreviousBackorderOrderID = Deleted.BackorderOrderID FROM dbo.OrderBackorderLog INNER JOIN Inserted ON Inserted.OrderID = OrderBackorderLog.OrderID END END |
By checking first if BackorderID was updated, the trigger can bypass the subsequent operations when not needed, thus avoiding the need to query Inserted and OrderBackorderLog. For triggers where TSQL is not needed often, this is a great way to improve performance by allowing the trigger to skip the code altogether based on the UPDATE values for columns needed.
COLUMNS_UPDATED is a VARBINARY bit pattern that indicates which columns within a table were updated as part of a write operation and can be used within a trigger to quickly determine if a specific set of columns was affected by an INSERT or UPDATE operation. While documented and a legitimate way to determine the columns affected by a write operation, it is complex to use and hard to document. I generally advise against using it as it is almost guaranteed to confuse developers unfamiliar with it.
IF UPDATE may be more verbose, but it is efficient and easy to understand, even if many columns are involved.
Note that it does not matter if a column changes or not for UPDATE or COLUMNS_UPDATED to flag that column as updated. An operation that writes to a column, even if the value does not change will still return 1 for UPDATE or a 1 in the bit pattern for COLUMNS_UPDATED. These bits only track if a column was the target of a write operation, not whether the value itself changed.
One trigger per operation
Keep trigger code as simple as possible. Maintain a single insert, update, and delete trigger at most. Allowing the number of triggers on a table to grow greatly increases the complexity of the table and makes understanding its operation harder. One-trigger-per-action ensures that trigger order is never an important consideration, also improving maintainability of code and reducing complexity.
A trigger that covers multiple actions is useful, but avoid triggers that mix and match action types repeatedly. For example, consider the following table trigger definition stubs:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE TRIGGER TR_Sales_Orders_I ON Sales.Orders AFTER INSERT CREATE TRIGGER TR_Sales_Orders_IU ON Sales.Orders AFTER INSERT, UPDATE CREATE TRIGGER TR_Sales_Orders_UD ON Sales.Orders AFTER UPDATE, DELETE CREATE TRIGGER TR_Sales_Orders_UID ON Sales.Orders AFTER UPDATE, INSERT, DELETE CREATE TRIGGER TR_Sales_Orders_ID ON Sales.Orders AFTER INSERT, DELETE |
What happens when a row is inserted? What about a MERGE operation that inserts and updates? In what order do triggers fire? The answer to these questions requires some head-scratching and research. This complexity is not worth the headache it causes. Maintaining less triggers is an easy solution and removes the guesswork from understanding how writes occur within a given table.
For reference, trigger order can be modified by using the system stored procedure sp_settriggerorder, though this only applies to AFTER triggers.
Keep it simple
Optimal triggers perform straightforward operations, perform quickly, and do not cause more triggers or modules to fire due to their execution.
There is no firm rule on how simple or complex a trigger should be, but a simple guideline is that the ideal triggers are simple enough that, if the logic contained within had to be removed from a trigger to elsewhere, the move would not be prohibitively expensive. That is, if the business logic in a trigger is so complex that moving it becomes too expensive to consider, then it is likely that those triggers have become too complex.
Using our earlier example, consider a trigger that logs changes to an audit table. This could easily be moved from the trigger to a stored procedure or to code, and the effort to do so would not be significant. The convenience of that logging process residing in a trigger makes it worthwhile, but at the same time, we could quantify how many hours it would take developers to migrate that TSQL from trigger to another location.
That count of hours can be seen as part of the maintainability cost for any given trigger. That is, the price that would need to be paid to get rid of the trigger if needed. This may sound abstract, but database migrations between platforms are common. A set of triggers that perform well in SQL Server might not be effective in Oracle or PostgreSQL. Similarly, migrating to a database variant that does not support the same level of trigger functionality might necessitate removing or simplifying triggers.
Memory optimized table variables
Sometimes, temporary tables are needed within a trigger to allow multiple updates against data or to facilitate clean inserts from an INSTEAD OF INSERT trigger. Temporary tables are stored in tempdb and are subject to whatever size, speed, and performance constraints are present on the tempdb database.
For temporary tables that are accessed often, a memory-optimized table variable is an excellent way to maintain temporary data in-memory, rather than in tempdb.
The following TSQL configures a database for memory-optimized data (if needed):
|
1 2 3 4 5 6 7 8 |
ALTER DATABASE WideWorldImporters SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT = ON; ALTER DATABASE WideWorldImporters ADD FILEGROUP WWI_InMemory_Data CONTAINS MEMORY_OPTIMIZED_DATA; ALTER DATABASE WideWorldImporters ADD FILE (NAME='WideWorldImporters_IMOLTP_File_1', FILENAME='C:\SQLData\WideWorldImporters_IMOLTP_File_1.mem') TO FILEGROUP WWI_InMemory_Data; |
Once configured, a memory-optimized table-type can be created:
|
1 2 3 4 5 6 7 8 9 |
CREATE TYPE dbo.SalesOrderMetadata AS TABLE ( OrderID INT NOT NULL PRIMARY KEY NONCLUSTERED, CustomerID INT NOT NULL, SalespersonPersonID INT NOT NULL, ContactPersonID INT NOT NULL, INDEX IX_SalesOrderMetadata_CustomerID NONCLUSTERED HASH (CustomerID) WITH (BUCKET_COUNT = 1000)) WITH (MEMORY_OPTIMIZED = ON); |
This TSQL creates a table needed by the trigger demonstrated below:
|
1 2 3 4 5 6 7 8 |
CREATE TABLE dbo.OrderAdjustmentLog ( OrderAdjustmentLog_ID int NOT NULL IDENTITY(1,1) CONSTRAINT PK_OrderAdjustmentLog PRIMARY KEY CLUSTERED, OrderID INT NOT NULL, CustomerID INT NOT NULL, SalespersonPersonID INT NOT NULL, ContactPersonID INT NOT NULL, CreateTimeUTC DATETIME2(3) NOT NULL); |
The following is a demo of a trigger that makes use of a memory-optimized table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
CREATE TRIGGER TR_Sales_Orders_Mem_Test ON Sales.Orders AFTER UPDATE AS BEGIN SET NOCOUNT ON; DECLARE @OrderData dbo.SalesOrderMetadata; INSERT INTO @OrderData (OrderID, CustomerID, SalespersonPersonID, ContactPersonID) SELECT OrderID, CustomerID, SalespersonPersonID, ContactPersonID FROM Inserted; DELETE OrderData FROM @OrderData OrderData INNER JOIN sales.Customers ON Customers.CustomerID = OrderData.CustomerID WHERE Customers.IsOnCreditHold = 0; UPDATE OrderData SET ContactPersonID = 1 FROM @OrderData OrderData WHERE OrderData.ContactPersonID IS NULL; INSERT INTO dbo.OrderAdjustmentLog (OrderID, CustomerID, SalespersonPersonID, ContactPersonID, CreateTimeUTC) SELECT OrderData.OrderID, OrderData.CustomerID, OrderData.SalespersonPersonID, OrderData.ContactPersonID, SYSUTCDATETIME() FROM @OrderData OrderData; END |
The more operations required within the trigger, the more savings will be seen as the memory-optimized table variable requires no IO to read/write. Once the initial data from the INSERTED table is read, the remainder of the trigger can leave tempdb alone, reducing the potential contention that would be caused if standard table variables or temporary tables were used.
The following code sets up some test data and runs an update to demonstrate the results of the above code:
|
1 2 3 4 5 6 7 8 |
UPDATE Customers SET IsOnCreditHold = 1 FROM Sales.Customers WHERE Customers.CustomerID = 832; UPDATE Orders SET SalespersonPersonID = 2 FROM sales.Orders WHERE CustomerID = 832; |
Once executed, the contents of the OrderAdjustmentLog table can be validated:
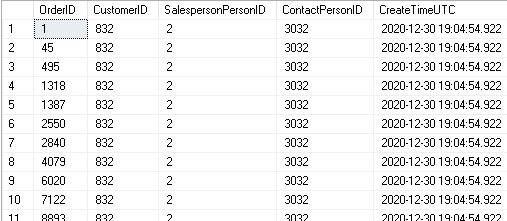
The results are as expected. Memory-optimized tables provide a way to greatly improve trigger speeds by reducing reliance on standard storage and moving intermediary tables into memory. This is limited to scenarios where there will be a great deal of contention or IO against temporary objects, but can also be useful in stored procedures or other procedural TSQL.
Alternatives to triggers
Like all tools, triggers can effectively tackle the problems that they are optimized for conquering. Similarly, they can be misused and become the source of confusion, performance bottlenecks, and maintainability nightmares. Many alternatives exist that are preferable to triggers and should be considered prior to implementing (or adding onto existing) triggers.
Temporal tables
Temporal tables were introduced in SQL Server 2016 and provide an easy way to add versioning to a table without building your own data structures and ETL. This logging is invisible to applications and provides full versioning support that is ANSI compliant, allowing it to be an easy way to solve the problem of saving old versions of data.
A temporal table is defined with its own history table, as well as columns that are populated with the times that the data is valid from/to.
This is a rich SQL Server feature that provides a set of expressions to quickly return data for a point in time or any period of time. A full demo of it would be quite space-consuming here, but more info can be found here.
Check constraints
For simple data validation, check constraints can provide exactly what is needed without the need for functions, stored procedures, or triggers. A check constraint is defined on a column and validates data automatically when it is created. The following is an example of a check constraint:
|
1 2 3 4 |
ALTER TABLE Sales.Invoices WITH CHECK ADD CONSTRAINT CK_Sales_Invoices_ReturnedDeliveryData_Must_Be_Valid_JSON CHECK ([ReturnedDeliveryData] IS NULL OR ISJSON([ReturnedDeliveryData])<>(0)) |
This code checks to see if a column is valid JSON or not. If it is, then execution proceeds normally. If not, then an error will be thrown by SQL Server and the write operation would fail. Check constraints can check for any combination of column and values, and therefore can manage both simple or complex validation tasks.
Check constraints are inexpensive to create and easy to maintain. They are also easier to document and understand as the scope of a check constraint is limited to validating incoming data and ensuring data integrity, whereas triggers can do practically anything imaginable!
Unique constraints
If a column needs to be unique and is not the primary key on the table, then a unique constraint is an easy and efficient way to accomplish the task. A unique constraint is the combination of an index and enforcement of uniqueness. The index is necessary to allow for uniqueness to be validated efficiently (without it, a table scan would be required anytime the unique columns were written).
The following is an example of a unique constraint:
|
1 2 |
ALTER TABLE Warehouse.Colors ADD CONSTRAINT UQ_Warehouse_Colors_ColorName UNIQUE NONCLUSTERED (ColorName ASC); |
Whenever a row is inserted into the Warehouse.Colors table, the color name will be checked for uniqueness. If the write operation happens to result in duplication of a color, then the statement will fail and data will not be changed.
Unique constraints are built for this purpose and are the easiest way to enforce uniqueness on a column. This functionality has no place in triggers and the built-in solution will be more efficient, easier to maintain, and easier to document. Any developer seeing a unique constraint will immediately understand what it does without the need to dig deeper into TSQL to figure out how things work and that simplicity makes this an ideal solution.
Foreign key constraints
Like check constraints and unique constraints, foreign key constraints are another way to validate data integrity before data is written. A foreign key links a column in one table to a source table. Whenever data is inserted into the target table, its value is checked against the referenced table. If the value exists, the write operation proceeds normally. If not, then an error is thrown, and the statement fails.
This is a simple foreign key example:
|
1 2 3 |
ALTER TABLE Sales.Orders WITH CHECK ADD CONSTRAINT FK_Sales_Orders_CustomerID_Sales_Customers FOREIGN KEY (CustomerID) REFERENCES Sales.Customers (CustomerID); |
When data is written to Sales.Orders, the CustomerID column will be checked against the CustomerID column in Sales.Customers.
Similar to unique constraints, foreign keys have only one purpose: validate that data being written to one table exists in another table. It is easy to document, simple to understand, and is efficient in its implementation.
Additionally, foreign keys can be configured to CASCADE, allowing the removal or parent data to automatically remove/NULL the child data. This is a convenient way to maintain data integrity when a set of data involved in relationships should all be changed at once.
Triggers are not the correct place to perform these validation checks and will be the less efficient solution compared to using foreign keys.
Stored procedures
Oftentimes the logic implemented in triggers can easily be moved into a stored procedure that is executed by the calling application. This removes the contention, complexity, and obfuscation that extensive trigger code can result in while allowing developers to maintain their processes accordingly.
Stored procedures provide the freedom to structure operations to ensure as much (or as little) atomicity as possible. One of the rationales often used for implementing triggers is ensuring a set of operations occur in line with a write operation. All successes or failures fail as part of an atomic transaction. Applications do not always require this level of atomicity. If necessary, the appropriate isolation levels or table locking can be used from within a stored procedure to guarantee a transaction’s integrity.
While SQL Server (and most RDBMS) provide the ACID guarantee that transactions will be atomic, consistent, isolated, and durable, sets of transactions within our own code may or may not need to follow the same rules. Real-world applications vary in their data integrity needs, anywhere from Real-time & Atomic to Eventually Consistent.
A stored procedure allows code to be customized to achieve the data integrity required by an application, ensuring that performance and computing resources are not wasted on unneeded data integrity. For example, a social media app that allows users to post cat photos is not likely to need its transactions to be fully atomic and consistent. If my cat photo arrives a second before or after yours, no one will care. Similarly, if you comment on my photo while I am editing it, the timing likely won’t matter to anyone using this data.
On the other hand, a banking app that manages monetary transactions would need to ensure that transactions are carefully executed so that there is no way for money to go missing or numbers to be reported incorrectly. If I have a bank account containing $20 and I withdraw $20 at the same time that someone else does, there can be no way for us to both succeed. One of us goes first and gets $20, and the other encounters an appropriate error message regarding the $0 balance.
Functions
Functions provide an easy way to encapsulate important logic into a single place where it can then be applied to data. They are often a superior option to triggers when they can be reused repeatedly and do not cause performance bottlenecks. A single function that is reused in 50 table inserts is far easier to code and maintain than 50 triggers, one per table, that all perform the same logic.
Consider the following function:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 |
CREATE FUNCTION Website.CalculateCustomerPrice (@CustomerID INT, @StockItemID INT, @PricingDate DATE) RETURNS DECIMAL(18,2) WITH EXECUTE AS OWNER AS BEGIN DECLARE @CalculatedPrice decimal(18,2); DECLARE @UnitPrice decimal(18,2); DECLARE @LowestUnitPrice decimal(18,2); DECLARE @HighestDiscountAmount decimal(18,2); DECLARE @HighestDiscountPercentage decimal(18,3); DECLARE @BuyingGroupID int; DECLARE @CustomerCategoryID int; DECLARE @DiscountedUnitPrice decimal(18,2); SELECT @BuyingGroupID = BuyingGroupID, @CustomerCategoryID = CustomerCategoryID FROM Sales.Customers WHERE CustomerID = @CustomerID; SELECT @UnitPrice = si.UnitPrice FROM Warehouse.StockItems AS si WHERE si.StockItemID = @StockItemID; SET @CalculatedPrice = @UnitPrice; SET @LowestUnitPrice = ( SELECT MIN(sd.UnitPrice) FROM Sales.SpecialDeals AS sd WHERE ((sd.StockItemID = @StockItemID) OR (sd.StockItemID IS NULL)) AND ((sd.CustomerID = @CustomerID) OR (sd.CustomerID IS NULL)) AND ((sd.BuyingGroupID = @BuyingGroupID) OR (sd.BuyingGroupID IS NULL)) AND ((sd.CustomerCategoryID = @CustomerCategoryID) OR (sd.CustomerCategoryID IS NULL)) AND ((sd.StockGroupID IS NULL) OR EXISTS (SELECT 1 FROM Warehouse.StockItemStockGroups AS sisg WHERE sisg.StockItemID = @StockItemID AND sisg.StockGroupID = sd.StockGroupID)) AND sd.UnitPrice IS NOT NULL AND @PricingDate BETWEEN sd.StartDate AND sd.EndDate); IF @LowestUnitPrice IS NOT NULL AND @LowestUnitPrice < @UnitPrice BEGIN SET @CalculatedPrice = @LowestUnitPrice; END; SET @HighestDiscountAmount = ( SELECT MAX(sd.DiscountAmount) FROM Sales.SpecialDeals AS sd WHERE ((sd.StockItemID = @StockItemID) OR (sd.StockItemID IS NULL)) AND ((sd.CustomerID = @CustomerID) OR (sd.CustomerID IS NULL)) AND ((sd.BuyingGroupID = @BuyingGroupID) OR (sd.BuyingGroupID IS NULL)) AND ((sd.CustomerCategoryID = @CustomerCategoryID) OR (sd.CustomerCategoryID IS NULL)) AND ((sd.StockGroupID IS NULL) OR EXISTS (SELECT 1 FROM Warehouse.StockItemStockGroups AS sisg WHERE sisg.StockItemID = @StockItemID AND sisg.StockGroupID = sd.StockGroupID)) AND sd.DiscountAmount IS NOT NULL AND @PricingDate BETWEEN sd.StartDate AND sd.EndDate); IF @HighestDiscountAmount IS NOT NULL AND ( @UnitPrice - @HighestDiscountAmount) < @CalculatedPrice BEGIN SET @CalculatedPrice = @UnitPrice - @HighestDiscountAmount; END; SET @HighestDiscountPercentage = ( SELECT MAX(sd.DiscountPercentage) FROM Sales.SpecialDeals AS sd WHERE ((sd.StockItemID = @StockItemID) OR (sd.StockItemID IS NULL)) AND ((sd.CustomerID = @CustomerID) OR (sd.CustomerID IS NULL)) AND ((sd.BuyingGroupID = @BuyingGroupID) OR (sd.BuyingGroupID IS NULL)) AND ((sd.CustomerCategoryID = @CustomerCategoryID) OR (sd.CustomerCategoryID IS NULL)) AND ((sd.StockGroupID IS NULL) OR EXISTS (SELECT 1 FROM Warehouse.StockItemStockGroups AS sisg WHERE sisg.StockItemID = @StockItemID AND sisg.StockGroupID = sd.StockGroupID)) AND sd.DiscountPercentage IS NOT NULL AND @PricingDate BETWEEN sd.StartDate AND sd.EndDate); IF @HighestDiscountPercentage IS NOT NULL BEGIN SET @DiscountedUnitPrice = ROUND(@UnitPrice * @HighestDiscountPercentage / 100.0, 2); IF @DiscountedUnitPrice < @CalculatedPrice SET @CalculatedPrice = @DiscountedUnitPrice; END; RETURN @CalculatedPrice; END; |
That is an absolute beast in terms of complexity. While it accepts scalar parameters to determine a calculated price, the operations it performs are vast and even include additional reads to Warehouse.StockItemStockGroups, Warehouse.StockItems, and Sales.Customers. If this is a critical calculation that is used against single rows of data often, then encapsulating it in a function is an easy way to get the needed calculation without introducing the added complexity of triggers. Use caution with functions and be sure to test with large data sets. A simple scalar function will generally scale well with larger data, but more complex functions can perform poorly. Scalar UDF Inlining in SQL Server 2019 helps with this challenge, but sufficient testing should be performed, regardless of SQL Server version.
A stored procedure could also be used, but the function might provide the added benefit of inlining the operation, allowing the calculation to occur as part of a write operation. An added benefit of this approach is that the code resides in one place and can be altered whenever needed in one place. Similarly, places that utilize the function can be adjusted to stop using it, or change how they use it. All of this can be accomplished independently of triggers, ensuring that code remains relatively easy to document and maintain, even if the logic underneath it is as complex as in the function presented above.
Code
When data is modified in a table from an application, it can also perform additional data manipulation or validation prior to writing the data. This is generally inexpensive, performs well, and helps reduce the negative impact of runaway triggers on a database.
The common rationale for putting code into triggers instead is that it avoids the need to modify code, push builds, and otherwise incur the time and risk of making application changes. This runs directly counter to any risk related to making changes within the database. Often this is a discussion between application developers and database developers as to who will be responsible for new code.
In general, if a trigger’s function addresses solely change coming from an application, then the application is the ideal place for that code (and not a trigger). If a trigger’s function addresses DML that could originate anywhere (application, API, stored procedures, etc…), then a trigger may very well be a better solution as it avoids the need to try and add code to all of those places and then be forced to maintain it after-the-fact.
This is a rough guideline but helps in measuring maintainability and risk after code is added either to an application or a trigger.
Computed columns
Computed columns are exceptionally useful ways to maintain metrics in a table that stay up-to-date, even as other columns change. A computed column can include a wide variety of arithmetic operations and functions. They can be included in indexes, and if deterministic, then they can be included in unique constraints and even primary keys.
Computed columns are automatically maintained by SQL Server when any underlying values change and cannot be inserted or updated.
The following are some examples of computed columns in WideWorldImporters:
|
1 2 3 4 5 6 7 |
[ConfirmedDeliveryTime] AS (TRY_CONVERT([datetime2](7),json_value([ReturnedDeliveryData], N'$.DeliveredWhen'),(126))), [ConfirmedReceivedBy] AS (json_value([ReturnedDeliveryData],N'$.ReceivedBy')), [IsFinalized] AS (case when [FinalizationDate] IS NULL then CONVERT([bit],(0)) else CONVERT([bit],(1)) end) PERSISTED, |
Note that each computed column is ultimately determined by the values of other columns in the table. The PERSISTED keyword stores the computed column physically in the table, rather than calculating its value as needed at runtime.
This is an excellent alternative to using triggers to maintain special column values. Computed columns are efficient, automatic, and require no maintenance. They simply work and allow even complex calculations to be integrated directly into a table with no additional code required in the application or in SQL Server.
Service Broker
Triggers are sometimes used for managing queues and messaging as a way to ensure that DML directly results in tasks to be processed asynchronously elsewhere in the future. While this works, it also ties together the source transactional process to a destination messaging process. This can be expensive, complex, and hard to maintain.
Service Broker is built to manage sending messages between queues and does so efficiently. It can be used for simple use-cases, such as queuing tasks to process or logging processes to execute at a future time. It can also be used to divide processing workloads between servers, allowing expensive ETL or other costly processes to be offloaded away from a critical production system and onto another system dedicated to those purposes.
Service Broker is a mature SQL Server feature, but one that includes quite a bit of new syntax to learn and use, therefore this article is not an ideal place to walk through its use. There is quite a bit of documentation out there, and Microsoft’s documentation is a good place to start.
When considering using triggers for queuing and/or messaging, consider Service Broker first. It will usually be the right tool for the job and avoids the need to manually maintain queue tables and queue-management processes. Databases are not designed to be good queues, so implementing Service Broker or a 3rd party utility designed for this purpose will provide an easier-to-maintain solution that performs better.
Using SQL Server triggers
Triggers are a useful feature in SQL Server, but like all tools, one that can be misused or overused. When deciding whether to use triggers or not, consider the trigger’s purpose, and if it is the correct solution to the problem it is attempting to resolve.
If a trigger is being used to write brief transaction data to a log table, it is likely a good use of a trigger. If the trigger is being used to enforce a dozen complex business rules, then odds are it is worth reconsidering the best way to handle that sort of validation.
With many tools available as viable alternatives to triggers, such as check constraints, computed columns, and temporal tables, there is no shortage of ways to solve a problem. Success in database architecture is choosing the correct tool for the job, knowing that the time spent on that decision will save far more time and resources in the future had a poor decision been made.
If you like this article, you might also like Triggers: Threat or Menace?



Load comments