
A columnstore index in SQL Server stores data organized by column rather than by row. Instead of keeping entire rows together on data pages, a columnstore index groups values from the same column into compressed segments, with each segment holding up to approximately 1 million rows (a rowgroup). This architecture delivers two major benefits: compression ratios of 10:1 or better (since similar values within a column compress efficiently), and dramatic query speedups for analytical workloads (since queries that aggregate a few columns can skip all other columns entirely).
Columnstore indexes are ideal for data warehouse fact tables, reporting workloads, and any scenario involving large-table aggregations. SQL Server supports both clustered columnstore indexes (the table’s primary storage) and nonclustered columnstore indexes (an analytical overlay on a rowstore table).
Introduction
Columnstore indexes were first introduced in SQL Server 2012. They are a new way to store the data from a table that improves the performance of certain query types by at least ten times. They are especially helpful with fact tables in data warehouses.
Now, I admit that when columnstore indexes were first introduced, I found them very intimidating. Back then, you couldn’t update a table with a columnstore index without removing it first. Fortunately, there have been many improvements since then. For me, anytime you say columnstore, my mind tends to set off alarms saying, “wait, stay away, this is too complicated.” So, I am going to try and simplify the feature for you. These indexes are very useful for data warehouse workloads and large tables. They can improve query performance by a factor of 10 in some cases, so knowing and understanding how they work is essential if you work in an environment with larger scaled data. They are worth taking the time to learn.
Architecture of Columnstore Indexes
First, you need to understand some terminology and the difference between a columnstore index and a row store index (the typical kind we all use). I’ll start with the terminology.
Columnstore simply means a new way to store the data in the index. Instead of the normal Rowstore or b-tree indexes where the data is logically and physically organized and stored as a table with rows and columns, the data in columnstore indexes are physically stored in columns and logically organized in rows and columns. Instead of storing an entire row or rows in a page, one column from many rows is stored in that page. It is this difference in architecture that gives the columnstore index a very high level of compression along with reducing the storage footprint and providing massive improvements in read performance.
The index works by slicing the data into compressible segments. It takes a group of rows, a minimum of 102,400 rows with a max of about 1 million rows, called a rowgroup and then changes that group of rows into Column segments. It’s these segments that are the basic unit of storage for a columnstore index, as shown below. This, to me, is a little tricky to understand without a picture.
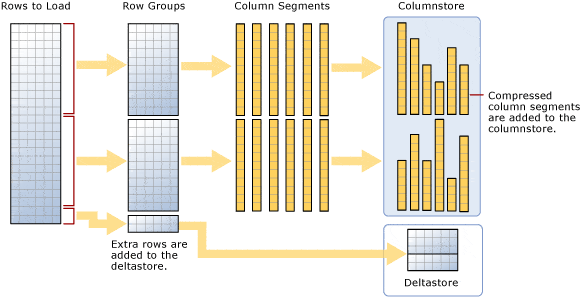
(Image from Microsoft)
Imagine this is a table with 2.1 million rows and six columns. Which means that there are now two rowgroups of 1,048,576 rows each and a remainder of 2848 rows, which is called a deltagroup. Since each rowgroup holds a minimum of 102,400 rows, the delta rowgroup is used to store all index records remaining until it has enough rows to create another rowgroup. You can have multiple delta rowgroups awaiting being moved to the columnstore. Multiple delta groups are stored in the delta store, and it is actually a B-tree index used in addition to the columnstore. Ideally, your index will have rowgroups containing close to 1 million rows as possible to reduce the overhead of scanning operations.
Now to complicate things just one step further, there is a process that runs to move delta rowgroups from the delta store to the columnstore index called a tuple-mover process. This process checks for closed groups, meaning a group that has a maximum of 1 million records and is ready to be compressed and added to the index. As illustrated in the picture, the columnstore index now has two rowgroups that it will then divide into column segments for every column in a table. This creates six pillars of 1 million rows per rowgroup for a total of 12 column segments. Make sense? It is these column segments that are compressed individually for storage on disk. The engine takes these pillars and uses them for very highly paralleled scans of the data. You can also force the tuple-mover process by doing a reorg on your columnstore index.
To facilitate faster data access, only the Min and Max values for the row group are stored on the page header. In addition, query processing, as it relates to column store, uses Batch mode allowing the engine to process multiple rows at one time. This also makes the engine able to process rows extremely fast in some cases, giving two to four times the performance of a single query process. For example, if you are doing an aggregation, these happen very quickly as only the row being aggregated is read into memory and using the row groups the engine can batch process the groups of 1 million rows. In SQL Server 2019, batch mode is also going to be introduced to some row store indexes and execution plans.
Another interesting difference between columnstore indexes and b-tree indexes is that columnstore indexes do not have keys. You can also add all the columns found in the table, as long as they are not a restricted data type, to a non-clustered columnstore index, and there is no concept of included columns. This is a radically new way of thinking if you are used to tuning traditional indexes.
Columnstore Example
Now, hopefully, you have a basic understanding of what a columnstore index is. Now, look at how to create one, and learn what limitations using columnstore indexes have, and see the index in action compared to a rowstore index.
This example will use AdventureworksDW2016CTP3 and the FactResellerSalesXL table (script below), which has 11.6 million rows in it. The simple query will select the ProductKey and returns some aggregations grouping them by the different product keys.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
USE [AdventureworksDW2016CTP3] GO SELECT * into FactResellerSalesXL From FactResellerSaleXL_CCI USE [AdventureworksDW2016CTP3] GO SET ANSI_PADDING ON GO ALTER TABLE [dbo].[FactResellerSalesXL] ADD CONSTRAINT [PK_FactResellerSalesXL_SalesOrderNumber_SalesOrderLineNumber] PRIMARY KEY CLUSTERED ( [SalesOrderNumber] ASC, [SalesOrderLineNumber] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO |
First, run the query with no existing columnstore index and only using the current clustered rowstore (normal) index. Note that I turned on SET STATISTICS IO and TIME on. These two SET statements will help better illustrate the improvements provided by the columnstore index. SET STATISTICS IO displays statistics on the amount of page activity generated by the query. It gives you important details such as page logical reads, physical reads, scans, and lob reads both physical and logical. SET STATISTICS TIME displays the amount of time needed to parse, compile, and execute each statement in the query. The output shows the time in milliseconds for each operation to complete. This allows you to really see, in numbers, the differences.
|
1 2 3 4 5 6 7 8 9 |
USE [AdventureworksDW2016CTP3] GO SET STATISTICS IO ON GO SET STATISTICS TIME ON; GO SELECT ProductKey, sum(SalesAmount) SalesAmount, sum(OrderQuantity) ct FROM dbo.FactResellerSalesXL GROUP BY ProductKey |
Looking at the results below, it completed five scans, 318,076 logical reads, two physical reads and read-aheads 291,341. It also shows a CPU Time of 8233 milliseconds (ms) and elapsed time of 5008 ms. The optimizer chooses to scan the existing rowstore clustered index with a cost of 91% and scanned the entire 11.6 million records to return the 395 record result set.

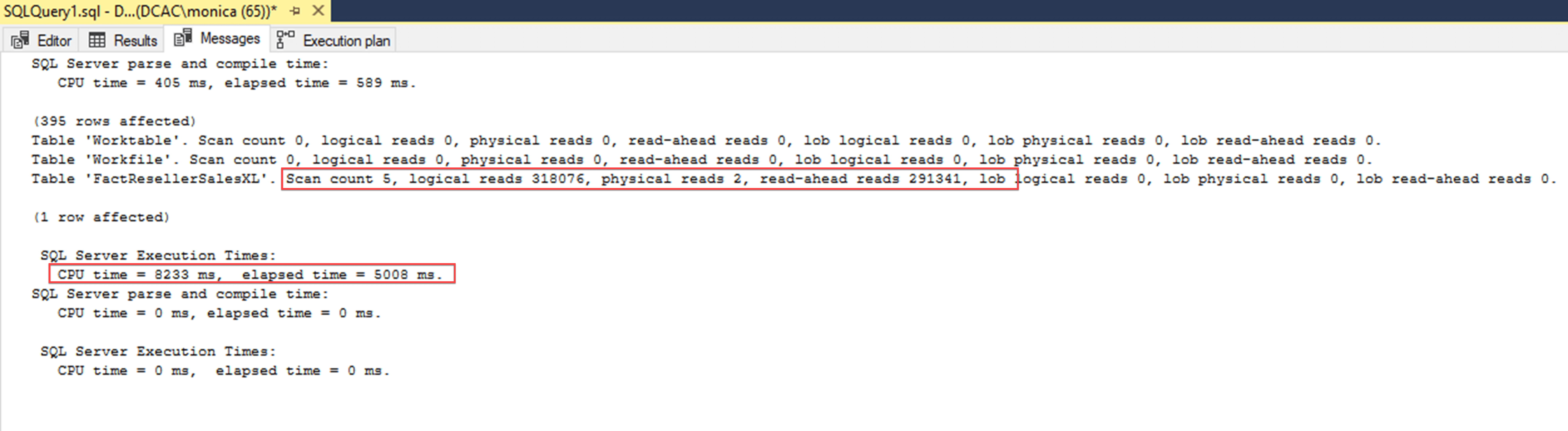
Another thing worth noting is if you hover over the Clustered Index scan you can see that the storage of this index is Row and the Actual Execution Mode is also Row.
Now create the Columnstore index on this table. Using the GUI right-click on indexes and choose New Index then Clustered Columnstore Index.
Under the General table, all you need to do is name the index. If there are any objects in the table that are not compatible, you will see them listed in the highlighted section below. There are many limitations and exceptions to columnstore indexes such as specific data types like text, ntext and image, and features like sparse columns. To best see the full list of limitations take a look at the docs Microsoft provides here.
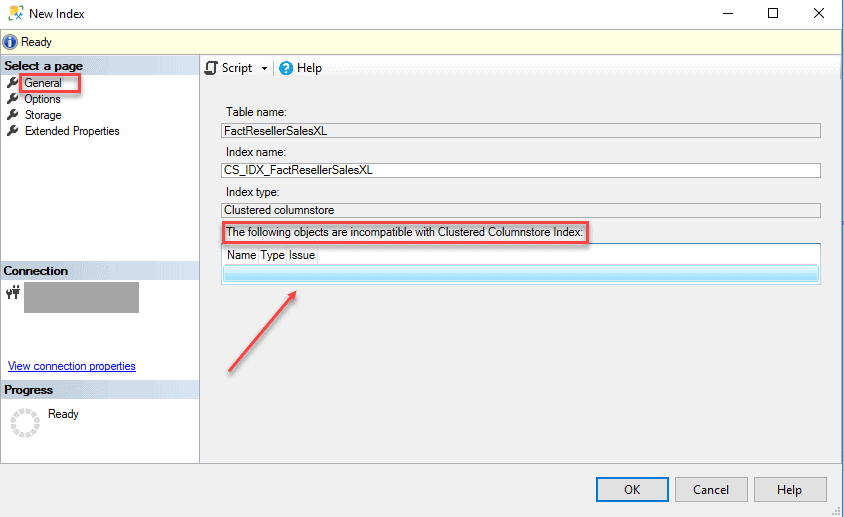
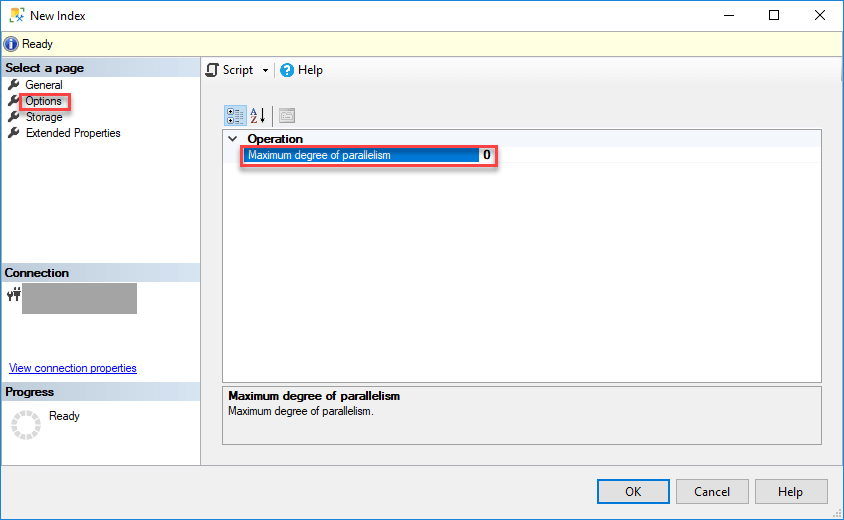
Because of the compression involved, creating a columnstore index can be very CPU resource intensive. To help mitigate that, SQL Server provides an option, under the Options tab, to overwrite the current MaxDop server setting for the parallel build process. This is something you want to consider while creating a columnstore index in a production environment. For this example, leave the default. On the other hand, if you are building this index during downtime, you should note that columnstore operations scale linearly in performance all the way up to a MaxDOP of 64, and this can help the index build process finish faster at the expense of overall concurrency.
Per docs.microsoft
max_degree_of_parallelism values can be:
- 1 – Suppress parallel plan generation.
- >1 – Restrict the maximum number of processors used in a parallel index operation to the specified number or fewer based on the current system workload. For example, when MAXDOP = 4, the number of processors used is 4 or less.
- 0 (default) – Use the actual number of processors or fewer based on the current system workload.
If you click OK to create the index, you’ll get an error which I explain below. If you choose to script this out, you will get the below T SQL create statement.
|
1 2 3 4 5 6 |
USE [AdventureworksDW2016CTP3] GO CREATE CLUSTERED COLUMNSTORE INDEX [CS_IDX_FactResellerSalesXL] ON [dbo].[FactResellerSalesXL] WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0) GO |
When you run this statement, you will get an error which states the index could not be created because you cannot create more than one clustered index on a table at a time.
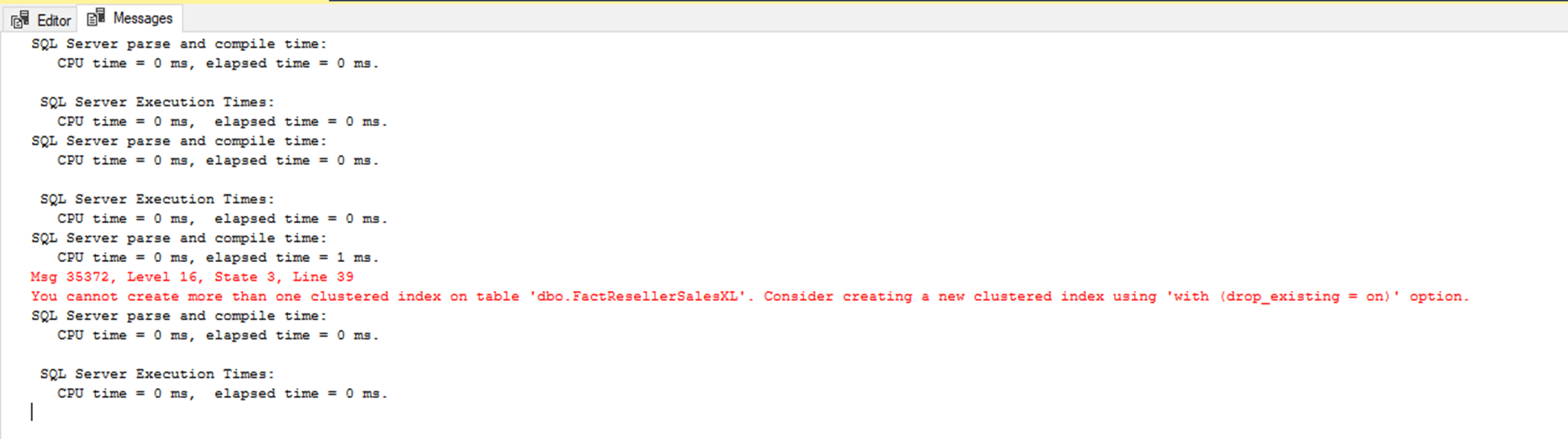
I did this on purpose to illustrate that you can only have one clustered index on a table regardless if you have columnstore or row store indexes on the table. You can change the DROP_EXISTING = ON to remove the row store clustered index and replace it with the columnstore. Moreover, you have the option to create a non-clustered columnstore index instead or add traditional non-clustered indexes. (Note: You can only add one columnstore index per table.) This option is typically used when most of the queries against a table return large aggregations, but another subset does a lookup by a specific value. Adding additional non-clustered index will dramatically increase your data loading times for the table.
However, to keep things simple, you will note that the AdventureWorksDW2016CTP3 database also has a table called dbo.FactResellerSalesXL_CCI which already has a clustered columnstore index created. By scripting that out, you can see it looks exactly like the one you tried to create. Instead, use this table which is identical to the FactResellerSalesXL table minus the columnstore index difference.
|
1 2 3 4 5 6 |
USE [AdventureworksDW2016CTP3] GO CREATE CLUSTERED COLUMNSTORE INDEX [IndFactResellerSalesXL_CCI] ON [dbo].[FactResellerSalesXL_CCI] WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0) ON [PRIMARY] GO |
Now getting back to the original query, run the same statement against the columnstore indexed table that also has the 11.6 million rows.
|
1 2 3 4 5 6 7 8 9 |
USE AdventureWorksDW2016CTP3; GO SET STATISTICS IO ON GO SET STATISTICS TIME ON; GO SELECT ProductKey, sum(SalesAmount) SalesAmount, sum(OrderQuantity) ct FROM dbo.FactResellerSalesXL_CCI GROUP BY ProductKey |
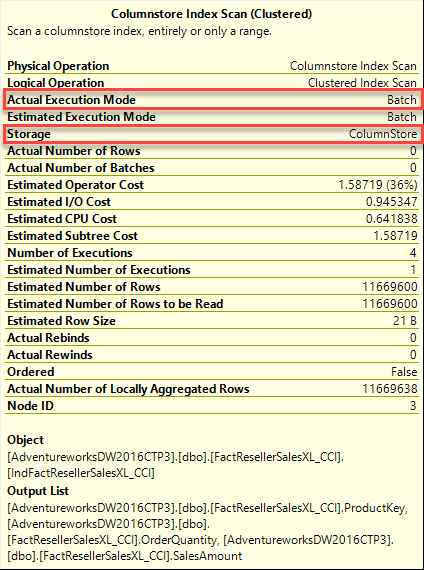
Taking a look at the execution plan first. Easily, you can see the optimizer went from eight operators to only five operators to complete the transaction and you can see it did an index scan of the clustered columnstore index but this time at a cost of only 36% and read zero of the 11.6 million records.

Next, take a look at the numbers. To see the difference clearer, I have both results for comparison below.
ROW STORE
COLUMNSTORE
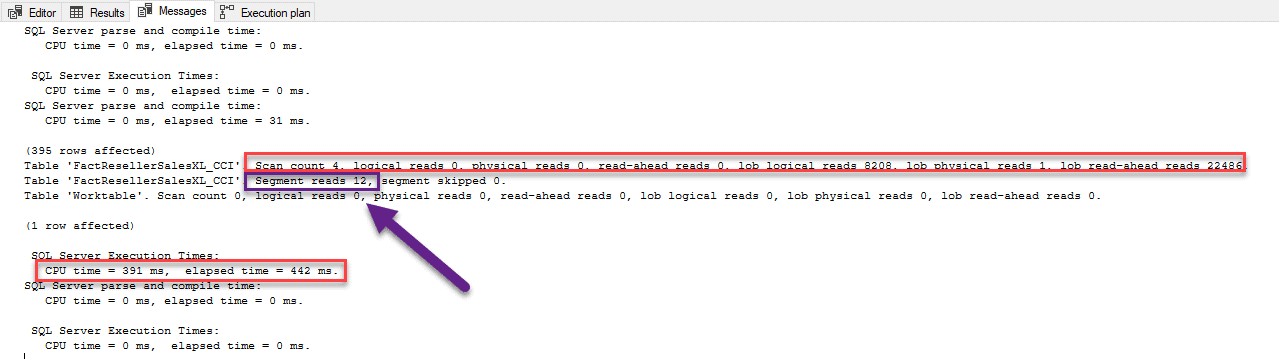
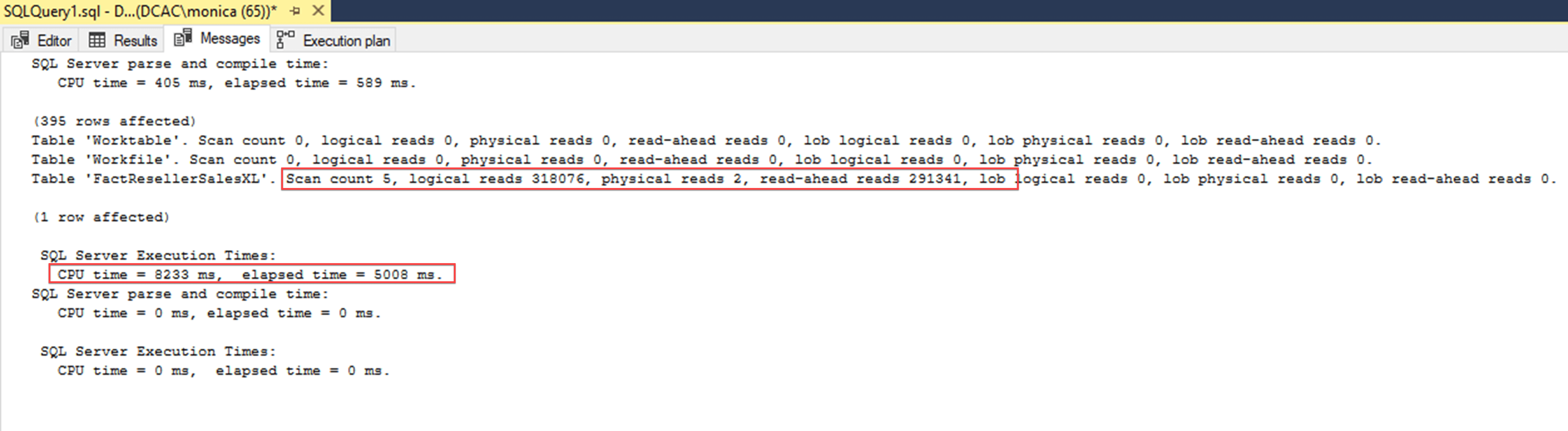
The columnstore results have a scan count of four, zero logical reads, zero physical reads, zero read-aheads and 22486 lob read-aheads and took less than a second to run. The reason why these lob activities are in the output is that SQL Server uses its native lob storage engine for the storage of the columnstore segments. There is also an additional cache for columnstore segments in SQL Server’s main memory that is separate from the buffer pool. The rowstore index shows significantly more reads. Lastly, note the additional table line, you will see Segments Reads =12. Remember, I discussed how columns are stored in column segments. This is where you can see that the optimizer read those segments.
You can also see that the columnstore indexed results took less time CPU time. The first one was 8233 ms with the elapsed time of 5008 ms while the second only took a CPU time 391 ms and elapsed time of 442ms. That is a HUGE gain in performance.
Remember earlier, that when using the rowstore index, the Actual Execution Mode was Row. Here, when using columnstore, it used Batch mode (boxed in red below). If you recall, batch mode allows the engine to process multiple rows at one time. This also makes the engine able to process rows extremely fast in some cases, giving two to four times the performance of a single query execution. As you can see, the aggregation example happened very quickly because only the rowa being aggregated are read into memory. Using the row groups, the engine can batch process the groups of 1 million rows. Thus, 12 segments read a little over 11.6 million rows.
When to Use Columnstore Indexes
Now with great power, comes great responsibility. Columnstore indexes are designed for large data warehouse workloads, not normal OLTP workload tables. Just because these indexes work efficiently doesn’t mean you should add them, be sure to research and test before introducing columnstore indexes into your environments.
As with any index design, it is important to know your data and what you will be using the data for. Be sure to look to what types of queries you will be running against it, as well as how the data is loaded and maintained. There are a few questions you should ask yourself before deciding to implement a columnstore index. Just because your table consist of millions of rows doesn’t mean columnstore is the right way to go.
First, you need to know the data
Is your table large enough to benefit? Usually, this means in the millions of records range as these rows are divided into groups of rows, called a rowgroup. A rowgroup has a minimum of 102,400 rows with a max of approximately 1 million rows. Each rowgroup is changed into column segments. Therefore, having a columnstore index on a table with under a 1 million rows does not make sense in that if the table is too small, you don’t get the benefits of compression that comes with the column segments. A general recommendation is to use columnstore indexes on the fact tables in your data warehouse, and on very large dimension tables, containing over 5 million rows.
Is your data volatile, meaning changing frequently? Rule of thumb says you want tables that rarely have data modifications, more specifically, where less than 10% of the rows are ever modified. Having large numbers of deletes can cause fragmentation, which adversely affects compression rates, thus reducing the efficiency of the index. Updates, in particular, are expensive, as they are processed as deletes followed by inserts, which will adversely affect the performance of your loading process.
What data types are in your table? There are several data types that are not supported within a columnstore index. Data types like varchar(max), nvarchar(max), or varbinary(max) were not supported until SQL Server 2017, and typically aren’t the best fit for this type of workload, especially since these will probably not compress well. Additionally, if you are using uniqueidentifiers (GUIDs) you won’t be able to create your index as they are still not supported.
Next, what are you doing in your queries?
Are you doing aggregations or performing analytics on the data, or are you looking for specific values? The standard B-tree rowstore indexes are best for singleton lookups (single values) and are sometimes used in tandem with a columnstore index. If you’re using an index to cover a where clause that does not look up a range of values and is just filling predicates, then columnstore does not benefit. This especially true if you need to “cover” that query with included columns since columnstore does not allow included columns. However, columnstore is designed to quickly process aggressions, especially on a grouped range of values. So, if you are performing aggregations or analytics, usually columnstore can give you substantial performance gains as it can do full table scans to perform aggregations very fast.
Now there are times where you want to seek a specific value and perform aggregations (think average sale price in the last quarter for a specific product). In these cases, you may benefit from a combination of a rowstore and columnstore index. Creating the columnstore to handle the grouping and aggregations and covering the index seek requirement with the rowstore. Adding these b-tree indexes will help your query performance, but they can dramatically impact the loading process—if your data loads are large enough, it may be more efficient to drop the b-tree index, and rebuild it after loading the data into the columnstore.
Is this a data warehouse fact or dimension table? As you know, a dimension table is usually used to find specific values, mostly lookups to match with an aggregated value from a fact table. If it’s a dimension table, typically you are going to use a b-tree based models, with the exception of very large dimensions. The best use case is to use columnstore on fact tables in the data warehouse as these tables are normally the source of aggregations.
Summary
Taking the intimidation out of columnstore is easy if you take the time to understand it. Hope this helped elevate some for yours. But remember, don’t just jump to columnstore indexes now that you have an understanding of them, and your tables are large. Make sure to take the time, just like with any design, to choose the right option for your usage and environment. Knowing your data is pivotal in deciding whether or not a columnstore index is best suited for your query needs.
Fast, reliable and consistent SQL Server development…
FAQs: Columnstore indexes in SQL Server
1. What is a columnstore index in SQL Server?
A columnstore index stores table data organized by column instead of by row. Data is divided into rowgroups (each containing up to ~1 million rows), and within each rowgroup, values for each column are compressed into segments. This column-oriented storage enables high compression ratios and fast analytical queries because SQL Server only reads the columns needed for a query, skipping the rest entirely.
2. When should you use a columnstore index vs. a rowstore index?
Use a columnstore index for large tables (millions+ rows) with analytical query patterns: aggregations, GROUP BY, scans across date ranges, and reporting workloads. Use rowstore (B-tree) indexes for transactional workloads: single-row lookups, frequent inserts/updates/deletes, and point queries. Data warehouse fact tables are the ideal columnstore candidate. Dimension tables typically work better with rowstore indexes unless they’re very large.
3. What is the difference between clustered and nonclustered columnstore indexes?
A clustered columnstore index (CCI) replaces the table’s row-based storage entirely – the table becomes a columnstore. A nonclustered columnstore index (NCCI) is an additional index on a rowstore table, providing analytical query performance while keeping the base table in row format for transactional operations. Use CCI for dedicated OLAP tables; use NCCI for hybrid OLTP/OLAP scenarios.
4. How much compression do columnstore indexes provide?
Columnstore indexes typically achieve 10:1 compression ratios compared to uncompressed rowstore tables, though this varies by data type and cardinality. Low-cardinality columns (like status codes or category IDs) compress better than high-cardinality columns (like GUIDs). Archive compression can further reduce storage at the cost of slightly slower decompression during queries.
Load comments